SAI #04: Data Contracts, Experimentation Environments and more ...
Data Contracts, Spark - Shuffle, Experimentation Environments, Model Observability - Real Time.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
Data Contracts.
Spark - Shuffle.
Experimentation Environments.
Model Observability - Real Time.
Data Engineering Fundamentals + or What Every Data Engineer Should Know
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀.
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 𝗵𝗼𝗹𝗱 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝗻𝗼𝗻-𝗲𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗹𝗶𝘀𝘁 𝗼𝗳 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮:
👉 Schema of the Data being Produced.
👉 Schema Version - Data Sources evolve, Producers have to ensure that it is possible to detect and react to schema changes. Consumers should be able to process Data with the old Schema.
👉 SLA metadata - Quality: is it meant for Production use? How late can the data arrive? How many missing values could be expected for certain fields in a given time period?
👉 Semantics - what entity does a given Data Point represent. Semantics, similar to schema, can evolve over time.
👉 Lineage - Data Owners, Intended Consumers.
👉 …
𝗦𝗼𝗺𝗲 𝗣𝘂𝗿𝗽𝗼𝘀𝗲𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
➡️ Improve Scalability of your Data Systems.
➡️ Reduce intermediate Data Handover Layer.
➡️ …
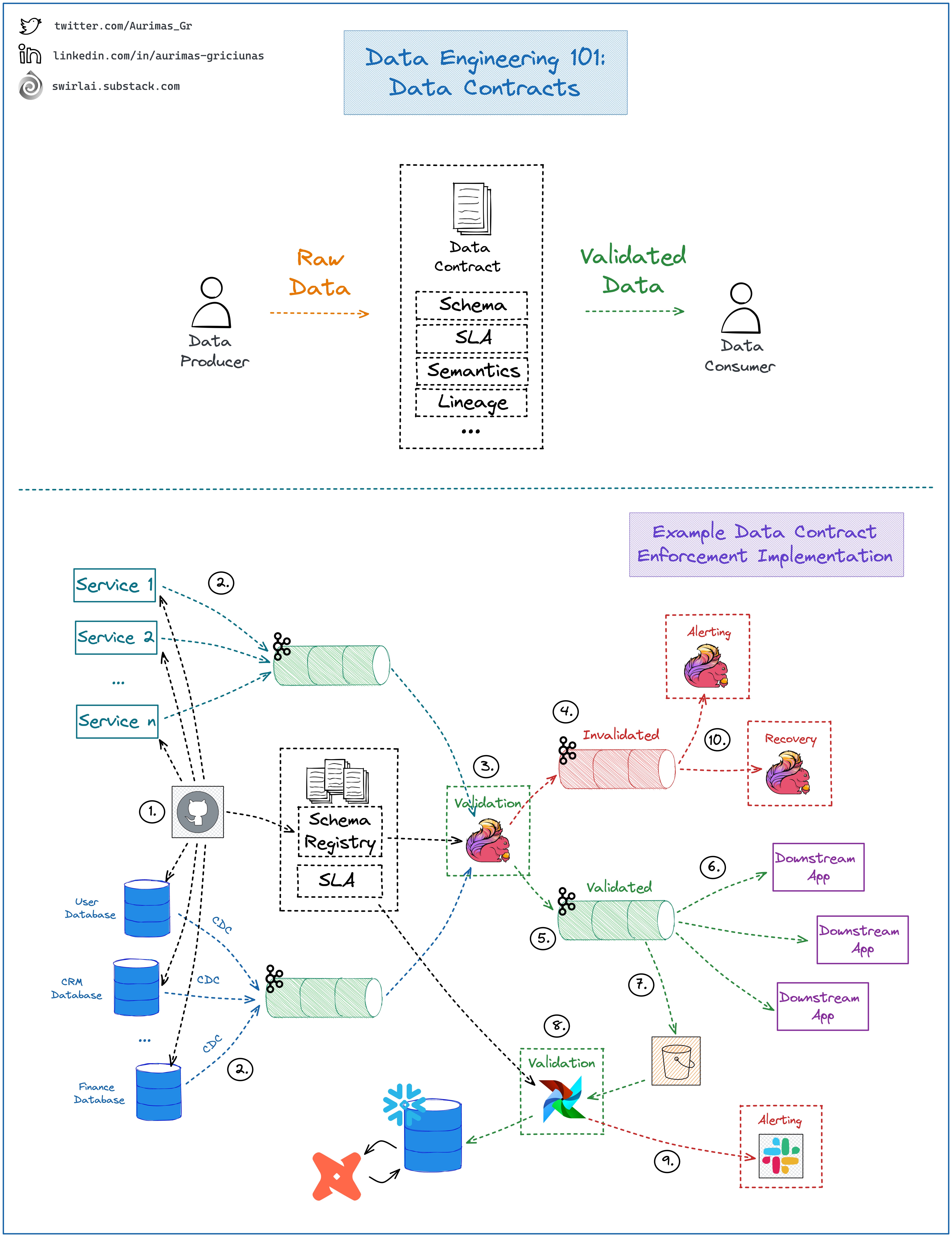
𝗘𝘅𝗮𝗺𝗽𝗹𝗲 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 𝗳𝗼𝗿 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝗘𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁:
1️⃣ Schema changes are implemented in a git repository, once approved - they are pushed to the Applications generating the Data and a central Schema Registry.
2️⃣ Applications push generated Data to Kafka Topics. Separate Raw Data Topics for CDC streams and Direct emission.
3️⃣ A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Schema Registry.
4️⃣ Data that does not meet the contract is pushed to Dead Letter Topic.
5️⃣ Data that meets the contract is pushed to Validated Data Topic.
6️⃣ Applications that need Real Time Data consume it directly from Validated Data Topic or its derivatives.
7️⃣ Data from the Validated Data Topic is pushed to object storage for additional Validation.
8️⃣ On a schedule Data in the Object Storage is validated against additional SLAs and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
9️⃣ Consumers and Producers are alerted to any SLA breaches.
🔟 Data that was Invalidated in Real Time is consumed by Flink Applications that alert on invalid schemas. There could be a recovery Flink Application with logic on how to fix invalidated Data.
𝗦𝗽𝗮𝗿𝗸 - 𝗦𝗵𝘂𝗳𝗳𝗹𝗲.
There are many things to take into consideration to improve Spark Application Performance. We will talk about all of them - today is about Shuffle.
𝗦𝗼𝗺𝗲 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
➡️ Spark Jobs are executed against Data Partitions.
➡️ Each Spark Task is connected to a single Partition.
➡️ Data Partitions are immutable - this helps with disaster recovery in Big Data applications.
➡️ After each Transformation - number of Child Partitions will be created.
➡️ Each Child Partition will be derived from one or more Parent Partitions and will act as Parent Partition for future Transformations.
➡️ Shuffle is a procedure when creation of Child Partitions involves data movement between Data Containers and Spark Executors over the network.
➡️ There are two types of Transformations:
𝗡𝗮𝗿𝗿𝗼𝘄 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻𝘀
➡️ These are simple transformations that can be applied locally without moving Data between Data Containers.
➡️ Locality is made possible due to cross-record context not being needed for the Transformation logic.
➡️ E.g. a simple filter function only needs to know the value of a given record.
𝘍𝘶𝘯𝘤𝘵𝘪𝘰𝘯𝘴 𝘵𝘩𝘢𝘵 𝘵𝘳𝘪𝘨𝘨𝘦𝘳 𝘕𝘢𝘳𝘳𝘰𝘸 𝘛𝘳𝘢𝘯𝘴𝘧𝘰𝘳𝘮𝘢𝘵𝘪𝘰𝘯𝘴
👉 map()
👉 mapPartition()
👉 flatMap()
👉 filter()
👉 union()
👉 contains()
👉 …
𝗪𝗶𝗱𝗲 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻𝘀
➡️ These are complicated transformations that trigger Data movement between Data Containers.
➡️ This movement of Data is necessary due to cross-record dependencies for a given Transformation type.
➡️ E.g. a groupBy function followed by sum needs to have all records that contain a specific key in the groupBy column locally. This triggers the shuffle.
𝘍𝘶𝘯𝘤𝘵𝘪𝘰𝘯𝘴 𝘵𝘩𝘢𝘵 𝘵𝘳𝘪𝘨𝘨𝘦𝘳 𝘞𝘪𝘥𝘦 𝘛𝘳𝘢𝘯𝘴𝘧𝘰𝘳𝘮𝘢𝘵𝘪𝘰𝘯𝘴
👉 groupByKey()
👉 aggregateByKey()
👉 groupBy()
👉 aggregate()
👉 join()
👉 repartition()
👉 …
[𝗜𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁]
❗️Shuffle is an expensive operation as it requires movement of Data through the Network.
❗️Shuffle procedure also impacts disk I/O since shuffled Data is saved to Disk.
❗️Tune your applications to have as little Shuffle Operations as possible.
𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝘀𝗵𝘂𝗳𝗳𝗹𝗲.𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀
✅ If Shuffle is necessary - use 𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝘀𝗵𝘂𝗳𝗳𝗹𝗲.𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀 configuration to tune the number of partitions created after shuffle (defaults to 200).
✅ It is good idea to consider the number of cores your cluster will be working with. Rule of thumb could be having partition numbers set to one or two times more than available cores.

MLOps Fundamentals or What Every Machine Learning Engineer Should Know
𝗘𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 𝗘𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁.
Effective ML Experimentation Environments are key to your MLOps transformation success.
At the center of this environment sits a Notebook. In the MLOps context the most important parts are the integration points between the Notebook and the remaining MLOps ecosystem. Most critical being:
1️⃣ 𝗔𝗰𝗰𝗲𝘀𝘀 𝘁𝗼 𝗥𝗮𝘄 𝗗𝗮𝘁𝗮: Data Scientists need access to raw data to uncover new Features that could be moved downstream into a Curated Data Layer.
2️⃣ 𝗔𝗰𝗰𝗲𝘀𝘀 𝘁𝗼 𝗖𝘂𝗿𝗮𝘁𝗲𝗱 𝗗𝗮𝘁𝗮: Here the data is curated, meeting SLAs and of the highest quality. The only remaining step is to move it to the Feature Store. If it is not there yet - Data Scientists need to know of available Data Sets.
3️⃣ 𝗔𝗰𝗰𝗲𝘀𝘀 𝘁𝗼 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗦𝘁𝗼𝗿𝗲: Last step for data quality and preparation. Features are ready to be used for Model training as is - always start here, only move upstream when you need additional data.
4️⃣ 𝗘𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁/𝗠𝗼𝗱𝗲𝗹 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺: Data Scientists should be able to run local ML Pipelines and output Experiment related metadata to Experiment/Model Tracking System directly from Notebooks.
5️⃣ 𝗥𝗲𝗺𝗼𝘁𝗲 𝗠𝗟 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀: Machine Learning Pipeline development should be extremely easy for the Data Scientist, that means being able to spin up a full fledged Pipeline from their Notebook.
6️⃣ 𝗩𝗲𝗿𝘀𝗶𝗼𝗻 𝗖𝗼𝗻𝘁𝗿𝗼𝗹: Notebooks should be part of your Git integration. There are challenges with Notebook versioning but it does not change the fact. Additionally, it is best for the notebooks to live next to the production project code in template repositories. Having said that - you should make it crystal clear where certain type of code should live - a popular way to do this is providing repository 𝘁𝗲𝗺𝗽𝗹𝗮𝘁𝗲𝘀 with clear documentation.
7️⃣ 𝗥𝘂𝗻𝘁𝗶𝗺𝗲 𝗘𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁: Notebooks have to be running in the same environment that your production code will run in. Incompatible dependencies should not cause any problems when porting applications to production. There might be several Production Environments so it should be easy to swap it for Notebook. It can be achieved by running Notebooks in containers.
8️⃣ 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗖𝗹𝘂𝘀𝘁𝗲𝗿𝘀: Data Scientists should be able to easily spin up different types of compute clusters - might it be Spark, Dask or any other technology - to allow effective Raw Data exploration.

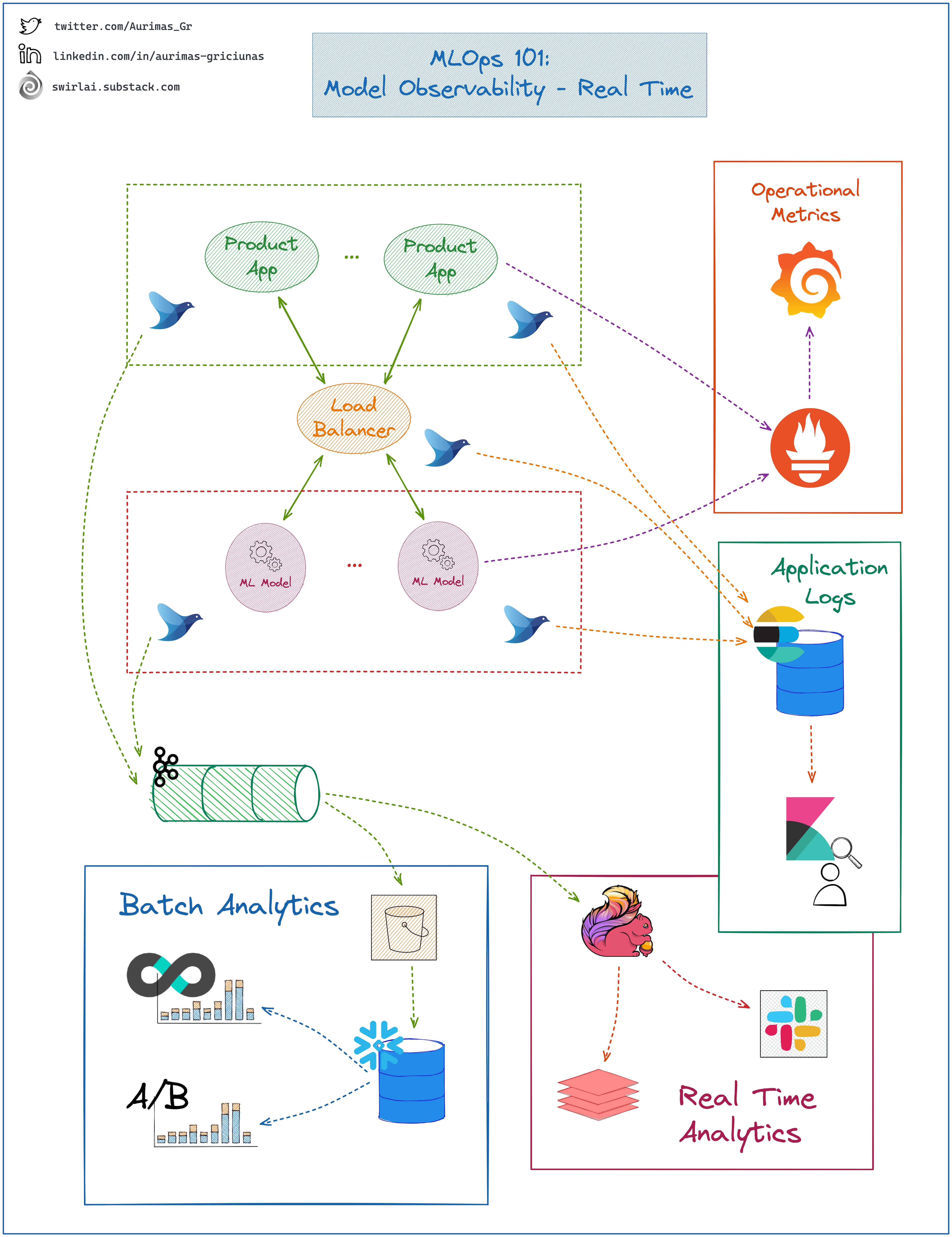
𝗠𝗼𝗱𝗲𝗹 𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝗯𝗶𝗹𝗶𝘁𝘆 - 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲.
Your Machine Learning Systems can fail in more ways than regular software. Machine Learning Observability System is where you will continuously monitor ML Application Health and Performance.
There are end-to-end platforms that try to provide all of the later described capabilities, we will look into how an in-house built system could look as the concepts will be fundamentally similar.
To provide a holistic view of your Machine Learning Model Health in Production - Observability System needs at least:
𝗢𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗠𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴:
➡️ Here you monitor regular software operational metrics.
➡️ This would include response latency, inference latency of your ML Services, how many requests per second are made etc.
𝘌𝘹𝘢𝘮𝘱𝘭𝘦 𝘴𝘵𝘢𝘤𝘬:
👉 Prometheus for storing Metrics and alerting.
👉 Grafana mounted on Prometheus for exploring metrics.
𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻 𝗟𝗼𝗴𝗴𝗶𝗻𝗴:
➡️ As in any regular software system you will need to collect your application logs centrally.
➡️ This would include errors, response codes, debug logs if there is a need to dig deeper.
𝘌𝘹𝘢𝘮𝘱𝘭𝘦 𝘴𝘵𝘢𝘤𝘬:
👉 fluentD Sidecars forwarding logs to ElasticSearch clusters.
👉 Kibana mounted on ElasticSearch for log search and exploration.
𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗟𝗼𝗴𝘀:
This is a key area to Machine Learning Observability. You track Analytical Logs of your Applications - both Product Applications and your Machine Learning Service. These Logs will include application specific data like:
➡️ What prediction was made by ML Service.
➡️ What action was performed by the Product Application after receiving the Inference result.
➡️ What was the feature input to the ML Service.
➡️ …
➡️ Some of the features for inference will still be calculated on the fly due to latency requirements. Here you can identify any remaining Training/Serving Skew.
➡️ You will be able to monitor business related metrics. Click Through Rate, Revenue Per User etc.
➡️ You will catch any Data or Concept Drift happening within your online systems.
𝘌𝘹𝘢𝘮𝘱𝘭𝘦 𝘴𝘵𝘢𝘤𝘬:
👉 fluentD Sidecars forwarding logs to a Kafka Topic.
𝘉𝘢𝘵𝘤𝘩:
👉 Data is written to object storage and later to a Data Warehouse.
👉 A/B Testing Systems and BI Tooling are mounted on the Data Warehouse for Analytical purposes.
𝘙𝘦𝘢𝘭 𝘛𝘪𝘮𝘦:
👉 Flink Cluster reads Data from Kafka, performs windowed Transformations and Aggregations and either Alerts on thresholds or Forwards the data to Low Latency Read capable storage.