
A Guide to Optimising your Spark Application Performance (Part 2)
A cheat sheet to refer to when you run into performance issues with your Spark application.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This is the second part of my Spark Application Optimisation Guide. If you missed the first one, be sure to check it out here. There I covered:
Spark Architecture.
Wide vs. Narrow Transformations.
Broadcast Joins
Maximising Parallelism.
Partitioning.
Bucketing.
Caching.
Today I cover optimisations that you should consider that are related to Data Storage and Infrastructure:
Choosing the right File Format.
Column-Based vs. Row-Based storage
Splittable vs. non-splittable files
Encoding in Parquet.
RLE (Run Length Encoding)
Dictionary Encoding
Combining RLE and Dictionary Encoding
Understanding and tuning Spark Executor Memory.
Maximising the number of executors for a given cluster.
Memory allocation.
CPU allocation.
In the third part of Spark related articles coming out in few weeks I am planning to cover some of the following topics (I will be doing a poll where paid subscribers will be able to participate in choosing a subset of the topics):
Window functions.
UDFs.
Inferring Schema.
What happens when you Sort in Spark?
Connecting to Databases.
Compression of Files.
Spark UI.
Current state of Spark Cluster deployment.
Spark 3.x improvements.
Spark Driver.
Introduction to Spark Streaming.
Deploying Spark on Kubernetes.
Upstream data preparation for Spark Job input files.
Spark for Machine Learning.
….
Let’s jump to today’s topics.
Choosing the right File Format.
When using Spark you will most likely interact with the data that resides in your Data Lake (or a Streaming Storage when Spark Streaming is being used). Today we focus on Batch Processing, let’s look into Storage of data in the Data Lake.
Let’s first focus on how data can be organised when stored on disk and then on the properties of parallelism of the stored data at read time. First is related to Column and Row Based storage while the latter is related to splittable and non-splittable files.
Column vs. Row Based storage.
There are mainly 4 behaviours of data stored in a single file you need to consider when choosing between Column or Row-based storage.
How is the data organised on disk.
How effective is the write operation of writing a single record/row.
How effective is the read operation when reading partial data (subset of columns).
How well can we compress the data when writing to disk.
Let’s look into how Column and Row Based storage matches against each other in these 4 areas.
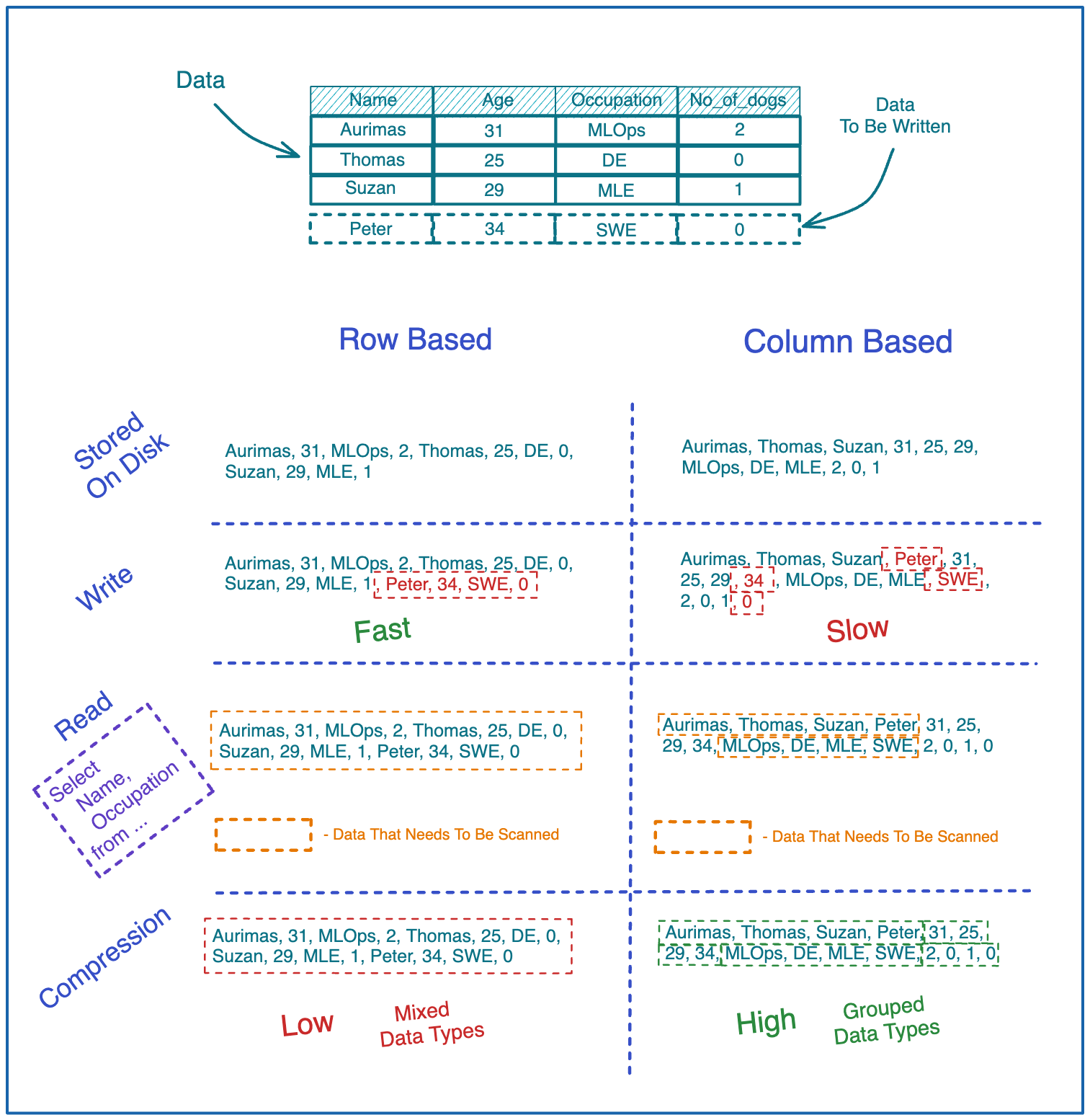
Row Based:
Rows on disk are stored in sequence.
New rows are written efficiently since you can write the entire row at once.
For select statements that target a subset of columns, reading is slower since you need to scan all sets of rows to retrieve one of the columns.
Compression is not efficient if columns have different data types since different data types are scattered all around the file.
Column Based:
Columns on disk are stored in sequence.
New rows are written slowly since you need to write separate fields of a row into different parts of the file.
For select statements that target a subset of columns, reads are faster than row based storage since you don’t need to scan the entire file (given that metadata about where specific columns begin is present when performing the read).
Compression is efficient since different data types are always grouped together.
Example file formats:
Row Based: Avro.
Column Based: Parquet, ORC.
Tips.
If the main use case for Spark is OLAP - use Parquet or ORC.
If the main use case is about frequently writing data (OLTP) - use Avro.
Splittable vs. non-splittable files.
When using Spark it is very likely that the data you would be reading will reside in a distributed storage. It could be HDFS, S3 etc.
Spark utilizes multiple CPU Cores for loading data (refer to this piece for more information) and performing distributed computation in parallel.
On top of choosing Column or Row Based storage, you have to make sure that data in the same file can be read in parallel by multiple cores (this is important when the files start getting bigger). This is where partitioning and Splittable files come into play.
What do you need to know about splittable files and the storage that is used to store them?
Splittable Files are Files that can be partially read by several processes at the same time.
In distributed file or block storages files are stored in chunks called blocks.
Block sizes will vary between different storage systems.
If your file is non-splittable and is of a bigger size than a block in storage - it will be split between blocks but can only be read by a Single CPU Core which might cause Idle CPU time (1.).
If your file is Splittable (3.), multiple cores can read it at the same time (one core per block).
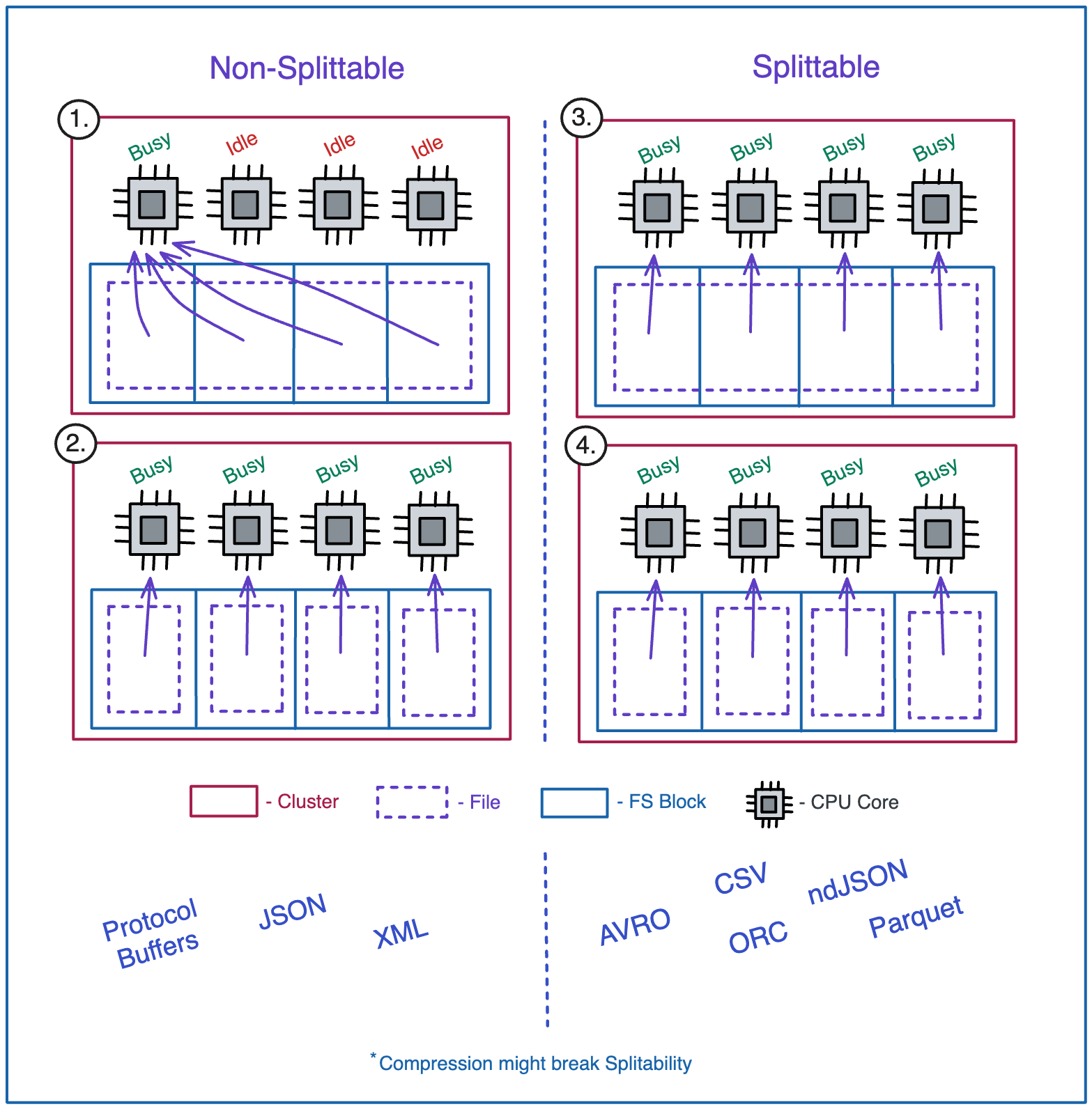
Splittable file formats:
Avro.
CSV.
ORC.
ndJSON.
Parquet.
Non-Splittable file formats:
Protocol Buffers.
JSON.
XML.
Tips.
If possible - prefer Splittable File types.
If you are forced to use Non-Splittable files, manually partition them into sizes that would fit into a single FS Block to utilize more CPU Cores when reading (2.).
Compression might break splitability. For this episode it is enough to know that .snappy compression on Parquet does not break splitability.
Parquet is the default file format for Spark and it provides the desired properties necessary for an efficient OLAP environment - Columnar Storage and Splitability. ORC is often benchmarked as having almost the same efficiency, but it is a good practice to use it only when you are working with Hive.
Encoding in Parquet.
We established that when it comes to Big Data and read intensive OLAP workloads - Parquet is the best file format to be used together with Spark. There is one important aspect of Parquet files that sometimes goes unnoticed as it gets implemented for you automatically but needs some deeper understanding to be utilised to its fullest.
I am talking about encoding of the data that is happening under the hood. There are multiple types of encoding in Parquet but today I will talk about two of them.
Run Length Encoding (RLE).
Dictionary Encoding.
Run Length Encoding (RLE)
These are the steps performed by Run Length Encoding (RLE):
Table columns are scanned for sequences of repeated values.
Sequence of repeated values is transformed into object containing two values:
Number of times the value was repeated sequentially.
The value itself.
The column is then transformed into a sequence of these two value objects.

When does it make sense to use Run Length Encoding (RLE)?
The data in the columns are ordered.
The data is of low enough cardinality.
Given a most extreme case when all of the values in a column are unique, this encoding approach would increase the storage needed as there would be a new entry created in the column for each row in the column.
Additional benefits of Run Length Encoding:
The compression achieved can be significant given a low cardinality nature of the column.
In the most extreme case where the column only has a single unique value, you would only need to write two values after the encoding - the number of times the value repeats and the value itself.
Dictionary Encoding
These are the steps taken by Dictionary Encoding:
Each of the distinct values per column are extracted into a dictionary (lookup table) and given a numerical index.
Initial values in the column are replaced by these indexes and are later mapped via the lookup dictionary.

When does it make sense to use Dictionary Encoding?
The data in the column is of low enough cardinality.
Given a most extreme case when all of the values in a column are unique, this encoding approach would increase the storage needed as the dictionary would map to each value one-to-one. Consequently we would add the index values two times (one in the Column itself and one in the dictionary).
Additional benefits of Dictionary Encoding:
Ordering of the values is not important.
All data types can be encoded for efficient file size reduction.
Combining Dictionary and RLE Encodings.
Given the ideal scenario when the data is fully ordered in each column, it would not make sense to use anything other than RLE, however this is never the case in the real world as you will have to order the column sequentially which will reduce the orderliness of values each time we sort.
This is why it is extremely beneficial to combine both Dictionary and RLE encodings sequentially.
These are the steps taken in this case:
Apply dictionary encoding on the column.
Apply RLE encoding on the resulting column using the index values in the column that was the result of the previous step.
When does it make sense to combine Dictionary and RLE encodings?
The data in the column is both well ordered and of low enough cardinality.
Given a most extreme case when all of the values in a column are unique, this combination of encoding procedures would increase the storage needed as there would be a new entry created in the column for each row in the column and an additional dictionary entry per original value.
Tips.
Encoding in Parquet is write time optimisation that is utilised when reading and processing data downstream.
Spark implements encoding techniques automatically and out of the box when writing data via Spark - if there is no gain from applying one of the encoding techniques, it is skipped.
You need to correctly order the data for the encodings to produce good compression results.
Let’s understand how we should prepare the data before writing it to parquet:
The techniques work best for ordered columns of low cardinality.
We are very likely to be performing some sort of partitioning when writing parquet.
You will want for the ordering to be persisted after the data is partitioned.
Here is how you take advantage of previous information:
First sort your Spark Dataframes by the columns you will be partitioning by.
Then, in the same .sort() or .orderBy() call include remaining columns you would like to utilize by encoding in the increasing order of cardinality.
Understanding and tuning Spark Executor Memory.
Changing Spark Executor Memory configuration is not something you would do daily and will most likely be the last step you would be taking to improve your Application Performance.
Nevertheless, it is important to understand it if you want to successfully troubleshoot Out Of Memory issues and understand why certain optimisations that you did in your application code do not seem to work as expected.
The Executor Memory structure.
First of all, the entire memory container (JVM Heap Memory) is defined by a well known and widely used property spark.executor.memory. It defines combined memory available for the segments that compose Executors memory.
There are four major segments that comprise Spark Executor memory.

Reserved Memory.
This is set to 300MB by default.
You can’t change it unless you recompile Spark.
It is used to store Spark internal components
spark.executor.memory can’t be less than 1.5 times Reserved Memory.
User Memory.
It is equal to (JVM Heap Memory - Reserved Memory) * (1 - spark.memory.fraction).
spark.memory.fraction defaults to 0.75.
It is used to store user defined structures like UDFs.
Spark (Unified) memory.
It is equal to (JVM Heap Memory - Reserved Memory) * spark.memory.fraction.
This segment is further split into two parts.
Storage Memory.
It is equal to (Spark (Unified) Memory) * spark.memory.storageFraction
spark.memory.storageFraction defaults to 0.5
It is used to store any Cached or Broadcasted Data if it is configured to be done In Memory.
Execution Memory.
It is equal to (Spark (Unified) Memory) * (1 - spark.memory.storageFraction)
It is used to store any intermediate Data created by execution of Spark Jobs.
Tips.
You manipulate the entire storage distribution by changing two configurations spark.memory.fraction and spark.memory.storageFraction.
Even if set specifically, the boundary between Storage and Execution memory is flexible.
Execution Memory can always borrow memory from storage fraction.
Storage Memory can only borrow from Execution if it is not occupied.
If Execution Memory has borrowed from storage - Storage Memory can only reclaim it after it was released by Execution.
Execution Memory can forcefully evict data from Storage Memory and claim it for itself.
Knowing previous, there is not much point to change distribution of Spark (Unified) Memory.
The largest win of getting more memory for processing out of your executors is by lowering User Memory fraction.
Maximising the number of executors for a given cluster.
Now we know the structure of Spark Executors Memory, let’s explore how to utilise the resources of your Spark cluster to the last drop.
Remember that Executors of Spark isolate only the amount of memory defined by the spark.executor.memory configuration. This also means that if executors running on the cluster do not occupy a large fraction of the cluster's memory - it gets wasted and you are in the bigger risk of running into OOM errors just because of the poor configuration. There are also nuances you should consider when it comes to the CPU core utilisation as well.
Having said this, if you are sharing the cluster between multiple applications, there is less risk of under-utilisation of resources. However, nowadays it is a more common practice to run Spark applications on dedicated ephemeral clusters (a single cluster per application) that are running only while the application is being executed.
Spark can run on different resource managers like YARN or Kubernetes, both have their own nuances. For today’s examples I will be referring to EMR (which is AWS managed on-demand Hadoop cluster) which uses YARN under the hood to run Spark jobs.
As mentioned before there are two key concepts to consider when trying to maximize Cluster utilisation:
Memory allocation.
CPU allocation.
Memory allocation.
Let’s use m5.4xlarge as an example worker node for our EMR cluster. According to AWS here, it has 64 GiB of total memory and 16 vCPUs that you can use.
An important aspect of an EMR cluster and YARN in general is that there is only a limited amount of memory per cluster node that is dedicated for allocation to Spark processes such as Executor or Driver. This is something that Spark Practitioners tend to miss when optimising for cluster resource utilisation. This amount is set in the yarn-site.xml file via yarn.nodemanager.resource.memory-mb property.
Defaults for EMR can be found here. Default for m5.4xlarge instance type is 57344 MiB and this is the amount of memory out of 64 GiB we can allocate to our executors per node.

Let’s now take a concrete example to see what inefficiencies might arise due to poor configuration.
Our cluster is composed of a single Node.
We set num.executors to 6.
We set spark.executor.memory to 10g

The outcome:
We will be able to schedule only 5 executors.
6 * 10 GiB > 57344 MiB > 5 * 10 GiB.
5 Executors get scheduled, we do not utilize the orange part of the cluster memory.
The bigger the executors, the higher the loss on under-utilised memory. Let’s see:
Our cluster is composed of a single Node.
We set num.executors to 4.
We set spark.executor.memory to 15g
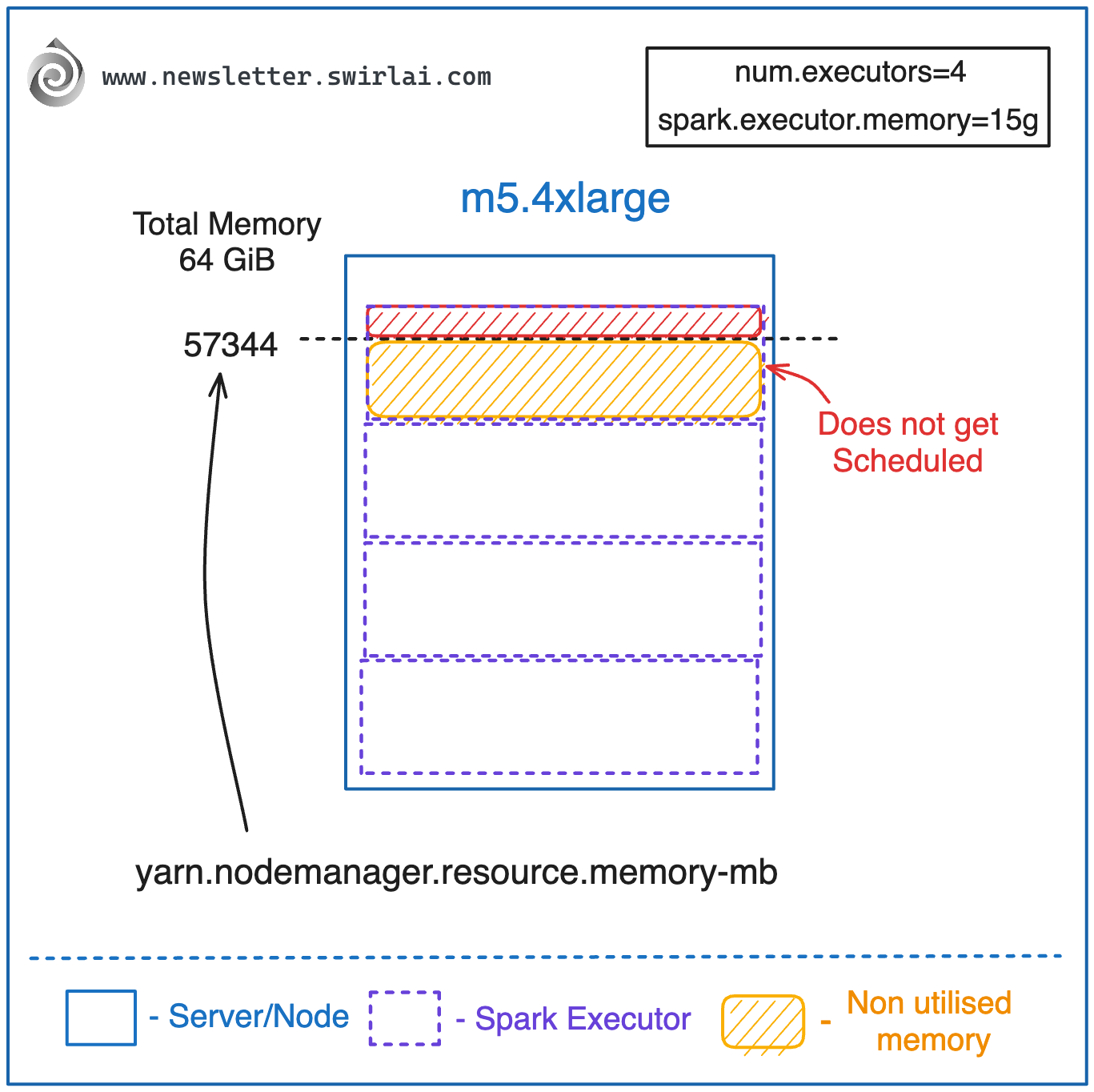
The outcome:
We will be able to schedule only 3 executors.
4 * 10 GiB > 57344 MiB > 3 * 10 GiB.
3 Executors get scheduled, we do not utilize the orange part of the cluster memory.
As we scale, the losses combine. Let’s say:
Our cluster is composed of 3 Nodes.
We set num.executors to 12.
We set spark.executor.memory to 15g

The outcome:
We will be able to schedule only 9 executors - 3 per node.
4 * 10 GiB > 57344 MiB > 3 * 10 GiB.
9 Executors get scheduled, we do not utilize the orange part of the cluster memory.
Tips.
If you are running Spark jobs on EMR or YARN in general and you run a single application per cluster, try to allocate most of yarn.nodemanager.resource.memory-mb to the executors.
Use yarn.nodemanager.resource.memory-mb / num.executors as a starting point for setting spark.executor.memory and see if the expected number of executors get started.
If you are running on Cluster Mode, Spark Driver will also be running on one of the executors, you will have to take this into account (more on it in the future episodes).
In the Spark UI you will only see Spark (Unified) Memory displayed as available for your executors so do not be afraid that it is not equal to spark.executor.memory.
CPU allocation.
CPU allocation ties very closely with memory allocation. Remember from here that cores per executor define the level of parallelism that spark can achieve so maximising it is as important for application performance as maximising memory allocation is for trying to avoid OOM situations.
The difference between available CPU to be allocated and Memory to be allocated is that you can allocate all available node cores to Spark Executors. In our m5.4xlarge example it is 16 cores.

Take this information with caution!
Best practices dictate that you should leave at least one core to system processes and utilize only the remaining for Spark Executors.
As discussed in the Part 1 of the Spark Application Optimisation Guide, going with more than 5 cores per executor imposes bottlenecks so I always try to stay below 5.
Let’s look into a good example.
We have 16 cores available.
We set num.executors to 5.
We set spark.executor.cores to 3.
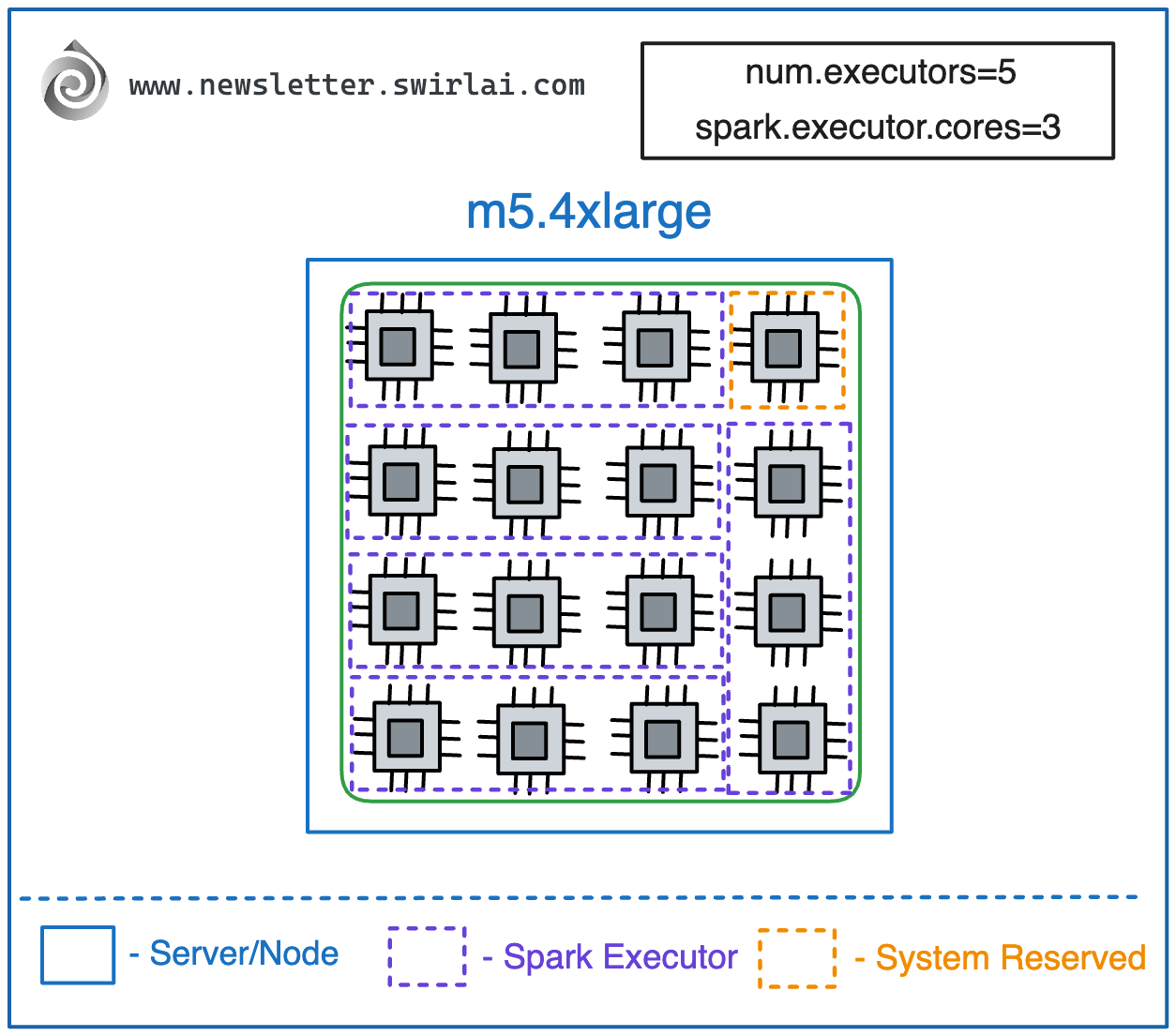
The output:
15 cores out of 16 get allocated to Spark.
1 core is allocated to system processes.
We have less than 5 cores per executor.
Few additional thoughts:
We did not choose 4 cores per executor because the only viable choice would be to go with 3 executors which would conclude with 4 cores dedicated to system processes which is too much.
We did not go with 5 because that might be imposing some I/O bottlenecks. Probably not (because only above 5 does on paper), but just for safety reasons.
We could set spark.executor.memory to 57344 MiB / 5.
That’s it for this week. Thank you for reading and hope to see you next week!
Your knowledge and series about Spark is wonderful. It helps DE who is struggling to optimize jobs a lot.
Thank you so much
Please write more about SparkUI and how to comprehensively understand about job status via shown metrics.
Hi , should I be worried about spill