
Breaking Down Context Engineering
All you ned to know about the challenges surrounding the practice.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in AI Engineering, Data Engineering, Machine Learning and overall Data space.
The topic that has been dominating headlines in AI Agent world for the past months - Context Engineering. In this article I will outline my thoughts on the topic and what I have observed while building Agentic Systems for the past few years. Also, we will look closer into all types of Context that Agentic Systems rely on and the challenges that come with managing it.
For Engineers who have been building AI Agents, Context Engineering is a new name but not a new practice - it is how we forced Agents to perform the work we expect to be done in the first place. When many were positioning Prompt Engineering as the hottest carrier path in the upcoming years I was not surprised, to me, the “old school” Prompt Engineering is a subset of Context Engineering.

What is Context Engineering and why it is important.
Let’s quickly remember what an Agentic System is.
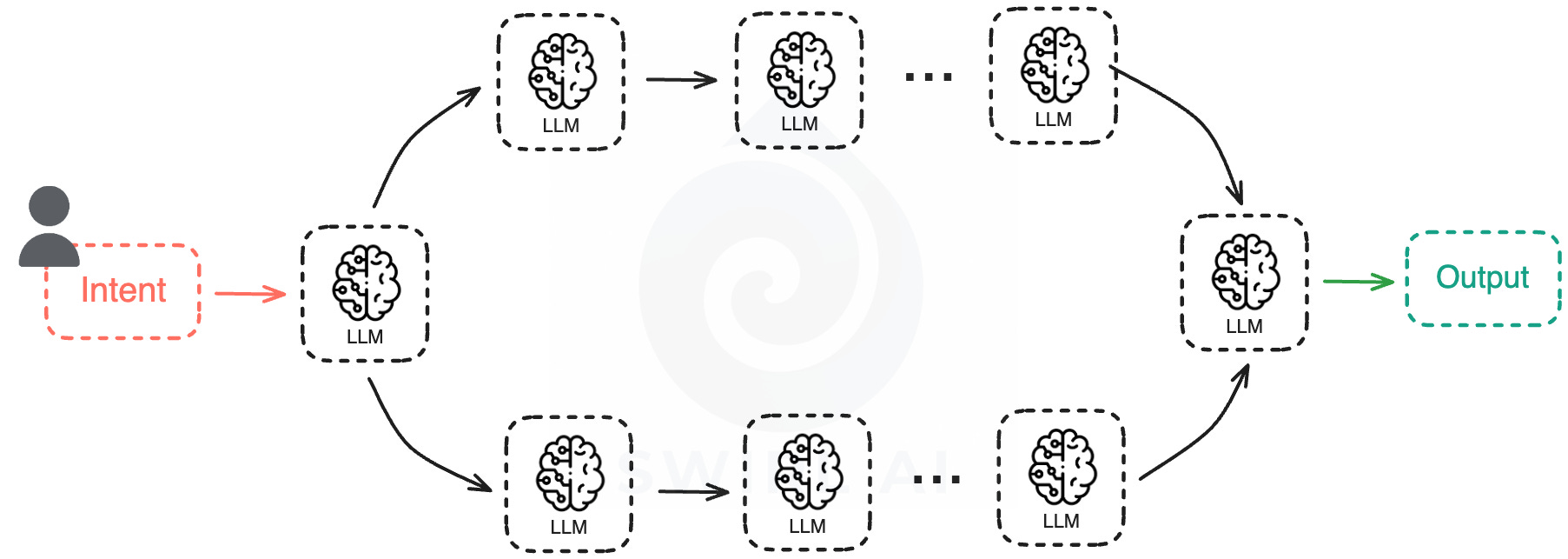
In simple terms, it is a topology of LLM calls connected via different patterns. It could be an iteration loop or a more sequential pattern. But the main thing to take out from this is that each output of an LLM node influences the downstream system.
It is clear that quality of the agent is only as good as the context you pass to it via prompts fed to LLM at each step. One could think that ever expanding Context Size limits of the LLMs will be the solution, but there are many inherent problems in pushing as much data to prompts as possible. Few ways the Model can be confused due to too much information have been documented:
Context Poisoning: When a hallucination makes it into the context
Context Distraction: When the context overwhelms the training
Context Confusion: When superfluous context influences the response
Context Clash: When parts of the context disagreeContext window size.
This is where Context Engineering comes in. It is a practice of trying to provide the minimal amount of focused context to the specific Agentic System step so that it is able to perform work it was designed to.
There are multiple types of context that exists and needs to be managed and orchestrated in modern Agentic Systems. Bellow is an image listing these different types.
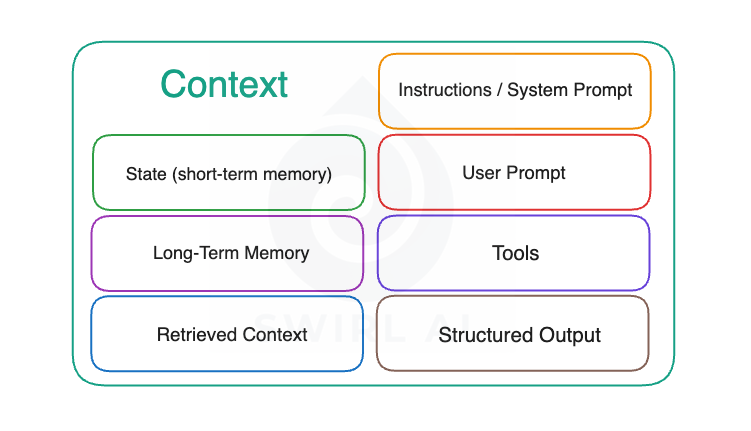
Let’s look into each part of the context separately and analyse what kind of challenges we need to solve when engineering/orchestrating it.
Join the September Cohort of my End-to-End AI Engineering Bootcamp to learn how to solve the challenges of Context Engineering for production systems in the real world. (Use code KICKOFF10 at the checkout for 10% discount).
Instructions / System Prompt.
Where it fits: System instructions (or the system prompt) are rails that define LLMs outputs on a more general level. This is a special prompt that defines the role, behavior, and boundaries of the LLM outputs before any user input is passed to the LLM later. These instructions set the overall tone, personality, scope and response style for the model. They act as policy, ensuring the LLM follows certain rules regardless of what the user asks.
Challenges.
Alignment - the system prompt must cover all the necessary guidance (from factuality checks to style guidelines) within a limited space. Too little can make the model may go off-track, too much might constrain useful behavior.
Risk of prompt injection - a malicious user input can override or contradict the system instructions. Current LLMs don’t perfectly separate system instructions from user text. Attackers may embed conflicting instructions that cause the model to ignore the original rules.
System context can conflict with user needs - if the user asks for something outside the allowed scope, the LLM must refuse per system instructions. Maintaining helpfulness with these constraints is a hard challenge.
User Prompt.
Where it fits: The user prompt is the direct request or query provided by the user, the immediate task the user wants done. This part of context was the main focus of prompt engineering - developers tweaked wording and details to try and get better answers from LLMs.
Challenges.
Real use cases often involve multi-turn conversations/interactions, follow-up questions or the need for external information.
A single user query might require multipple steps to be answered. E.g. searching for information, then summarizing, then formatting an answer. Such task can’t be solved by a single Agent turn, it requires multipple turns in sequence. Check out the Deep Research Agent as an example:

Context engineering addresses this by breaking complex user requests into smaller sub-tasks or chaining prompts. The challenge here is understanding the user’s true intent and managing the agents flow to solve that intent.
Ensuring that the user’s request is fully understood and fulfilled over multiple turns requires a lot f iteration and comprehensive eval suites covering multiple complex interaction examples.
In short, the user prompt is just the starting point. The context engineering needed to handle intent solution is what goes next.
Retrieved Context.
Where it fits: Retrieved context refers to additional information pulled in from outside sources to help answer the user’s query. This is the main concept on which Retrieval Augmented Generation (RAG) systems are based. When a question requires facts or data not already in the LLM’s parametric knowledge, the system would fetch relevant context from databases, documents, web or other APIs. Once we retrieve the data we inject it to the prompt that is given to the model. This external information becomes part of the model’s context for that turn.
Challenges.
The primary challenge with retrieved context is finding and choosing the right information. In a large enterprise knowledge base or internet-scale data, there may be thousands of snippets that could be related.
The system has a limited context window (a maximum number of tokens it can attend to, and also the previously mentioned confusion modes) so we must be selective about what we include there. We need to solve an optimisation problem - from N candidate pieces of data, pick the ones that matter most for this query. Retrieving too little will leave out key facts, retrieving too much will produce noise.
Mitigating these issues requires hybrid retrieval and clever ranking of retrieved snippets, filtering out low-quality or conflicting data, and sometimes summarising or compressing the retrieved text.
Properly preparing the corpus for retrieval is also a huge Data Engineering challenge as you need to carefully preprocess each of the chunk before embedding so that each of the chunks does not miss relevant surrounding context and more global metadata.
State (short-term memory).
Where it fits: There is a blurred line between State and conversation history - the recent messages in the current session. The System State serves as the model’s working memory of the latest state available. Part of this state is also the conversation history. It does not mean though that you always pass the entire conversation history or other elements of the state each time you invoke an LLM as part of the system execution. Context Engineering as a lot about how you manage this evolving state and what minimal parts of the state are passed to LLMs in trying to make them perform exactly the tasks they are meant to perform.
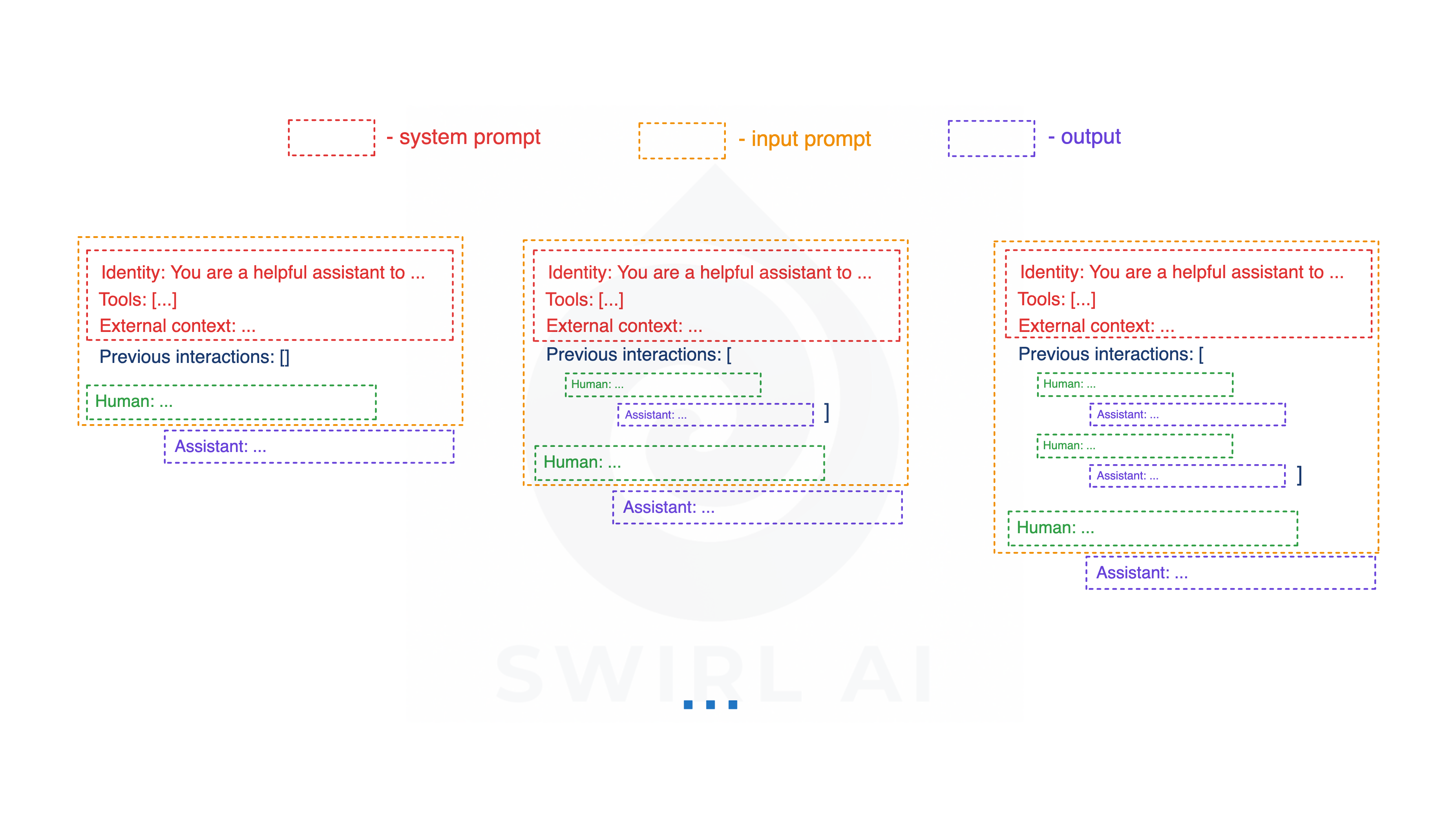
Challenges.
Obvious limitation is that the context window is finite. In long conversations or long-running AI agent tasks, the amount of conversation can exceed the size of the context window, forcing the system to drop or compress older messages. The challenge is deciding what to remember and what to forget. If you append the entire conversation every time, you will hit token limits. If you forget too aggressively, the model will lose important details and repeat past questions and tool calls.
Context engineering at this layer involves techniques like summarisation, clipping and context caching. E.g. summarising earlier parts of the conversation and only keeping the summary or selectively carrying forward key facts
Another issue is context drift - over many turns, if the model’s memory of early instructions or facts gets too diluted, it may start to deviate from the original intent. We need to continuously ensure the our Agents stays on track (sometimes by re-injecting key instructions into the context if they were dropped).
Long-Term Memory.
Where it fits: Long-term memory is a mechanism for Agents to retain information beyond the current session. This can include data like user’s preferences and profile, facts learned in past conversations, or any data that should persist over time. Implementations of long-term memory will vary - from simple databases of past Q&A pairs to vector embeddings of conversation transcripts that can be searched on demand. The key is that this memory is persistent and can be pulled into context when relevant.
Challenges.
Relevance and retrieval - given months of accumulated interactions or facts, how do we fetch only the pieces that matter for the current conversation? Similar like with retrieved context, it is not viable to load everything - the system needs to search and inject the most relevant memories. You might have hundreds of things the Agent could recall about a user, but only a couple are useful in answering the current question.
Consistency and updating - long-term memory can become a liability if not managed well - e.g. the user’s situation may change (they get a new job) and the memory store must be updated or old info deprecated. Stale or incorrect memories can lead to responses that could potentially breach trust.
Privacy and security - storing personal data long-term requires safeguards so that sensitive info is not unintentionally exposed.
Integrating memory into context without confusion - if our system pulls in a summary of your past chats, that summary becomes part of the prompt which could potentially conflict with other instructions or overwhelm the model if too verbose.
The connection between Long and Short-Term memory can be visualised as follows:
Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
Tools.
Where it fits: Most advanced AI systems would use external tools - for example, calling APIs, running code, searching the web or simply performing Retrieval via a predefined function. This extends the model’s capabilities by letting it act in the environment or fetch information dynamically. In terms of context, whenever we expose a tool to the LLM, we need to take care of two aspects:
Tool definitions - the instructions or documentation describing what tools exist and how to use them (often provided as part of the system prompt).
Tool outputs - the results returned by the tool, which the model should incorporate into its next response.
Vanilla Tool use implementation can be described as follows:
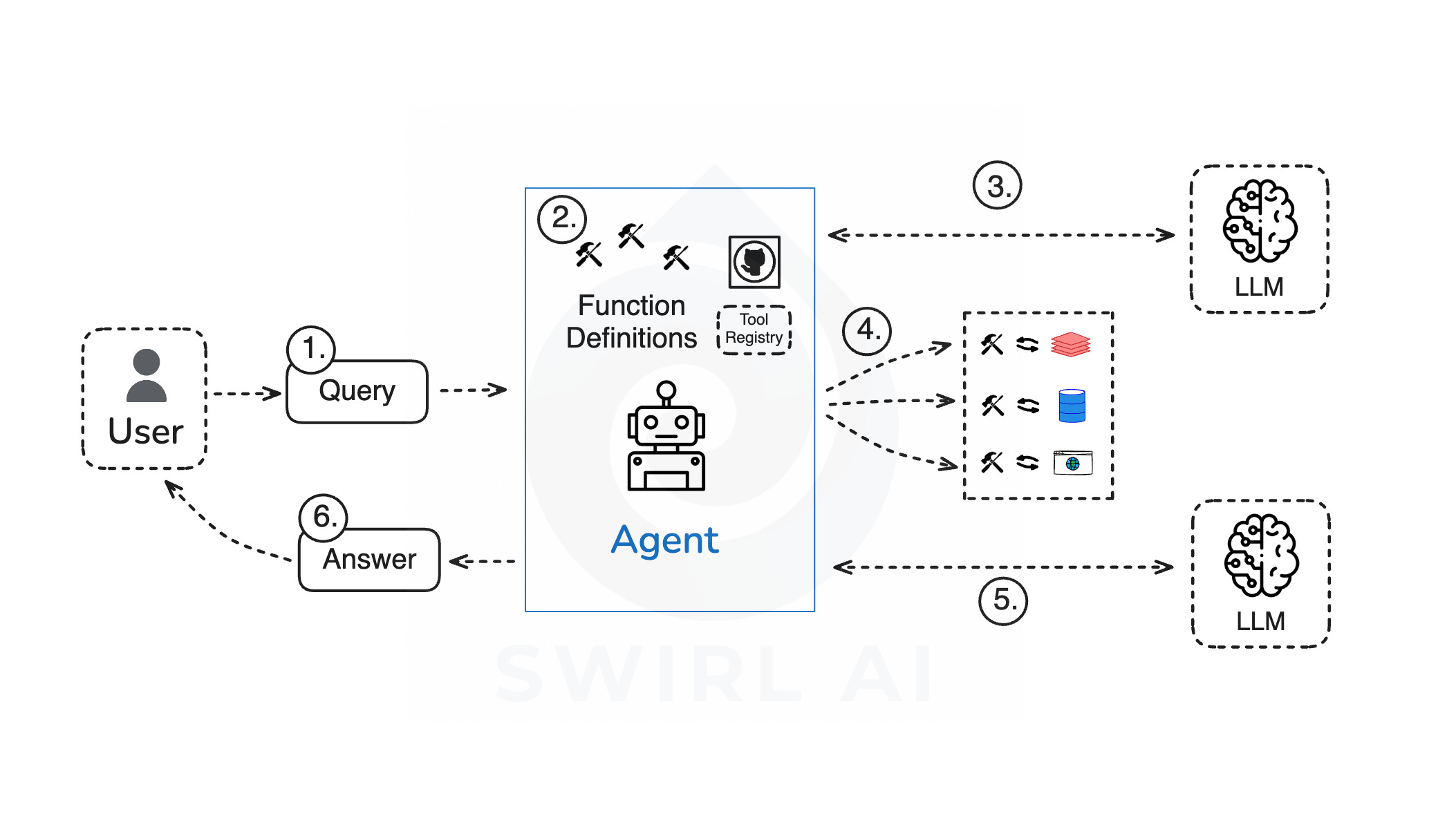
User Query is passed to the Agent (usually a Python application).
All of the available Functions/Tools are defined as part of the Agent code (procedural memory).
The list of available Tools is passed together with the User Query to a LLM via a prompt. The LLM figures out which functions need to be invoked and with what parameters.
The Agent application directly executes the functions.
User Query is sent to the LLM together with the data retrieved after function execution.
The answer is constructed and returned to the user via the Agent.
Challenges.
The model must understand when and how to suggest a tool invocation. This often requires carefully prompting the model with instructions like:
When making tool calls, use this exact format: { "name": "tool_name", "arguments": { "parameter1": "value1", "parameter2": "value2", } } CRITICAL: All parameters must go inside the "arguments" object, not at the top level of the tool call. Examples: - Remove item from shopping cart: { "name": "remove_from_shopping_cart", "arguments": { "product_id": "123", "user_id": "123", "cart_id": "456" } }Once a tool is used, the output needs to be integrated seamlessly. If the tool returns a lot of data, including that in the context can quickly hit context size limits. Often we need to post-process tool outputs, e.g. extracting parts that are relevant, summarising etc. before appending it to the context.
State maintenance between tool calls and the model’s reasoning. Sometimes Agent architectures implement patterns similar to ReAct where the model iteratively reasons, calls a tool, analyses the result and continues. Ensuring that the model’s chain of reasoning is properly preserved across these steps is not trivial. Especially when you also need to keep the track of the original user query.
Error handling - tools can fail or return unexpected results. In those cases we need to stitch safety nets around the non-deterministic part of the system (i.e. guide the model on how it should respond in the case of such errors, e.g. apologise and exit the system).
From a security standpoint, tool use carries risks in context. E.g. if the System reads from a URL, the page might contain malicious text (prompt injection via tool output) or sensitive data that shouldn’t be revealed. Context engineering for tools also means guard-railing such cases and properly mitigating the risks.
Structured Output.
Where it fits: In most agentic applications, it is not enough for the LLM to respond with free-form text since the output of one LLM call can be an input to the next LLM call, hence we often need the answer in a particular format or structure. This could be a JSON object, an HTML snippet or a SQL query. Context for ensuring correct structured outputs refers to any instructions or mechanisms that enforce a certain format for the model’s response. In most cases you would define these rules as part of the System Prompt, on top of the instructions you should use frameworks like Instructor that help in making sure that structured outputs are properly handled.
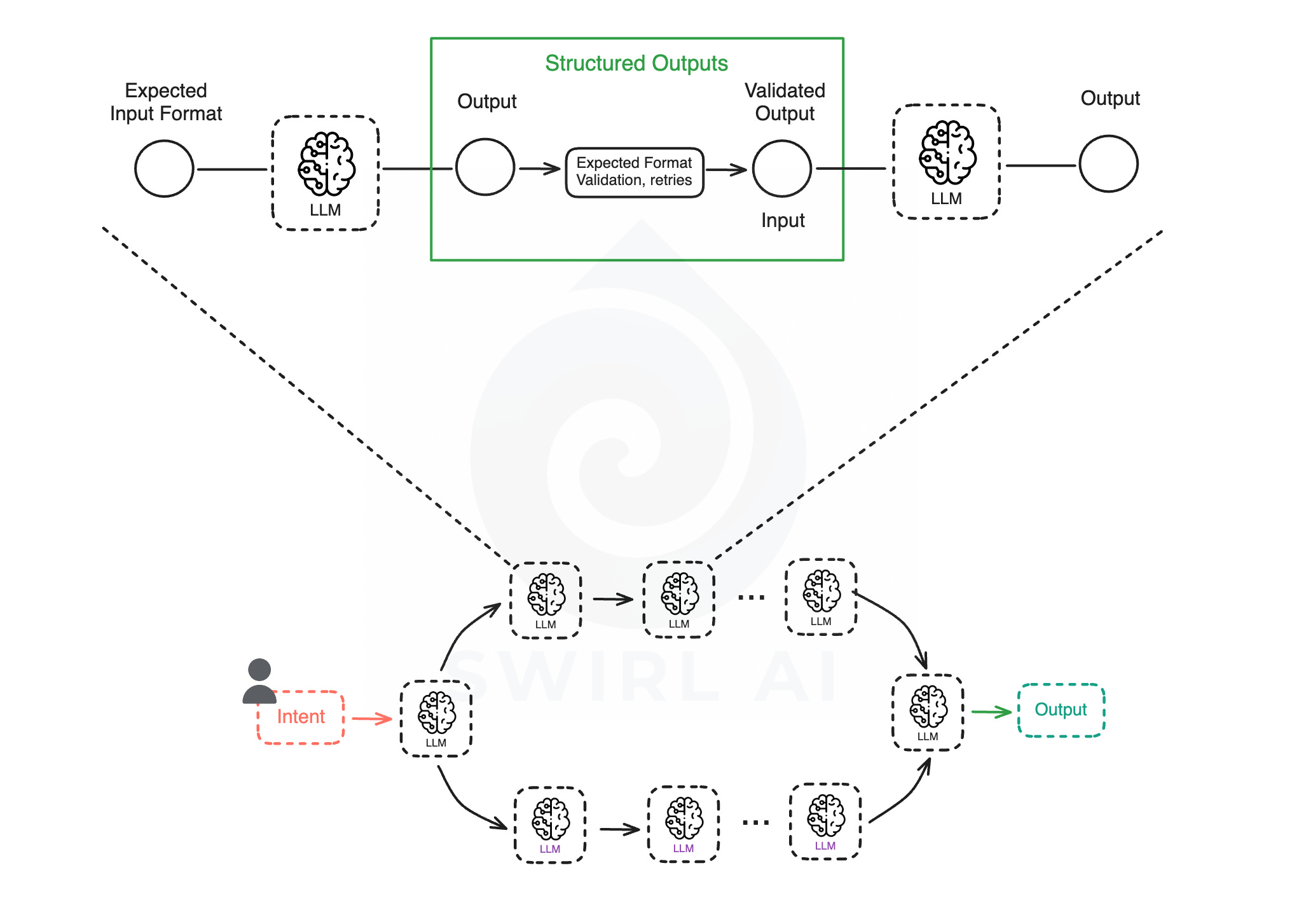
Challenges.
Anyone who has tried to get LLM to output perfectly structured data knows how frustrating it can be. Models often hallucinate formatting or include extra explanations despite instructions.
A major challenge here is reliability - how to guarantee the output is formatted exactly as it is needed (no missing brackets, no additional text). While there are ways to minimise inconsistencies (like using OpenAI’s function calling and similar APIs that allow developers to specify a JSON schema or grammar that the model must adhere to, constraining the model’s decoding) not all systems support that.
The good news is that tooling is improving - validators, format enforcement and better prompt techniques. A good example is the Instructor library that I personally use in most of my projects. It enforces the outputs to conform to specific Pydantic schema objects as well as applies advanced retry techniques if initial parsing of the outputs is not successful.
Wrapping up.
Context engineering is an actively evolving practice. We are all learning in the trenches - even though some practices might work today, some of them might become less relevant in the future as the tooling improves, some might stop working due to the changes in behaviours of LLMs. Whatever you think about it, it is the time to participate in defining the best practices and help moving the industry forward.
Happy building!
Hope you enjoyed this article and hope to see you next week!