
Building AI Agents from scratch - Part 2: Reflection and Working Memory
Let's implement AI Agent from scratch without using any framework. Today we implement the reflection pattern coupled with simple implementation of short-term memory.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in GenAI, MLOps, Data Engineering, Machine Learning and overall Data space.
I hope you had a wonderful holiday season! As we move into the year of AI Agents, I also have a present for you, the second part in the series of “Building AI Agents from scratch”. If you missed the previous episode (part 1), you can find it here:

We implemented Tool Use pattern without using any LLM Orchestrator frameworks. Today, we will build on top of the previous project, I will explain how later in the article.
In this article you will learn:
What Reflection pattern in AI Agent systems is.
How it relates to short-term memory.
Pros and Cons of implementing Reflection.
How to build an Agent class that is able to implement Reflection pattern taking the memory into consideration without using any orchestration frameworks.
Just to remind ourselves why we are doing this. If you are using any orchestration frameworks for agentic applications, you might be abstracted away from how Agentic patterns are actually implemented there. Having clarity of how the systems actually work helps you build up systems thinking, enabling you to craft advanced applications more efficiently.
Fix some of the hallucinations we were producing in the previous project!
You can find the code examples for this and other projects in my GitHub repository here:
Be sure to star the repo if you find the content useful, a lot more to come!
YouTube video where I go through the first part of the series is coming next week. Be sure to subscribe to not miss it here.
As always, if something does not work as expected, feel free to DM me or leave a comment, let’s figure it out together!
Defining Reflection in AI Agents.
As it is with most definitions in AI Agents nowadays, there is no single way to specifically describe Reflection. The high level definition of the pattern is:
The ability of an Agentic System to reflect on it’s outputs and suggest improvements. Optionally, also improve the behaviour of the future actions in the system incorporating the feedback provided.
When explaining Agentic concepts I like to drop the abstraction of an Agent and think in Agentic flows - it is easier to reason when analysing flow diagrams and Agents eventually are just a number of steps interconnected via different topologies. Reflection can be applied in different steps of an Agentic flow. Let’s see how.
The simplest example.

The above Agentic flow includes the following steps:
User prompts the LLM with a query.
Generated answer is passed to the LLM where it is asked to provide feedback to the previously generated answer and provide instructions for improvement if any.
The improved answer is returned to the user.
As simple as it is, even this pipeline will provide significant improvements to the accuracy of the answers in many cases. Ofcourse, similar improvements can be achieved via prompt engineering of the system prompt, but reflection pattern is usually more powerful and flexible.
Reflection Loop.

The above Agentic flow is defined via the following steps:
A user query is passed to the LLM.
Generated answer is passed to the LLM where it is asked to provide feedback to the previously generated answer and provide instructions for improvement if any.
After applying the improvements, the improved answer is passed to the LLM again and is asked to provide feedback and suggestions for improvements once more. This loop is then repeated for a predefined amount of times or until the LLM is not able to generate more suggestions and returns a stop sign, usually a predefined string like “END”.
The final answer is returned to a user.
This kind of system is powerful, but requires a very specific use case. In literature it can be most often found described for code generation. It is easy to understand why - generated code can be continuously improved in multiple iterations. The system will always find where to over-engineer ;)
Andrew Ng has defined this pattern for code in one of his articles here.
In most real world use cases I would find it hard to make a business case for the use of reflection loop as it usually increases costs significantly.
Validating execution plans.

I find one of the useful spots to place a Reflection step is to validate an execution plan if planning is part of the Agentic flow. Let’s see how it could look like:
A user query with intent and a system prompt is passed to the LLM. The LLM generates an execution plan. This is also where an important point where the execution of the flow might break is. An example of the breakage would be the following:
Agentic flow decides if a direct answer needs to be returned to the user or a predefined tool should be used for additional context generation.
A decision is made that a tool should be used,
An incorrect set of parameters to be passed to the tool are hallucinated.
The tool returns an error.
With properly crafted Reflection step we can prompt the Agent to try and fix any hallucinations produced in previous step.
The plan can return a direct answer that is provided to the user,
Or it can prompt to use a tool which enriches the answer via another LLM call and it then is returned to the user.
We will actually be implementing this kind of flow in our hands-on example in the following sections.
More Complex Reflection flows.
As mentioned before, there is no predefined place for a reflection step to be invoked. In complex Agentic flows it can be used multiple times to validate intermediary answers, plans or any other part of Agentic topology.
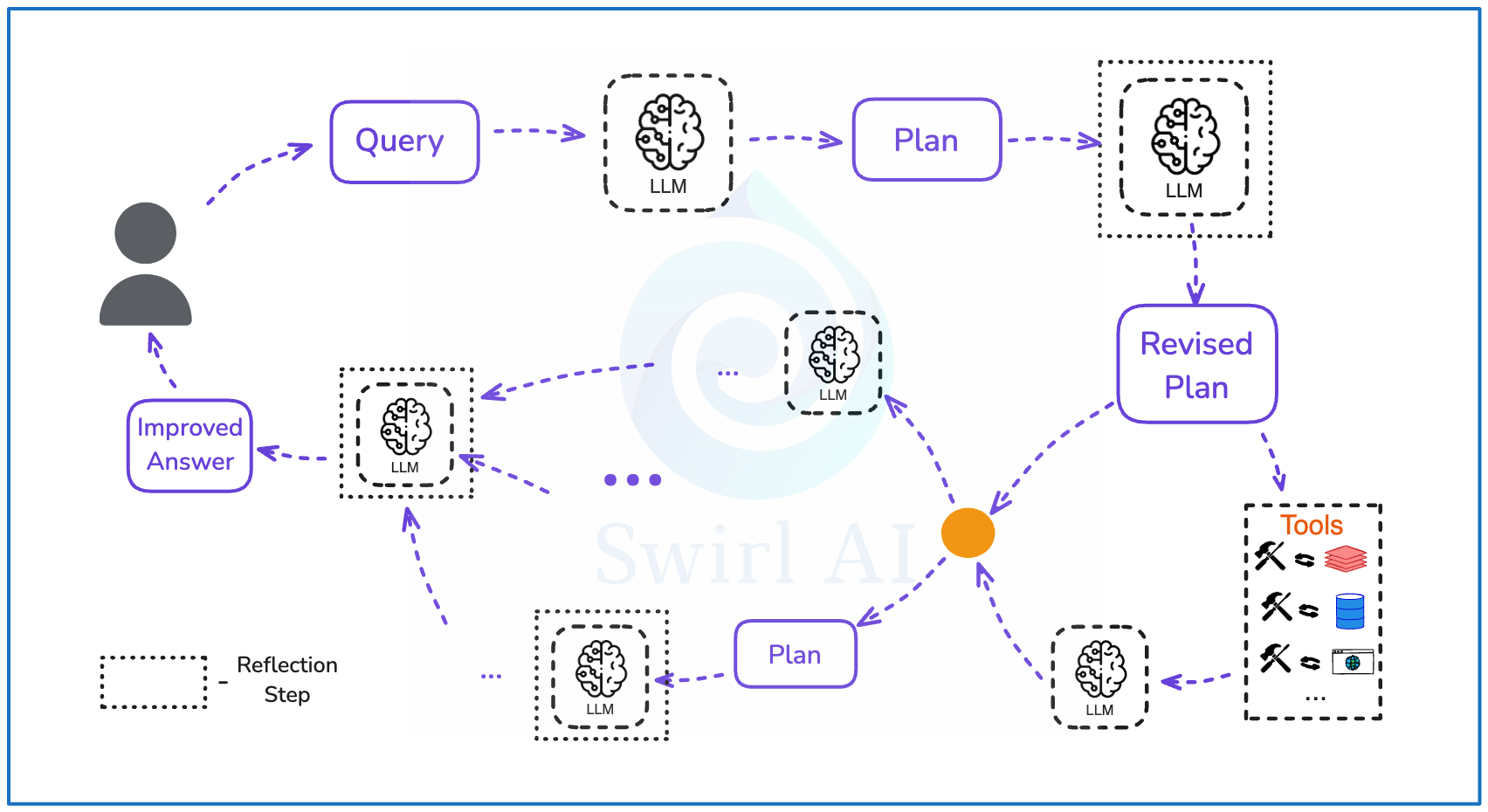
In reality, in order to automate complex processes that are present in organisations, you would build multi-step topologies with multiple probabilistic routers connecting execution nodes. Some routers could be implemented via LLMs, some might be rule based, some might use regular ML models. Some execution nodes will have tools, some will be just LLM calls, some will have non-probabilistic executions. Reflection steps could be implemented all around the place to increase the accuracy of non-deterministic routers and executions.
Connection between Agent Memory and Reflection pattern.
Usually, there is a need for some sort of short-term (working) memory implementation to make Reflection provide best results. Let’s see why by examining the third example of Agentic flows defined above.

The Agentic flow until the Reflection step can be invoked includes:
A) A System Prompt and a user query that will be passed to the LLM in order to generate the initial Execution Plan.
B) The execution plan generated by the initial steps.
C) The Reflection step will need All of this information since the System prompt will most likely have useful information about the available tools and similar, The user Query is important since it invokes the generation with context about user intent, the plan is important because it is what we are trying to improve.
In base generation implementation we are not keeping this information in memory, that is why the Working Memory needs to be implemented.

In the above picture I show the simplest implementation of Working Memory - Each of the interactions with an agent are simply stored in the list and passed as additional context to the system prompt each time the generation is invoked. This is how the simplest type of memory is implemented in the Chat Bots (e.g. ChatGPT).
If we are implementing an Agent with the capability of planning and we want to include the reflection capability, this is how it could look like:

As you can see, it is very similar, the only difference is that the initial response by the agent is the execution plan and the next query by the user is a prompt to reflect on the plan given previous interactions.
Pros and Cons of using Reflection.
As with anything that can bring improvements to the system, there is always upsides and downsides.
Pros.
Almost guaranteed improvement in the accuracy of final outputs of the system. Sometimes this is the only way to make your application feasible due to extremely high accuracy requirements.
Flexible compared to editing the initial system prompt. E.g. different Reflection methods or even agents can be utilised for different parts of the pipeline.
It is possible to achieve more with small models when Reflection is applied. Ofcourse, you should analyse the tradeoff given all of the cons but in general there is always a phase in the project where the goal is to optimise the costs of your AI system.
Cons.
Adds complexity to the application.
Adds additional latency to the end-to-end flow since additional LLM calls are invoked.
Adds additional cost since the LLMs are prompted at least one more additional time (usually more than one) with every Reflection step.
Building the Reflection Agent.
As mentioned at the beginning of the article, we will be working on the example where Reflection will be used to revise an action plan generated by a LLM. And this is not without a reason!
If you followed me in the first part of the series where we implemented tool usage from scratch, you might remember that we implemented a tool that is capable of converting between two currencies on demand. We prompted the agent to only use the tool if the conversion is actually needed. It worked well, but in the example we asked for Serbian to Japanese currency conversion.
Now, this was not my initial intent. I am from Lithuania and I wanted to showcase the scenario where I would be traveling from Lithuania to Japan so I initially prompted the model with the following query:
I am traveling to Japan from Lithuania, I have 1500 of local currency, how much of Japanese currency will I be able to get?Imagine my surprise, when the agent returned the following response:
Thought: I need to convert 1500 Lithuanian Litas (LTL) to Japanese Yen (JPY) using the currency conversion tool.
Plan: Use convert_currency tool to convert 1500 LTL to JPY. Return the conversion result
Results: Error: Could not fetch exchange ratesOfcourse the tool call resulted in an error - Lithuania has Euro (EUR) as an official currency from 2015! The tool was obviously not able to find LTL conversion rate to JPY.
And then I took it personal, in this episode my quest is to try and fix the plan using the Reflection pattern.

You can also find the code in a GitHub repository here.
You can follow the tutorial using the Jupyter notebook here.
Implementing the working memory.
We will implement a single interaction with an agent as a Dataclass:
@dataclass
class Interaction:
"""Record of a single interaction with the agent"""
timestamp: datetime
query: str
plan: Dict[str, Any]It will have the query and the plan that the agent produced.
It is important to note that we will also need the system prompt to be available for reflection step, but we will implement that separately.
We will be simplifying the Agent Class this time around by stripping any tool related functionality from it to better focus on reflecting on the plan generated by the Agent.
The initial system prompt.
We will keep the system prompt identical to the one we implemented in the part 1 of the series. You can find the explanation in this section of my previous article. The two differences are:
We are now mocking the available tool instead of actually implementing it. So the tools section will look like this:
"tools": [
{
"name": "convert_currency",
"description": "Converts currency using latest exchange rates.",
"parameters": {
"amount": {
"type": "float",
"description": "Amount to convert"
},
"from_currency": {
"type": "str",
"description": "Source currency code (e.g., USD)"
},
"to_currency": {
"type": "str",
"description": "Target currency code (e.g., EUR)"
}
}
}
]We are extending the capabilities and instructions of the agent by including the fourth line in both:
"capabilities": [
"Using provided tools to help users when necessary",
"Responding directly without tools for questions that don't require tool usage",
"Planning efficient tool usage sequences",
"If asked by the user, reflecting on the plan and suggesting changes if needed"
],
"instructions": [
"Use tools only when they are necessary for the task",
"If a query can be answered directly, respond with a simple message instead of using tools",
"When tools are needed, plan their usage efficiently to minimize tool calls",
"If asked by the user, reflect on the plan and suggest changes if needed"
]Implementing the Agent Class.
The agent class will be initialised with an empty Interaction history. Interaction history IS the working memory in this example.
class Agent:
def __init__(self, model: str = "gpt-4o-mini"):
"""Initialize Agent with empty interaction history."""
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.interactions: List[Interaction] = [] # Working memory
self.model = modelPlanning.
The plan method prompts the LLM to create the initial execution plan and updates the working memory with the user query and the generated plan.
def plan(self, user_query: str) -> Dict:
"""Use LLM to create a plan and store it in memory."""
messages = [
{"role": "system", "content": self.create_system_prompt()},
{"role": "user", "content": user_query}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0
)
try:
plan = json.loads(response.choices[0].message.content)
# Store the interaction immediately after planning
interaction = Interaction(
timestamp=datetime.now(),
query=user_query,
plan=plan
)
self.interactions.append(interaction)
return plan
except json.JSONDecodeError:
raise ValueError("Failed to parse LLM response as JSON")Reflecting on the plan.
The reflect_on_plan method is where the interesting part is.
def reflect_on_plan(self) -> Dict[str, Any]:
"""Reflect on the most recent plan using interaction history."""
if not self.interactions:
return {"reflection": "No plan to reflect on", "requires_changes": False}
latest_interaction = self.interactions[-1]
reflection_prompt = {
"task": "reflection",
"context": {
"user_query": latest_interaction.query,
"generated_plan": latest_interaction.plan
},
"instructions": [
"Review the generated plan for potential improvements",
"Consider if the chosen tools are appropriate",
"Verify tool parameters are correct",
"Check if the plan is efficient",
"Determine if tools are actually needed"
],
"response_format": {
"type": "json",
"schema": {
"requires_changes": {
"type": "boolean",
"description": "whether the plan needs modifications"
},
"reflection": {
"type": "string",
"description": "explanation of what changes are needed or why no changes are needed"
},
"suggestions": {
"type": "array",
"items": {"type": "string"},
"description": "specific suggestions for improvements",
"optional": True
}
}
}
}
messages = [
{"role": "system", "content": self.create_system_prompt()},
{"role": "user", "content": json.dumps(reflection_prompt, indent=2)}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0
)
try:
return json.loads(response.choices[0].message.content)
except json.JSONDecodeError:
return {"reflection": response.choices[0].message.content}We create a new prompt with specific instructions and desired output format. Note that the prompt has both the user query and the initial plan passed as additional context via a context key. Then we pass the prompt together with the initial system prompt to generate reflection on the initially generated plan including any suggestions for improvements.
Executing the flow and generating Revised Plan.
We now stitch the flow together via the execute method.
def execute(self, user_query: str) -> str:
"""Execute the full pipeline: plan, reflect, and potentially replan."""
try:
# Create initial plan (this also stores it in memory)
initial_plan = self.plan(user_query)
# Reflect on the plan using memory
reflection = self.reflect_on_plan()
# Check if reflection suggests changes
if reflection.get("requires_changes", False):
# Generate new plan based on reflection
messages = [
{"role": "system", "content": self.create_system_prompt()},
{"role": "user", "content": user_query},
{"role": "assistant", "content": json.dumps(initial_plan)},
{"role": "user", "content": f"Please revise the plan based on this feedback: {json.dumps(reflection)}"}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=0
)
try:
final_plan = json.loads(response.choices[0].message.content)
except json.JSONDecodeError:
final_plan = initial_plan # Fallback to initial plan if parsing fails
else:
final_plan = initial_plan
# Update the stored interaction with all information
self.interactions[-1].plan = {
"initial_plan": initial_plan,
"reflection": reflection,
"final_plan": final_plan
}
# Return the appropriate response
if final_plan.get("requires_tools", True):
return f"""Initial Thought: {initial_plan['thought']}
Initial Plan: {'. '.join(initial_plan['plan'])}
Reflection: {reflection.get('reflection', 'No improvements suggested')}
Final Plan: {'. '.join(final_plan['plan'])}"""
else:
return f"""Response: {final_plan['direct_response']}
Reflection: {reflection.get('reflection', 'No improvements suggested')}"""
except Exception as e:
return f"Error executing plan: {str(e)}"Note that the method applies reflection improvement on the plan ONLY if requested by the reflection generation. If not, we keep the old plan.
Executing the Agent.
Let’s see if we managed to fix the plan! Execute the agent by running:
query_list = ["I am traveling to Japan from Lithuania, I have 1500 of local currency, how much of Japanese currency will I be able to get?"]
for query in query_list:
print(f"\nQuery: {query}")
result = agent.execute(query)
print(result)If you used the same models as me, you should be getting something similar to:
Query: I am traveling to Japan from Lithuania, I have 1500 of local currency, how much of Japanese currency will I be able to get?
Initial Thought: I need to convert 1500 Lithuanian Litas (LTL) to Japanese Yen (JPY) using the currency conversion tool.
Initial Plan: Use convert_currency tool to convert 1500 LTL to JPY. Return the conversion result
Reflection: The plan needs modifications because the Lithuanian Litas (LTL) is no longer in use since Lithuania adopted the Euro (EUR) in 2015. Therefore, the conversion should be from EUR to JPY instead of LTL.
Final Plan: Use convert_currency tool to convert 1500 EUR to JPY. Return the conversion resultGreat success! we have fixed the plan and would be able to execute the tool successfully.
That’s it for today, we’ve learned:
How to implement a simple type of Working Memory.
How to construct a Reflection step to reflect on the execution plan generated by the Agent.
How to implement the suggestions generated by the reflection step and improve the plan.
Hey, nice write-up - the high-level architecture in particular seems like a good plan. One important issue I noticed in your prompt you should know about:
"requires_changes": { "type": "boolean", "description": "whether the plan needs modifications" },
"reflection": { "type": "string", "description": "explanation of what changes are needed or why no changes are needed" }
Since an LLM will respond to this in key order, when you ask it to first answer "yes/no" to `requires_changes` and only doing `reflection` after, you're basically having it justify whatever it chose based on unwritten reasoning when it decided the value of `requires_changes`. The correct order here would be to put `reflection` first so it can reason about it first *before* deciding yes/no. Hope that helps!
hey, thank you for posting this
have a few questions:
- why not simply use message history as memory? LLM would attend to it and also store prev tokens in KV cache, minimizing the amount of info needed to recompute
- reflection could be implemented as a separate agent or tool, allowing composability and dynamic routing, but you added it to the Agent. why this choice?