
Distributing FlashAttention: Solving memory Bottlenecks of Context Windows
Let's explore FlashAttention, types of distributed LLM training and how to fuse both concepts together.

Lately, I’ve been asked several times for my thoughts on the seemingly infinite context lengths of some of the latest LLMs - and whether this development might bring the end for techniques like Retrieval-Augmented Generation (RAG) in the long (or rather mid) run. My answer is always the same: RAG isn’t going anywhere soon because million-token context windows are still more an illusion than reality, the problems of “lost in the middle” and “ needle in the haystack” have not been solved yet even though the progress is big.
This recurring question inspired me to write a piece exploring the technical challenges involved in training LLMs with extended context windows.
Transformer-based models have revolutionised the field of deep learning. The ability to model long-range dependencies via self-attention is key in todays AI systems. As these models grow in capability we still face a key limitation: context length.
The problem: self-attention scales quadratically with sequence length. This means doubling the number of tokens more than quadruples the computational and memory load. While this cost may be manageable for short sequences, it quickly becomes unsustainable as models are trained on long-form content like legal documents, books, or extended conversations. And to achieve real (accurate) long context inference we need to train on long sequences or apply advanced techniques that help generalise to long sequences but have shown limitations.
In today’s episode we will explore:
Memory Bottleneck of the Context Window.
What is FlashAttention.
Parallelism techniques in distributed LLM training.
Combining FlashAttention and distributed training with Kvax.
This newsletter episode was made possible by today’s sponsor, Nebius - a leader in AI Cloud technology.

Recently Nebius has open sourced Kvax, their FlashAttention implementation based on JAX. Designed for efficient training with long sequences, Kvax supports context parallelism and optimised computation of document masks. It outperforms many other Flash Attention implementations in long-context training with dense packing.
In the second part of the article we will explore how Kvax supercharges distributed training with long input sequences. I highly recommend checking out the GitHub repository if you are innovating in this area.
Explaining the Memory Bottleneck of the Context Window.
The problem is as old as the Transformer architecture itself. Almost from the very beginning we have tried to stretch the context window of the LLMs to overcome the limitations that make some applications not feasible.
The problem with extending context windows lies within the architecture of Transformer itself, to be more precise - the Self-Attention mechanism that is the core piece of the architecture. Let’s look into the original Transformer description from the famous “Attention is all you need” paper:

The architecture of the network might seem complex from the first glance, but from the implementations side it is just a long sequence of matrix multiplications. To understand where the memory bottleneck of the Context window happens we would need to zoom into the “Scaled Dot-Product Attention” piece of the graph.
We will not go into the details of each computation step but rather focus on the part that is most affected by the length of the sequence which is forward passed through the network.
Let’s say you have a sequence of five tokens “He does not know what” (important: for simplicity sake we are assuming that each of the words result in a single token after the tokenisation step. This is not always the case and a single word can be divided into multiple tokens). The sequence of length 5 will always be transformed into a matrix of size 5x5 when attention operations are performed.

And this is where the scalability challenge of self-attention becomes particularly problematic: the infamous quadratic growth in both memory and computational requirements. In the self-attention mechanism, each token in the input sequence attends to every other token, which requires constructing an attention matrix whose size is proportional to the square of the sequence length. Concretely, if the input sequence has a length of n, the attention matrix is of size n x n. As a result, when we double the length of the input - say from 5 to 10 - the size of the attention matrix increases from 25 to 100, leading to a fourfold increase in both memory consumption and the number of computations needed to compute attention scores. This quadratic scaling makes it computationally prohibitive to process long sequences using standard transformers, especially in environments with limited memory or latency constraints.

Attention Mask.
Before we proceed with analysing the techniques designed to address the memory bottleneck of the context window in transformer models, it's important to first introduce the concept of the causal attention mask, as it plays a critical role in many of those solutions.
A causal attention mask is a type of filtering mechanism applied to the attention matrix during computation. Its purpose is to ensure that each token in the input sequence can only attend to itself and to tokens that come before it - never to future tokens. This is typically implemented by applying a lower triangular matrix (as shown in the image below), where positions representing attention to future tokens are masked out, effectively assigning them zero weight.
Most LLMs we use today - including models in the GPT family - rely on this form of masked attention. It ensures that during both training and inference, the model predicts the next token based only on the preceding context.

Now let’s explore one of the most widely accepted way of mitigating some of the memory bottleneck of the context window - FlashAttention.
Enter FlashAttention.
There have been multiple iterations of FlashAttention released to date - v1, v2 and v3. However, in this article, instead of focusing on specific implementations we will focusing on the core techniques and architectural ideas of FlashAttention which aim to mitigate the memory and compute bottlenecks in standard self-attention:
I/O Awareness & Fused Kernels.
Tiling.
Dense Packing.
Skipping Blocks.
Together, these techniques significantly reduce the quadratic memory and compute cost of vanilla self-attention, making it feasible to train and deploy large models on longer sequences and with greater efficiency. Let’s explore how.
Fused Kernel.
A Kernel in accelerated compute programming is a function or operation you launch on the node to perform a specific task in parallel.
Modern accelerated compute nodes have a hierarchy of memory:
The main memory (DRAM) which is large but relatively slow to access.
High Bandwidth Memory (HBM).
Much smaller on-chip memory (like registers, L1 cache, shared memory SRAM) which is very fast.
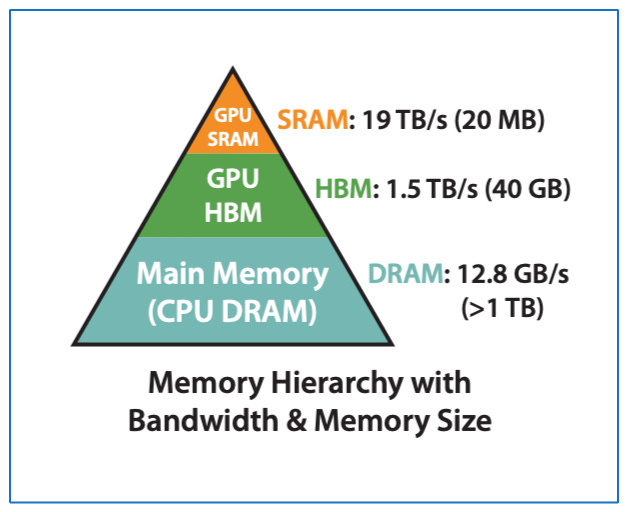
Remembering the computations involved in attention heads, we have multiple sequential matrix multiplications. With the standard attention implementation without I/O awareness we would load the intermediate results back and forth from HBM to SRAM and vice versa incurring unnecessary reads and writes between different layers of memory.

There are two main problems with this:
Memory (IO) bottleneck: copying these big matrixes (especially when sequences are long) to and from slow memory is expensive and quickly becomes the bottleneck.
Kernel launch overhead: each of the attention sub-steps above (matrix multiply, softmax, etc.) would be a separate kernel launch. Launching a GPU kernel has some fixed overhead (like setting up the execution on thousands of threads). If you have to launch multiple kernels one after the other, you pay that overhead every time.
A Fused Kernel is simply combining multiple operations into one kernel. Instead of launching one kernel for the matrix multiplication, another for softmax, and another for the value multiplication, all these steps are fused into a single kernel.

As shown in the below graph, Fused Kernel with other improvements in FlashAttention reduce the runtime significantly.

Tiling.
Tiling in FlashAttention is an optimisation strategy that partitions large attention matrices into smaller, more manageable sub-blocks which are processed independently. This approach enables efficient use of high-speed memory hierarchies within accelerated compute nodes. By loading each block into fast, local memory and reusing it for multiple operations, tiling minimises the need to access slower, large-scale memory repeatedly.

Clearly, as the sequence length increases, tiling becomes increasingly critical because it restructures the computation of the attention mechanism in a way that significantly reduces its computational and memory overhead. Traditionally, attention scales quadratically with sequence length, making it prohibitively expensive for long sequences. However, by breaking the attention matrix into smaller tiles and computing attention locally within these blocks tiling effectively transforms the quadratic complexity into a form that approaches linear scalability.

Skipping Blocks.
Remember the causal attention masks? This is where they become important in addressing memory bottlenecks of the context window. In causal attention, the lower triangular part of the attention matrix is masked by setting the corresponding attention weights to zero. These masked values effectively have no impact on the final output, making their computation unnecessary.
When applying tiling, this property becomes especially beneficial: if an entire tile or block of the attention matrix falls within the masked region, it can be completely skipped during computation.

Dense Packing.
In traditional implementations, attention computation often involves padding sequences to a uniform length, which leads to wasted computation on these padded tokens.
Imagine two sequences:
“He does not know what is best for him and his friends.”
“I am the second sample nice to meet you.”
This is how the attention matrix would look like for the first sequence if we fix the sequence length at 20. Notice all of the padding tokens required.

This is how the second sequence would be represented:

Here is where dense packing comes in. The technique allows you to pack multiple sequences into a single batch. Notice how the masked areas are placed. Dense packing addresses this inefficiency by grouping variable-length sequences together in a way that fills memory blocks as completely as possible, minimising idle compute and reducing memory overhead.
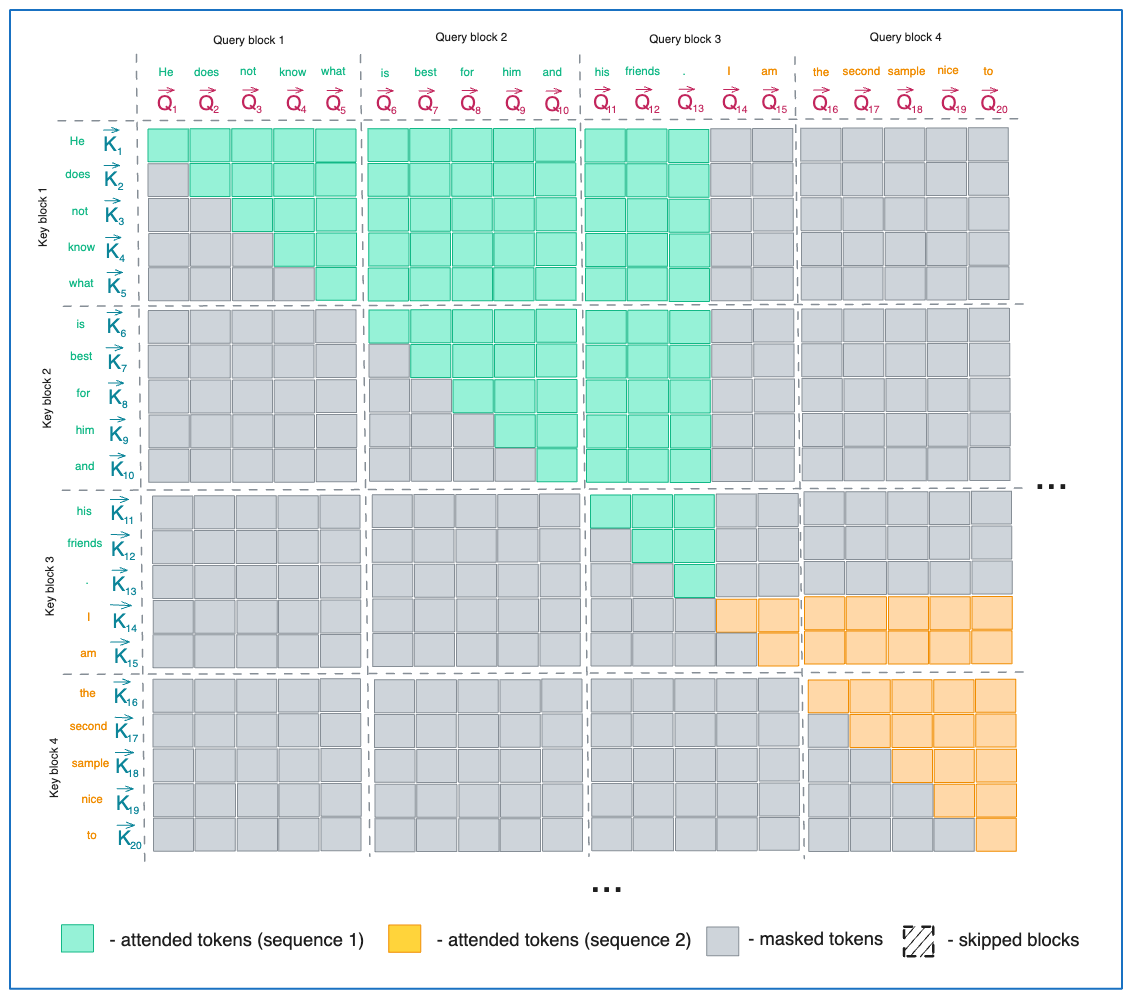
Combined with Tiling, Block Skipping and Kernel Fusion the algorithm achieves maximal efficiency gains.

In practical terms, FlashAttention can handle much longer sequences on a single accelerated compute node before running out of memory, and it can be up to several times faster than the naive attention implementation. However, FlashAttention by itself does not parallelise across multiple nodes - it’s about optimising attention on one device.
Parallelism in Distributed LLM Training.
To use FlashAttention for extremely long contexts that exceed a single node’s capability, or to speed up training by using multiple nodes, we need to parallelise the FlashAttention computation across devices.
Training LLMs often requires splitting work across multiple accelerated compute nodes due to the enormous model sizes and sequence lengths. There are multiple techniques applied to achieve this:
Data parallelism: the simplest approach - each node gets a different subset of the training data (mini-batch), and a full copy of the model. After each step, gradients are synchronised to keep model replicas in sync. However, data parallelism doesn’t reduce per-node memory or compute load of the model itself, it just uses more data in parallel.
To distribute the model’s workload, model parallelism is used. There are generally two forms of model parallelism:
Tensor (intra-layer) parallelism: splitting the computations within a layer across devices. For example, splitting a large matrix multiplication or the set of attention heads across nodes. In attention, this could mean each node computes a subset of the attention heads independently, then their outputs are combined. This reduces per-node computation, but it has limitations – e.g. the number of heads might be smaller than the number of available nodes.
Pipeline (inter-layer) parallelism: splitting the model’s layers among different nodes. Each node holds a consecutive chunk of the network layers. The micro-batch of data flows through the pipeline: first node processes the first few layers, then passes activations to the next node for the next layers, and so on.
In practice, state-of-the-art training combines all types of parallelism. For example, one might use tensor parallelism within each node, pipeline parallelism across nodes, and data parallelism for even higher scale. This is usually done due to minimal network speed considerations required for different parallelism types.
Another strategy relevant for long sequences is sequence parallelism (also called context parallelism). This involves splitting the input sequence length across nodes. Each node then handles a different chunk of the sequence tokens. The challenge is that certain operations (like self-attention) are not independent across sequence chunks and require communication.
Kvax by Nebius.
Kvax makes FlashAttention “distributed-friendly” through several key techniques:
Context (Sequence) Parallelism with All-Gather: It splits the sequence across nodes and uses an all-gather of Key/Value tensors so each node obtains the full context before computing attention. This allows each node to run the FlashAttention algorithm on its local queries with all necessary data, just as if it were a single-device run.
Grouped Query Attention (GQA): By using GQA (grouping heads to share K/V), the size of keys and values to communicate is reduced. This keeps the all-gather overhead very low relative to computation, making scaling efficient. The attention computation remains the dominant cost, so multiple nodes can collaborate with minimal slowdown.
Fused high-performance kernels: Kvax’s implementation in Triton ensures that on each node the FlashAttention computation (and mask application) is done in a tiled, memory-efficient manner, just like single-node FlashAttention. It also splits and optimises the backward pass, using all-reduce to accumulate gradients, so multi-node training has the same mathematical correctness with minimal overhead.
Support for complex masks: The approach naturally accommodates causal masks and packed-sequence (document) masks by computing masks on the fly and by virtue of each node having all keys/values (making mask logic simpler). This is crucial for real training scenarios where you concatenate multiple sequences or need attention window constraints.
Load balancing across sequence chunks: Kvax employs token shuffling across chunks (per LLaMA3’s recipe) to ensure each node does a similar amount of work. This prevents any single shard from becoming a hotspot (for example, the node handling the last part of a long sequence isn’t overwhelmed by having to attend to all preceding tokens).
Combined parallelism: Kvax doesn’t force you to choose one parallelism over another - it supports using data parallelism simultaneously with model parallelism. For instance, you could use tensor parallelism to split heads across GPUs and use context parallelism to split a very long sequence, in conjunction with data parallel across multiple such groups. This flexibility means Kvax can fit into many multi-dimensional parallel setups for large-scale training.
In essence, Kvax enables large-scale training of transformers with long contexts by efficiently distributing the attention computation.
Kvax demonstrates that FlashAttention can indeed be scaled across multiple devices without losing its efficiency edge. By addressing communication overhead and preserving memory-optimal computation, it allows training of LLMs with extremely long sequences (potentially 10k-100k tokens) on clusters of nodes while also maintaining high throughput.
Don’t forget to check out the open source library:
Wrapping up.
I intentionally kept this article high level enough to make it easy to skim through and build understanding of the difficulties of training large context window LLMs. Here are some general conclusions that I came to while writing this piece (some of the supporting facts are not part of the newsletter):
We have moved quite far in solving the Memory Bottleneck of the Context Window in the past few years after the emergence of LLMs.
FlashAttention is the standard technique to solve some of the Bottleneck problems and is included as a default in most of the training libraries.
The distributed training while using FlashAttention is not trivial. While it is being internally solved in big AI Labs, companies like Nebius are doing big favour to the community by open sourcing their implementations that help in distributed training.
There are much research on the way that is targeting ability of LLMs generalising to longer sequences even when trained on shorter sequences. This in combination with Distributed FlashAttention might allow truly long context windows that actually work.
The problems of “Lost in the middle” and “Needle in the haystack” have not been solved yet, but it seems it could be in the future.
Hope you enjoyed the writeup and hope to see you in the next one!
An interesting and informative article! However, one detail seemed a bit confusing — it looks like the Key blocks in "Padding: sequence 1" image shouldn’t include the second sequence, since the Dense Packing technique is only demonstrated later. Am I missing something here?