
Observability in LLMOps pipeline - Different Levels of Scale
SwirlAI newsletter is back! In this piece I outline my observations about the scale of infrastructure needed specifically for observing your processes in LLMOps pipeline.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in GenAI, MLOps, Data Engineering, Machine Learning and overall Data space.
A short re-introduction.
The last issue of my newsletter was sent out over a year ago now. In the meantime I did create some fresh, short form content now and then, but that was it. There are few reasons why I took prolonged vacation from writing.:
I am now a father to my lovely 8 months old daughter. No surprises here, it takes a lot of time and energy :)
My day-to-day job took away most of the remaining time and more.
Having said that, my entrepreneurial journey is moving forward and there will be many changes in the following months and years. First, I am returning to Substack and re-igniting the SwirlAI newsletter. Topics that I will mainly focus on with my long-form content include:
GenAI Systems Engineering:
RAG.
Agents and Agentic networks.
LLMOps.
MLOps.
Data Engineering for Machine Learning and GenAI.
System Design.
News in AI landscape.
My goal remains the same as always - to help You move your Data assets to production, as well as keep up with what is going in in the fast moving AI and Data world.
Thank you for reading and supporting the newsletter and hope you will continue to find value in my writing!
Today I am returning with a relatively high level episode of the Newsletter. In the following weeks and months I will go into lower level of each topic mentioned today.
This issue is inspired by the talk that I recently gave at The AI Conference 2024 in San Francisco.
[Disclaimer]: it was before the release of GPT4-o1. The techniques used to train the model may shift the perspective outlined in this article to some extent, but that is for future issues.
In the past years I have been extensively involved in designing and building Machine Learning infrastructure and dev tooling. My main focus areas were experiment tracking and observability. The rise of GenAI and large models of different modalities has introduced new challenges and significantly impacted how such systems are built. In this article I want to focus on these challenges and specifically on how it transforms Machine Learning experiment tracking and observability tools into big data analytics platforms. Before we jump into the details, let’s review the GenAI Value Chain.
GenAI Value Chain.
In the past two years the value chain of GenAI applications grew relatively complex as we continue to build advanced systems in attempt to bring business value using LLMs.
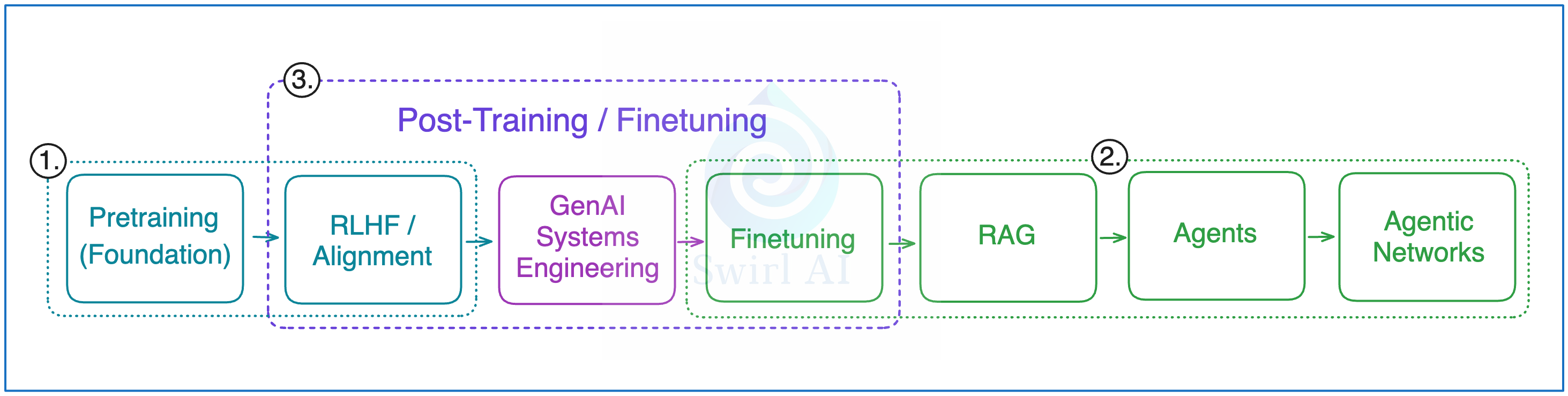
For clarity reasons it is worth splitting the value chain into two sections:
A stage where the foundation model (LLM or other modality) is being trained to be used for further alterations, this is where you will find AI Researchers do most of their work. This stage by itself can be split into two:
Pre-Training: a process where the model is trained on a large data set (web scale) to predict the next toked given a sequence of tokens.
Post-Training: this is where techniques like Reinforcement Learning with Human Feedback (RLHF) are used to align the model outputs with human preferences.
Once we have the foundation models ready, we then move on to build GenAI systems utilising the output of previous stage. This is where I define the start of GenAI Systems Engineering as we mix and mash GenAI models to build more advanced systems on top of them that are capable of solving real business problems, also this is where AI Engineers do most of their work. As of today, these systems can be ordered in terms of complexity in the following way:
Fine-tuned models.
Retrieval Augmented Generation (RAG) systems.
GenAI driven Agents.
Multi-agent networks.
It is interesting to note that in GenAI, models themselves are altered both in foundation model training stages as well as part of GenAI Systems Engineering.
While it is exciting to talk about GenAI systems, we have not yet achieved the levels of production readiness at each complexity level (I am excluding hyper-scalers as they are always ahead of the market). As of today, we already see Agentic systems moved to production and I believe we will be able to safely state that by the end of the year 2024 we are ready to tackle the next frontier. As for Multi-agent systems, there is still work to be done to make them reliable enough for production use cases, I do believe that we will get there by the end of next year though.

How does scale requirement for observability infrastructure evolve as we move through GenAI value chain?
Stages of pre-training and alignment are where experiment trackers play their role. There is a huge gap between an experiment tracker that can handle training of regular ML models and an experiment tracker meant for LLM training. I can say with confidence that the throughput of data to be ingested into the system as well as the speed at which it can be found and displayed to the user has went up at least ten times (in some cases more). This is why, even at the stage of model training, we see observability infrastructure costs reach the levels of observability needs of applications operated in production.
Once we are done with training and move to simple GenAI systems, the need for scale in Observability systems suddenly drops as it starts resembling regular ML model training process (Finetuning). Not for long though.
As we move on with GenAI Systems Engineering and increase the complexity of applications being developed, the scale of observability infrastructure continues to grow and even surpasses what is needed in pre-training phase.
In this article I will focus on the stages of GenAI Systems Engineering. As mentioned before, finetuning of the models is the least resource intensive stage when it comes to observability of the process, hence, let’s kick off with RAG.
RAG.
We will not go deep into Retrieval Augmented Generation (RAG) systems themselves but rather see what it takes to observe them. In the past year it became clear that:
Observability of an advanced GenAI system is all about tracing and evaluation.
Evaluation and Observability of GenAI systems is a complex topic. Today we only cover it on a high level. Few definitions to help build the mental model:
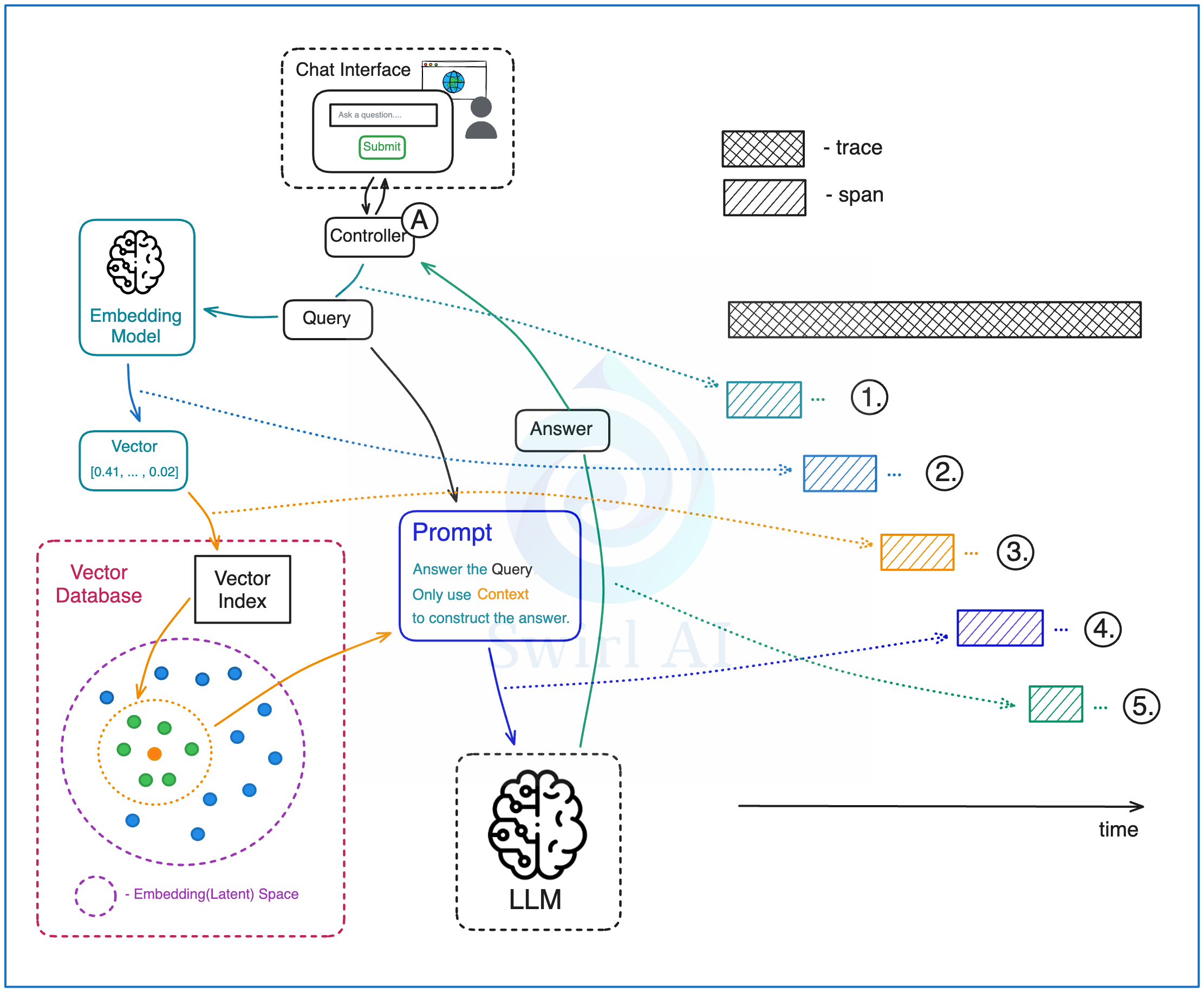
A) A Controller in the GenAI system application is the central piece of software that orchestrates the end-to-end process of the entire system (or part of it if we are talking about multi-agent systems). You will see it implemented in orchestration frameworks like LangChain, LlamaIndex, Haystack or others.
B) Trace is the end-to-end application flow from the entry point till the answer or action is produced, it is composed of smaller pieces called spans. The trace will contain its own aggregate metadata about the process.
C) Span is a smaller piece of the application flow that represents an atomic action like a function call or a database query. Note that in the provided example all of the spans are sequential, but that is not a requirement and parallelism is to be expected in production applications.
As part of a span we capture general metadata like start and end, inputs and outputs of the span. On top of this metadata we track information specific to the GenAI system elements.
What might a trace look like for a naive RAG system? Let’s look closer into the spans that compose the example trace:
A query that has been submitted to the chat application is moved through the controller.
The query is embedded into a vector. Additional metadata like input token count is persisted with the span so that we can estimate the cost of the procedure.
ANN lookup performed against the Vector DB to retrieve the most relevant context. Additional metadata about the query is persisted as part of the span together with the retrieved pieces of context and their relevance.
A prompt is constructed from the system prompt and retrieved context.
The prompt is passed to the LLM to construct the answer. Additional metadata about input and output token count is captured together with the span so that we can estimate the cost of the procedure.
Why is tracing of GenAI systems important?
These applications are usually complex chains, errors can happen in different steps of your application. E.g. Embedding of query is taking longer than expected or you have reached API limits of LLM provider.
Cost for calling LLM APIs will be variable depending on the length of inputs and produced outputs. You would usually trace this information and analyze it to help forecast expenses.
GenAI systems are non-deterministic and will deteriorate over time. They need to be evaluated on span level rather than input/output of the entire system so that you can tune each piece separately.
…
What are Observability challenges related to RAG systems?
One might argue, that Observability in GenAI is not much different from regular software. It is true on a high level, but GenAI systems bring new requirements:
Data is important. Similar to regular ML observability, it is all about inputs and outputs of the system. These can vary in length leading to extensive logs and big data related problems.
Subsampling of traces that you log is rarely an option especially if you are running applications that have high security requirements. E.g. you can be asked to provide system of record of any produced output and steps of how it was constructed.
Evaluation is important for most of the spans composing a trace as they each wil have their non-deterministic nature.
Evaluation is a complex topic involving various techniques. E.g. using an LLM to evaluate outputs compared to expectations (known as LLM-as-a-judge).
Agents.
How are Agents different from regular RAG systems?

As we move forward and try to solve more complex problems, we start relying on LLMs to figure out how our intentions should be achieved. This is where agents come in. A high level definition of a LLM based agent includes:
A controller application, which orchestrates the actions of the agent. It uses LLM as a brain to define a set of actions that the controller application should complete to achieve the goal. Once this set of actions is defined, the controller can then use capabilities given to it to achieve the desired result. Following are some of the generally used capabilities.
Knowledge - it is some additional context that the application can tap into. You can think of it as a Retrieval piece of RAG system. An usually it actually is exactly that - private context that LLM would not have access to via any other means.
Long Term Memory - similarly like knowledge, the controller might want to revisit some historic interactions that can not be contained in short term memory. Short term memory is usually limited by the context window size of LLM that is complimented with memory compression techniques.
Tools - a set of functions that the controller is allowed to call. Usually the available set of functions is also provided to the llm via a system prompt, so that the actions proposed by it could include the available functions. A function can vary from using a calculator, browsing the interned or even calling another LLM.
Instructions - this is usually a registry of prompts that the controller can use.
What are Observability challenges related to Agentic applications?
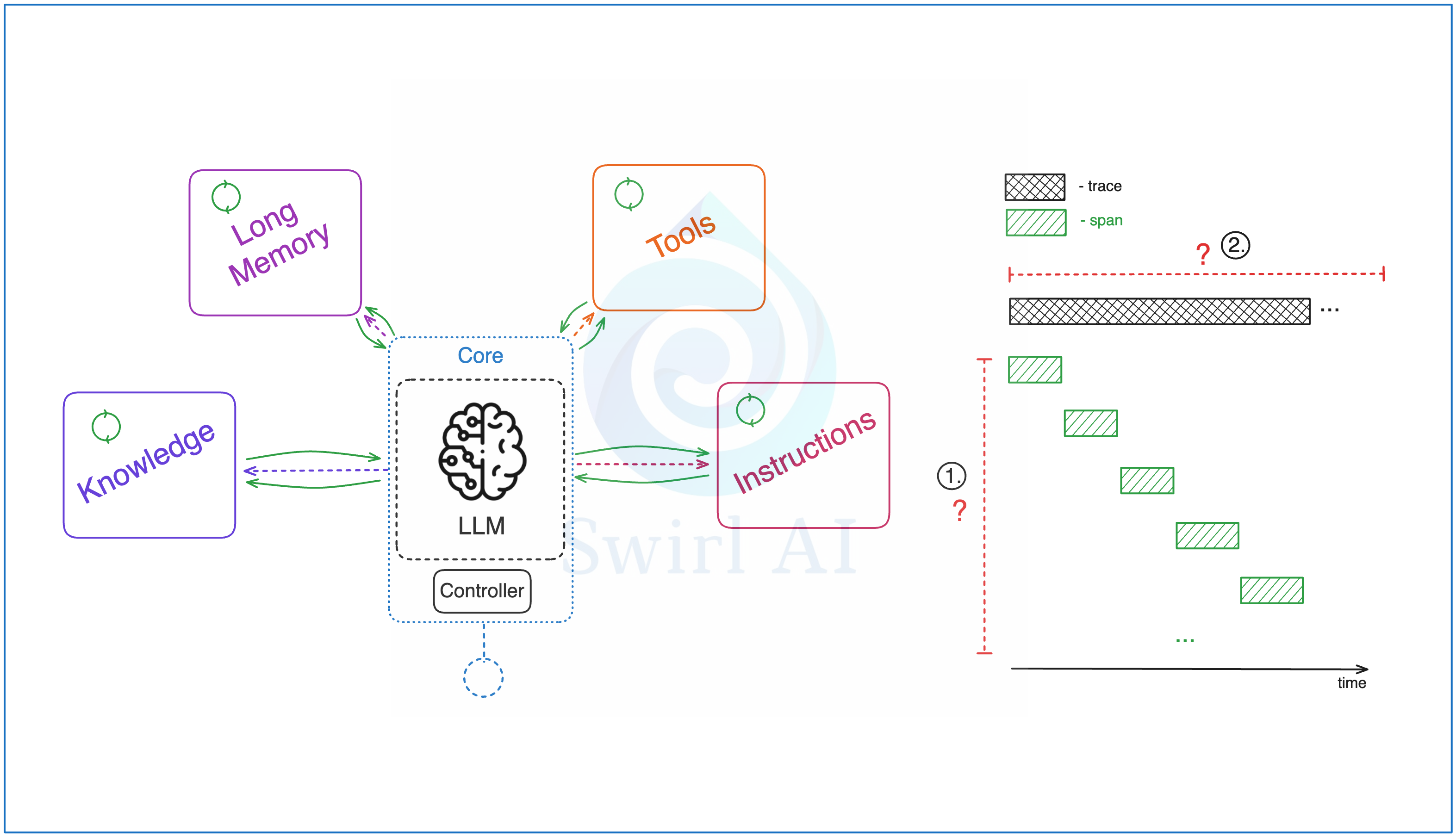
The main differentiator between Agentic and RAG systems is exactly the cause of challenges with Observability of these systems. The set of actions that are provided by LLM to solve a given task are non-deterministic, this results in:
The amount of spans in the trace and their types are in general not known beforehand and are defined during the run time. In some edge cases the Agent can even get stuck in an infinite loop while trying to solve the problem - this is where we try to put some rails on the amount of actions the Agent can take in an attempt to finish the task.
The length of a trace trace directly depends on the amount and type of spans as well as how they are positioned in time. While the example above displays all of the spans sequentially, that is in no way a requirement in a production system, especially if multiple actions that brings the application to its finish can be performed at once and then combined later.
On top of the above described non-determinism, each of the capabilities provided to the agent can be complex. E.g.:
Knowledge component is as complex as RAG.
Long Term Memory is even more complex as the updates to the knowledge persisted in this element is tightly connected to the actions performed within an agent and needs to be updated in real time compared to the context of RAG being external to to the system.
Multi-Agent Systems.
Multi-Agent system is an interconnected network of Agents that can communicate with each other by sending specific requests for work completion, usually each capable of solving a more specialised task. The idea is that a more specialised agent is able to solve the specific problem ore efficiently by keeping the required context narrowed down. An intent to such system might be given by a user and the network then attempts to fulfil the request.
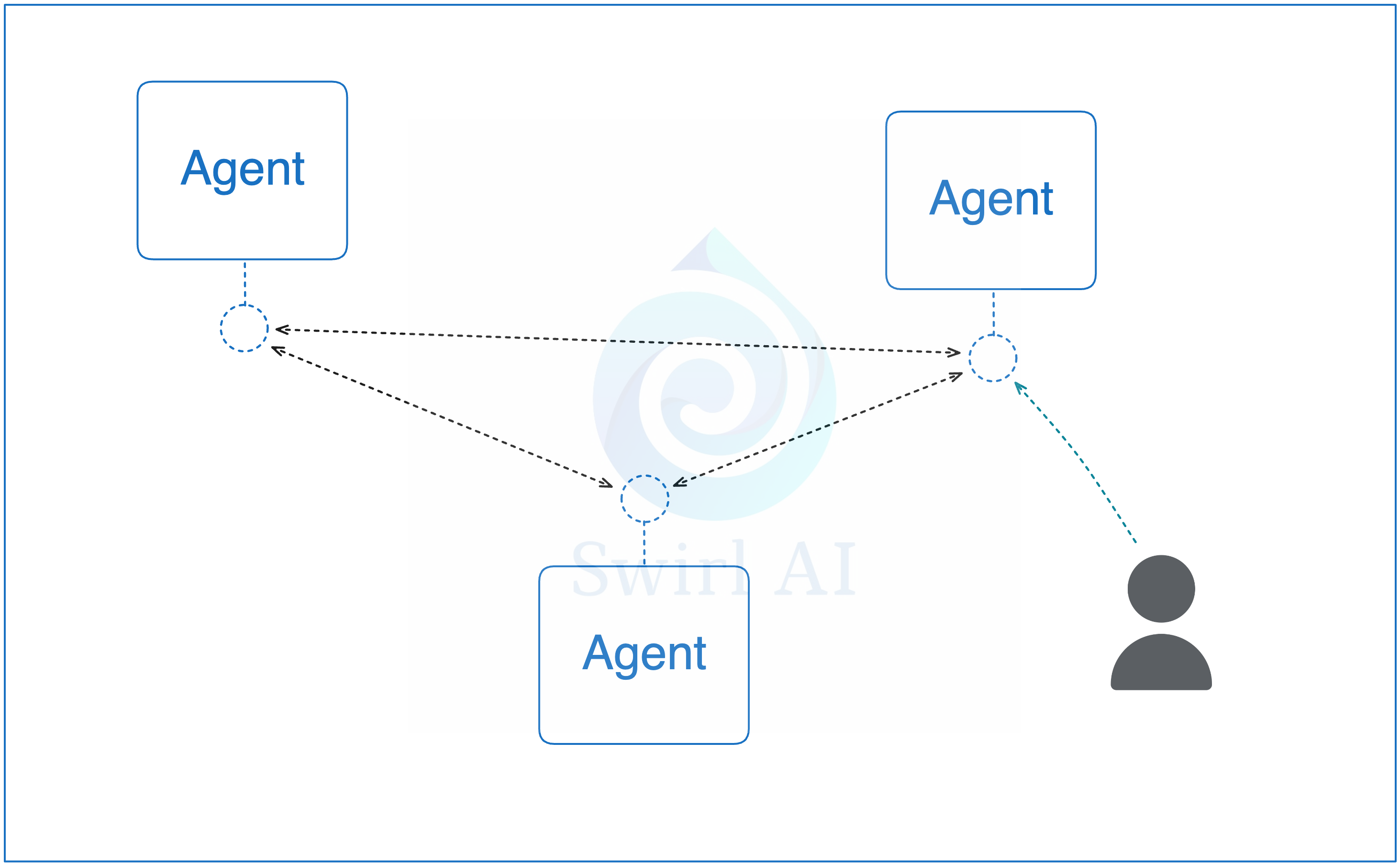
There are various Agentic network topologies that are common in the industry with their own pros and cons:
Fully connected mesh.
Supervisor with Specialist Agents.
Mixed.
…
I will write a dedicated Newsletter issue to explain these in the future.
What are Observability challenges related to Multi-Agent applications?

Depending on the chosen network topology, a new level of non-determinism is added to the system. In addition, we start running into distributed tracing territory, where there is a need to connect multiple traces produced within different agents. When building such systems we need to be able to answer questions like:
How will we connect the traces produced by multiple agents in the path to solve the original task into a single trace? Usually, this is less complicated if we run all the agents in a single service, but becomes a lot more complicated if we treat agents as separate services in micro-service environment.
How will the communication pattern between agents be implemented? It is common to see event based communication via queues in such a systems since processing time for any agent is non-deterministic and might cause latency related risks when exposed via REST or gRPC APIs.
How do we ensure that the desired work is actually completed and the system does not run into an endless loop and gets stuck?
On top of the above points we also add all of the complexities of RAG and single Agent systems. As one can imagine, the traces to be stored and evaluated become long, nested in complicated ways - fine-grained evaluations on span level as well as advanced visualisations become hard to implement.
To wrap up.
The evolution of Machine Learning infrastructure and observability tools is being reshaped by the rise of GenAI and large-scale models. The shift from traditional ML models to the complex GenAI systems - RAG, agents, and multi-agent networks - has introduced new challenges, pushing observability tools to function as full-fledged big data analytics platforms. As these systems grow more complex and non-deterministic, the demands on experiment tracking, evaluation, and tracing infrastructure continue to escalate.
Excited to see where this brings us as the industry. Even more excited to be part of it, building at the forefront!