
SAI #05: Spark - Distributed Joins, Static vs. Dynamic Features and more...
Spark - Distributed Joins, Kafka - At Least/Most Once Processing, Static vs. Dynamic Features, Training/Serving Skew.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
Spark - Distributed Joins.
Kafka - At Least/Most Once Processing.
Static vs. Dynamic Features.
Training/Serving Skew.
Data Engineering Fundamentals + or What Every Data Engineer Should Know
𝗦𝗽𝗮𝗿𝗸 - 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗝𝗼𝗶𝗻𝘀.
Distributed Joins are fundamental in Batch systems and can be found all around the Distributed Frameworks. Today we will look into it from the perspective of Spark.
𝗥𝗲𝗳𝗿𝗲𝘀𝗵𝗲𝗿:
➡️ Spark Jobs are executed against Data Partitions.
➡️ Data Partitions are immutable.
➡️ After each Transformation - number of Child Partitions will be created.
➡️ Each Child Partition will be derived from Parent Partitions and will act as Parent Partition for future Transformations.
➡️ Shuffle is a procedure when creation of Child Partitions involves data movement between Data Containers and Spark Executors over the network.
➡️ Shuffle is ineffective and is required by Wide Transformations.
➡️ Join is a Wide Transformation but shuffle can be avoided.
𝗦𝗵𝘂𝗳𝗳𝗹𝗲 𝗝𝗼𝗶𝗻
➡️ A regular join that accomplishes data locality by invoking shuffle for each DataSet that is participating in the join.
➡️ Records of the DataSets being joined containing the same join keys are pulled together and new partitions are formed.
➡️ Number of partitions are defined by 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝘀𝗵𝘂𝗳𝗳𝗹𝗲.𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀 configuration which defaults to 200.
✅ It is good idea to consider the number of cores your cluster will be working with. Rule of thumb could be having 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝘀𝗵𝘂𝗳𝗳𝗹𝗲.𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀 set to one or two times more than available cores.
𝗕𝗿𝗼𝗮𝗱𝗰𝗮𝘀𝘁 𝗝𝗼𝗶𝗻
➡️ Broadcast join informs Driver to pull in one or more of the DataSets participating in the join and Broadcast them to all Spark Executors.
➡️ Broadcast procedure means sending the full nonpartitioned dataset to each node to be cached locally.
➡️ This procedure prevents shuffling by having all except one DataSet present on each Executor.
✅ Use Broadcast Join when one of the DataSets is relatively small - it will have to easily fit in memory of each executor.
𝗔𝗱𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗻𝗼𝘁𝗲𝘀
Spark 3.x has some nice automated optimization options for joins.
𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝗮𝗱𝗮𝗽𝘁𝗶𝘃𝗲.𝗲𝗻𝗮𝗯𝗹𝗲𝗱 + 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝗮𝘂𝘁𝗼𝗕𝗿𝗼𝗮𝗱𝗰𝗮𝘀𝘁𝗝𝗼𝗶𝗻𝗧𝗵𝗿𝗲𝘀𝗵𝗼𝗹𝗱
👉 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝗮𝗱𝗮𝗽𝘁𝗶𝘃𝗲.𝗲𝗻𝗮𝗯𝗹𝗲𝗱 - if this option is set to True (default from Spark 3.2.0) Spark will make use of the runtime statistics to choose the most efficient query execution plan, one of the optimizations is automated conversion of shuffle join to a broadcast join.
👉 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝗮𝘂𝘁𝗼𝗕𝗿𝗼𝗮𝗱𝗰𝗮𝘀𝘁𝗝𝗼𝗶𝗻𝗧𝗵𝗿𝗲𝘀𝗵𝗼𝗹𝗱 - denotes the maximum size of a dataset that would be automatically broadcasted.

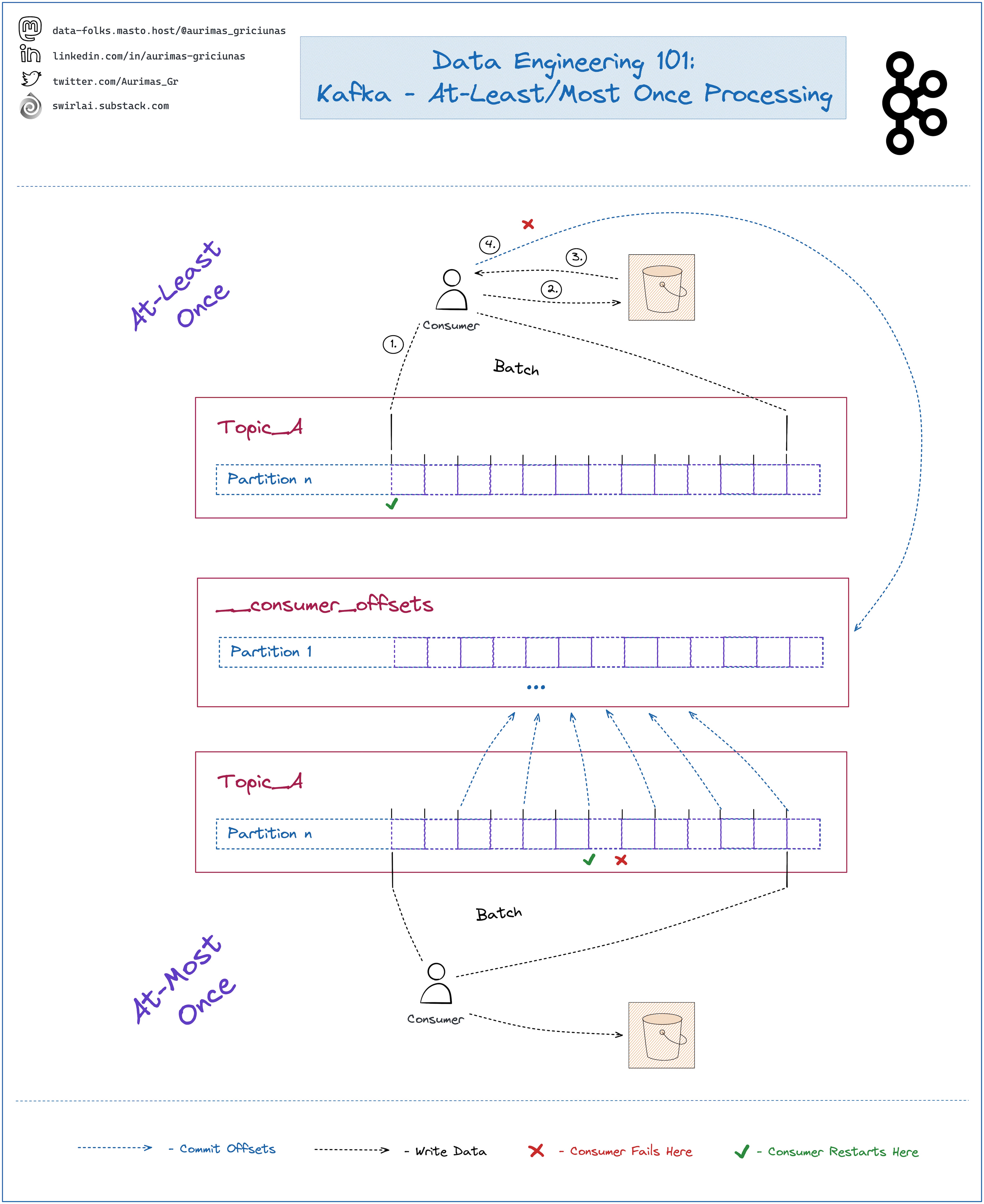
𝗞𝗮𝗳𝗸𝗮 - 𝗔𝘁-𝗟𝗲𝗮𝘀𝘁/𝗠𝗼𝘀𝘁 𝗢𝗻𝗰𝗲 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴.
Kafka is an extremely important Distributed Messaging System to understand as other similar systems are borrowing fundamental concepts from it, last time we covered Reading Data.
Today we talk about At-Least Once and At-Most Once Processing. Why do you need to understand the concept and how it might impact your Stream Processing Application?
𝗦𝗼𝗺𝗲 𝗿𝗲𝗳𝗿𝗲𝘀𝗵𝗲𝗿𝘀:
➡️ Data is stored in Topics that can be compared to tables in Databases.
➡️ Messages in the Topics are called Records.
➡️ Topics are composed of Partitions.
➡️ Each Record has an offset assigned to it which denotes its place in the Partition.
➡️ Clients reading Data from Kafka are called Consumers.
➡️ Consumer Group is a logical collection of clients that read data from a Kafka Topic and share the state.
𝗥𝗲𝗯𝗮𝗹𝗮𝗻𝗰𝗲:
➡️ Consumers commit their state into a Kafka Topic named __consumer_offsets.
➡️ State is denoted by an offset that a Consumer is currently readin at in a given Partition.
➡️ There are different strategies when a commit happens. E.g. every n seconds, on-demand.
➡️ If a Consumer fails or the Consumer Group is restarted, a rebalance will be initiated.
➡️ New Consumers will launch and take place of the old ones.
➡️ Consumers start Reading Data from the last committed state per Partition.
There are different scenarios that can unfold when a Consumer restarts. Let’s take an easy example where you read data from Kafka, buffer it in memory and write a batch into an Object Storage.
𝗔𝘁-𝗟𝗲𝗮𝘀𝘁 𝗢𝗻𝗰𝗲 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴:
➡️ You set offset commit strategy to on-demand.
1️⃣ Read the entire batch.
2️⃣ Serialize and write it into an object storage.
3️⃣ Wait for a successful write.
4️⃣ Commit offsets.
❗️If Consumer fails before commiting offsets after a successful Write new consumer will start from the last committed offset and writes duplicate Data to Object Storage.
✅ This is usually ok for Batch Systems as deduplication is performed during ETL.
𝗔𝘁-𝗠𝗼𝘀𝘁 𝗢𝗻𝗰𝗲 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴:
➡️ You commit offsets in small time intervals without waiting for a successful write to Object Storage.
❗️If Consumer fails before a successful Write into an Object Storage new consumer will start from the last committed offset and it will result in some Data not being processed.
✅ This is usually ok for Loging Systems as loosing small amounts of data does not affect the System in Crytical ways.
MLOps Fundamentals or What Every Machine Learning Engineer Should Know
𝗦𝘁𝗮𝘁𝗶𝗰 𝘃𝘀. 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀.
Understanding the difference between Static and Dynamic features is important when designing Machine Learning Systems because it might Make or Break your efforts in releasing ML Model to production.
𝗪𝗵𝘆? Let’s take a closer look.
𝗦𝘁𝗮𝘁𝗶𝗰 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀.
➡️ These features are generated from data that is not changing frequently.
➡️ The data will most likely resemble dimensions in your data model.
➡️ Data is refreshed on a certain interval. E.g. every 2 hours, every day.
➡️ Example: Inventory properties in your warehouse.
𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗙𝗲𝗮𝘁𝘂𝗿𝗲𝘀.
➡️ Data changes frequently or possibly a context exists temporarily.
➡️ Data will resemble facts or events in your data model.
➡️ Features are generated in real time by aggregating events or facts.
➡️ Example: Number of clicks by the user in the last 2 minutes.
𝗘𝘅𝗮𝗺𝗽𝗹𝗲 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗳𝗼𝗿 𝗺𝗼𝗱𝗲𝗹 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲:
1️⃣ All data is eventually generated in real time, so for this example we collect it either from a CDC stream or Directly emitting events from an application. We push this Data to Kafka Topics.
2️⃣ Data is pushed into an object storage to be loaded into a Data Warehouse.
3️⃣ Data is Loaded into a Data Warehouse to be Transformed.
4️⃣ We model the Data inside of the Data Warehouse and prepare it for Feature Engineering.
5️⃣ We retrieve required data into a ML Pipeline which generates a Model Artifact and pushes it into a Model Registry.
6️⃣ We perform the same Feature Engineering logic and push Batch Features into a Low Latency capable storage like Redis.
7️⃣ If we need Real Time Dynamic Feature - we perform Feature Engineering used in ML Pipeline in Real Time with Flink Application.
8️⃣ We push Generated Features to Redis.
Now we can Deploy the model from Model Registry and source all Features from Redis.
𝗡𝗼𝘁𝗲𝘀.
👉 This example architecture does not include Feature Store in the mix on purpose just to showcase the additional complexities that are created for Dynamic Feature implementation.
👉 Before deciding to use Dynamic Features for Training your Models - Make sure your systems will be able to serve them in Real Time. It might seem simple on paper, but Real Time Feature Engineering Systems are complicated.
👉 Always start with Static Features only and only then increase the complexity gradually.
Having said all of this - Real Time Dynamic Feature implementation is an exciting stepping stone which will give you a competitive advantage in the market!

𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴/𝗦𝗲𝗿𝘃𝗶𝗻𝗴 𝗦𝗸𝗲𝘄.
Let’s look into what Training/Serving Skew is, why it happens in Real Time ML Systems and why you should care.
In previous 𝗠𝗟𝗢𝗽𝘀 𝟭𝟬𝟭 we looked into Static vs. Dynamic Features. The phenomenon of Training/Serving Skew usually happens when Dynamic Features are implemented in systems not yet ready for such added complexity.
Let’s take a closer look into a System that will most likely suffer from Training/Serving Skew.
1️⃣ Data is collected in real time either from a CDC stream or Directly emitting events from an application.
2️⃣ Data is moved to a Data Warehouse.
3️⃣ Data is modeled in the Data Warehouse.
4️⃣ We perform Feature Engineering and use Engineered Features for Training ML models. This will most likely use Python at this point.
5️⃣ We Load Static Features into a low latency storage like Redis to be used in Real Time Model Inference.
At this point we understand that the Model we trained was also using some of Dynamic Real Time Features which we are not able to serve from a Batch System.
6️⃣ We implement preprocessing and Feature Engineering logic for Dynamic Features inside of Product applications. This logic will most likely be implemented in a different programming language that was used in Batch Feature Engineering. E.g. PHP.
Why does this cause issues?
➡️ Feature Engineering is performed using different technologies, even well intentioned implementations can result in different outputs for the same Feature Calculation.
➡️ Production Applications are built by Developers who might or might not have intentions to spend the time needed to understand how Data Scientists think about these transformations in Batch Training Systems.
❗️Differences in how features are derived while doing Batch Training vs. Real Time Inference will cause unexpected Model Predictions that could be disastrous for your business.
How can we catch Training/Serving Skew happening in Real Time Systems?
7️⃣ Log any data used for Feature Engineering and the Engineered Features in Product Applications.
👉 This Data is pushed downstream into Batch Systems where you can apply Feature Engineering process used for Model Training. Compare any differences with Production Applications.
👉 You can do this in Real Time if you are capable of reusing Feature Engineering code used in Batch Systems in Stream Processing.
Having said all this - Feature Stores can save you from Training/Serving Skew, but more on this in future episodes.
