
SAI #06: No Excuses Data Engineering Project Template, Batch Model Deployment - The MLOps Way and more...
Spark - Parallelism, No Excuses Data Engineering Project Template, Model Release Strategies (Real Time), Batch Model Deployment - The MLOps Way.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
No Excuses Data Engineering Project Template.
Spark - Parallelism.
Batch Model Deployment - The MLOps Way.
Model Release Strategies (Real Time).
No Excuses Data Engineering Project Template
I will be bringing the Template back to life and make it part of my Newsletter.
I will use it to explain some of the fundamentals that we are talking about and eventually bring them to life in a tutorial series. Will also extend the template with missing MLOps parts so tune in!
𝗥𝗲𝗰𝗮𝗽:
𝟭. Data Producers - Python Applications that extract data from chosen Data Sources and push it to Collector via REST or gRPC API calls.
𝟮. Collector - REST or gRPC server written in Python that takes a payload (json or protobuf), validates top level field existence and correctness, adds additional metadata and pushes the data into either Raw Events Topic if the validation passes or a Dead Letter Queue if top level fields are invalid.
𝟯. Enricher/Validator - Python or Spark Application that validates schema of events in Raw Events Topic, does some optional data enrichment and pushes results into either Enriched Events Topic if the validation passes and enrichment was successful or a Dead Letter Queue if any of previous have failed.
𝟰. Enrichment API - API of any flavour implemented with Python that can be called for enrichment purposes by Enricher/Validator. This could be a Machine Learning Model deployed as an API as well.
𝟱. Real Time Loader - Python or Spark Application that reads data from Enriched Events and Enriched Events Dead Letter Topics and writes them in real time to ElasticSearch Indexes for Analysis and alerting.
𝟲. Batch Loader - Python or Spark Application that reads data from Enriched Events Topic, batches it in memory and writes to MinIO Object Storage.
𝟳. Scripts Scheduled via Airflow that read data from Enriched Events MinIO bucket, validates data quality, performs deduplication and any additional Enrichments. Here you also construct your Data Model to be later used for reporting purposes.
𝗧𝟭. A single Kafka instance that will hold all of the Topics for the Project.
𝗧𝟮. A single MinIO instance that will hold all of the Buckets for the Project.
𝗧𝟯. Airflow instance that will allow you to schedule Python or Spark Batch jobs against data stored in MinIO.
𝗧𝟰. Presto/Trino cluster that you mount on top of Curated Data in MinIO so that you can query it using Superset.
𝗧𝟱: ElasticSearch instance to hold Real Time Data.
𝗧𝟲. Superset Instance that you mount on top of Trino Querying Engine for Batch Analytics and Elasticsearch for Real Time Analytics.

Data Engineering Fundamentals + or What Every Data Engineer Should Know
𝗦𝗽𝗮𝗿𝗸 - 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺.
While optimizing Spark Applications you will usually tweak two elements - performance and resource utilization.
Understanding parallelism in Spark and tuning it according to the situation will help you in both.
𝗦𝗼𝗺𝗲 𝗙𝗮𝗰𝘁𝘀:
➡️ Spark Executor can have multiple CPU Cores assigned to it.
➡️ Number of CPU Cores per Spark executor is defined by 𝘀𝗽𝗮𝗿𝗸.𝗲𝘅𝗲𝗰𝘂𝘁𝗼𝗿.𝗰𝗼𝗿𝗲𝘀 configuration.
➡️ Single CPU Core can read one file or partition of a splittable file at a single point in time.
➡️ Once read a file is transformed into one or multiple partitions in memory.
𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗶𝗻𝗴 𝗥𝗲𝗮𝗱 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺:
❗️ If number of cores is equal to the number of files, files are not splittable and some of them are larger in size - larger files become a bottleneck, Cores responsible for reading smaller files will idle for some time.
❗️ If there are more Cores than the number of files - Cores that do not have files assigned to them will Idle. If we do not perform repartition after reading the files - the cores will remain Idle during processing stages.
✅ Rule of thumb: set number of Cores to be two times less than files being read. Adjust according to your situation.
𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗶𝗻𝗴 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺:
➡️ Use 𝘀𝗽𝗮𝗿𝗸.𝗱𝗲𝗳𝗮𝘂𝗹𝘁.𝗽𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺 and 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝘀𝗵𝘂𝗳𝗳𝗹𝗲.𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀 configurations to set the number of partitions created after performing wide transformations.
➡️ After reading the files there will be as many partitions as there were files or partitions in splittable files.
❗️ After data is loaded as partitions into memory - Spark jobs will suffer from the same set of parallelism inefficiencies like when reading the data.
✅ Rule of thumb: set 𝘀𝗽𝗮𝗿𝗸.𝗱𝗲𝗳𝗮𝘂𝗹𝘁.𝗽𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘀𝗺 equal to 𝘀𝗽𝗮𝗿𝗸.𝗲𝘅𝗲𝗰𝘂𝘁𝗼𝗿.𝗰𝗼𝗿𝗲𝘀 times the number of executors times a small number from 2 to 8, tune to specific Spark job.
𝗔𝗱𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗡𝗼𝘁𝗲𝘀:
👉 You can use 𝘀𝗽𝗮𝗿𝗸.𝘀𝗾𝗹.𝗳𝗶𝗹𝗲𝘀.𝗺𝗮𝘅𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗕𝘆𝘁𝗲𝘀 configuration to set maximum size of the partition when reading files. Files that are larger will be split into multiple partitions accordingly.
👉 It has been shown that write throughput starts to bottleneck once there are more than 5 CPU Cores assigned per Executor so keep 𝘀𝗽𝗮𝗿𝗸.𝗲𝘅𝗲𝗰𝘂𝘁𝗼𝗿.𝗰𝗼𝗿𝗲𝘀 at or below 5.

MLOps Fundamentals or What Every Machine Learning Engineer Should Know
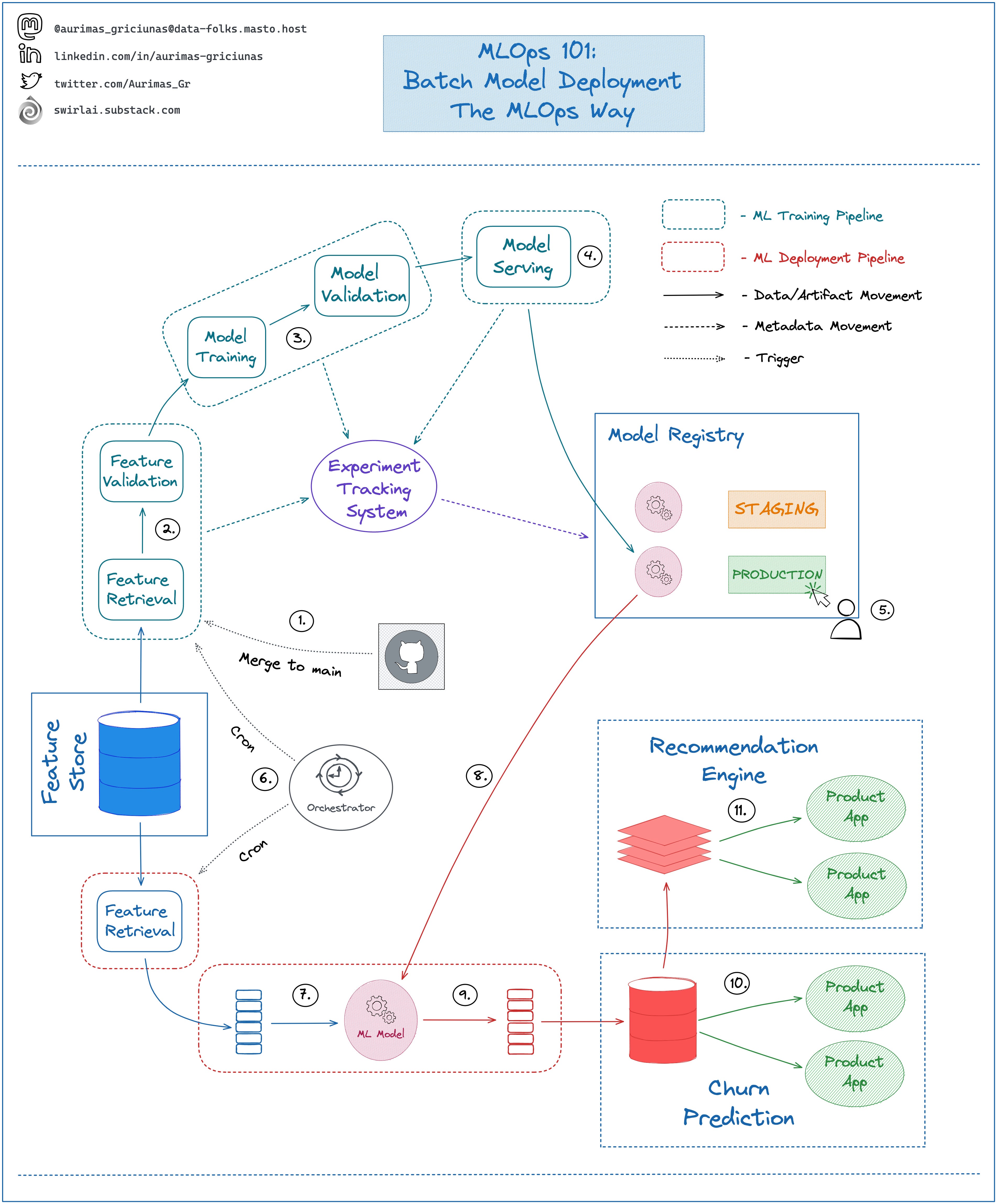
𝗕𝗮𝘁𝗰𝗵 𝗠𝗼𝗱𝗲𝗹 𝗗𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 - 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆.
In one of the 𝗠𝗟𝗢𝗽𝘀 𝟭𝟬𝟭s we looked into Machine Learning Model Deployment Types. As promised we’ll analyze each of them closer.
Today we look into the simplest way to deploy a Model in MLOps Way - Batch.
Let’s zoom in:
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
𝟮: Feature preprocessing stage: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata is saved to an Experiment Tracking System.
𝟯: Model is trained and validated on Preprocessed Data, any Model related metadata is saved to an Experiment Tracking System.
𝟰: If Model Validation passes all checks - Model Artifact is passed to a Model Registry.
𝟱: Experiment Tracking metadata is connected to Model Registry per Model Artifact. Responsible person chooses the best candidate and switches its state to Production. ML Training Pipeline ends here, the Model is served.
𝟲: On a schedule or on demand an orchestrator triggers ML Deployment Pipeline.
𝟳: Feature Data that wasn’t used for inference yet is retrieved from the Feature Store.
𝟴: Model version that is marked as Production ready is pulled from the Model Registry.
𝟵: Model Inference is applied on previously retrieved Feature Set.
𝟭𝟬: Inference results are loaded into an offline Batch Storage.
👉 Inference results can be used directly from Batch Storage for some use cases. A good example is Churn Prediction - you extract users that are highly likely to churn and send promotional emails to them.
𝟭𝟭: If Product Application requires Real Time Data Access we load inference scores to a Low Latency Read Capable Storage like Redis and source from it.
👉 A good example is Recommender Systems - you extract scores for products to be recommended and use them to choose what to recommend.
[𝗜𝗠𝗣𝗢𝗥𝗧𝗔𝗡𝗧]: The Defined Flow assumes that your Pipelines are already Tested and ready to be released to Production. We’ll look into the pre-production flow in future episodes.
𝗣𝗿𝗼𝘀 𝗮𝗻𝗱 𝗖𝗼𝗻𝘀:
✅ Easy to implement Flow.
❗️Inference is performed with delay.
❗️If new customers start using your product there will be no predictions for the stale data points until Deployment Pipeline is run again.
❗️Fallback strategies will be required for new customers.
❗️Dynamic Features are not available.
This is The Way.
𝗠𝗼𝗱𝗲𝗹 𝗥𝗲𝗹𝗲𝗮𝘀𝗲 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀 (𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲).
While deploying Machine Learning Models for Real Time Inference you will have to choose the release strategy that best fits your requirements.
Let’s take a closer look into four popular ones:
𝗦𝗵𝗮𝗱𝗼𝘄 𝗥𝗲𝗹𝗲𝗮𝘀𝗲.
𝙎𝙩𝙚𝙥 𝙤𝙣𝙚: we spin up a new version of ML Model API, clone the traffic that is hitting the old version API and redirect it to the new version. Perform any tests to make sure that the new version of ML Model functions correctly.
𝙎𝙩𝙚𝙥 𝙩𝙬𝙤: once we are sure that ML Model v2 functions as expected we point real traffic to it and decommission the old version of the API.
✅ Safest release strategy as you can test Model behavior on faked traffic not impacting your users directly.
𝗖𝗮𝗻𝗮𝗿𝘆 𝗥𝗲𝗹𝗲𝗮𝘀𝗲.
𝙎𝙩𝙚𝙥 𝙤𝙣𝙚: we spin up a new version of Machine Learning Model API, redirect small amount of traffic to it. We test if the model is functioning as expected.
𝙎𝙩𝙚𝙥 𝙩𝙬𝙤: we increase the percentage of traffic that is pointed to the new Model version and continue monitoring its behavior.
…: we continue increasing the percentage of traffic to the new model until it hits 100%.
✅ Relatively safe as only small amount of users gets exposed to the initial release of new Model version.
❗️The initial percentage of users will be impacted directly.
𝗥𝗲𝗰𝗿𝗲𝗮𝘁𝗲 𝗥𝗲𝗹𝗲𝗮𝘀𝗲.
𝙎𝙩𝙚𝙥 𝙤𝙣𝙚: we shut down the old version of Machine Learning Model API.
𝙎𝙩𝙚𝙥 𝙩𝙬𝙤: we spin up the new version of Machine Learning Model API and redirect all of the traffic to it.
❗️Model is released to the entire population instantly.
❗️Users will experience downtime since it takes time for a new version of Model API to spin up.
❗️Only use if no other option is available to you.
𝗥𝗼𝗹𝗹𝗶𝗻𝗴 𝗨𝗽𝗱𝗮𝘁𝗲 𝗥𝗲𝗹𝗲𝗮𝘀𝗲
As mentioned - Recreate Strategy should not be used if other options are available. A good replacement is Rolling Update Release. Let’s say we have 5 containers running first version of ML API.
𝙎𝙩𝙚𝙥 𝙤𝙣𝙚: we spin up one container hosting version two of ML API and direct traffic to it together with the old versions. We shut down a single container with the old version of API.
𝙎𝙩𝙚𝙥 𝙩𝙬𝙤: we perform the same procedure with one additional container.
…: we continue until only new version remains.
𝗕𝗹𝘂𝗲 𝗚𝗿𝗲𝗲𝗻 𝗥𝗲𝗹𝗲𝗮𝘀𝗲.
𝙎𝙩𝙚𝙥 𝙤𝙣𝙚: we spin up a new version of Machine Learning Model API. No traffic is yet redirected to the new version.
𝙎𝙩𝙚𝙥 𝙩𝙬𝙤: we switch all of the traffic to the new version instantly and decommission the old version of the API.
❗️Model is released to the entire population instantly.
✅ No downtime for the user.
Note that we haven’t mentioned 𝗔/𝗕 𝘁𝗲𝘀𝘁𝗶𝗻𝗴 here as it is not necessarily a release strategy but rather a way to measure business value of different Machine Learning Models against each other. A/B Test release would be usually coupled with a combination of previously mentioned Release Types. More about it next time.

Thanks! This is very insightful!!
What is the best way to tackle a producer that would capture a button click on a website or a login event?
For the batch Loader, what is the frequency that we can get away with without impacting performance if we go with an unstructred data storage such as MinIO or if we opt for structured data storage like Clickhouse?