
SAI #07: Stream Processing Model Deployment - The MLOps Way, Spark - Caching and more...
Why No Excuses Data Engineering Project Template? Stream Processing Model Deployment - The MLOps Way, Model Observability - Analytical Logs, Spark - Caching, Kafka - Data Retention Strategies.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
Why No Excuses Data Engineering Project Template?
Stream Processing Model Deployment - The MLOps Way.
Model Observability - Analytical Logs.
Spark - Caching.
Kafka - Data Retention Strategies.
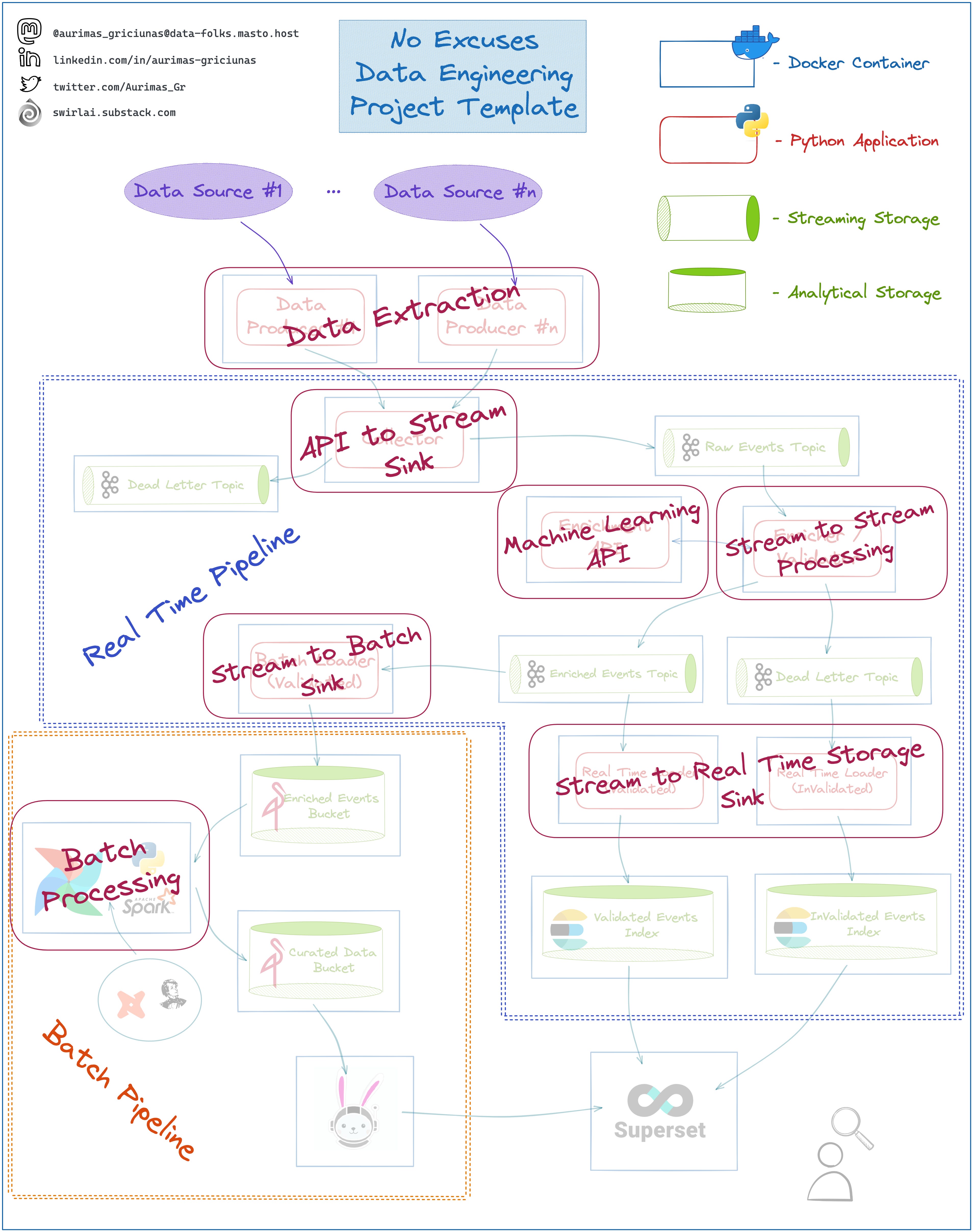
Why No Excuses Data Engineering Project Template?
Some of the reasons why I am excited about 𝗧𝗵𝗲 𝗧𝗲𝗺𝗽𝗹𝗮𝘁𝗲:
➡️ You are most likely to find similar setups in real life situations. Seeing something like this implemented signals a relatively high level of maturity in Organizations Data Architecture
➡️ You can choose to go extremely deep or light on any of the architecture elements when learning and studying The Template.
➡️ We will cover most of the possible 𝗗𝗮𝘁𝗮 𝗧𝗿𝗮𝗻𝘀𝗽𝗼𝗿𝘁𝗮𝘁𝗶𝗼𝗻 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀:
👉 𝗗𝗮𝘁𝗮 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀 - Data extraction from external systems. You can use different technologies for each of the Applications.
👉 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗼𝗿 - API to Collect Events. Here you will acquire skills in building REST/gRPC Servers and learn the differences.
👉 𝗘𝗻𝗿𝗶𝗰𝗵𝗺𝗲𝗻𝘁 𝗔𝗣𝗜 - API to expose data Transformation/Enrichment capability. This is where we will learn how to expose a Machine Learning Model as a REST or gRPC API.
👉 𝗘𝗻𝗿𝗶𝗰𝗵𝗲𝗿/𝗩𝗮𝗹𝗶𝗱𝗮𝘁𝗼𝗿 - Stream to Stream Processor. Extremely important, as here we will enrich Data with ML Inference results in real time and more importantly ensure that 𝗦𝗰𝗵𝗲𝗺𝗮 𝗽𝗮𝗿𝘁 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 is respected between Producers and Consumer of the Data.
👉 𝗕𝗮𝘁𝗰𝗵 𝗟𝗼𝗮𝗱𝗲𝗿 - Stream to Batch Storage Sink. Here we will learn object storage and how to effectively serialize data so that downstream Batch Processing jobs would be most efficient and performant.
👉 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗟𝗼𝗮𝗱𝗲𝗿 - Stream to Real Time Storage Sink. We will learn how to use Kafka Consumers to write data to Real Time Storage and observe Data coming in Real time through Superset Dashboards.
👉 𝗕𝗮𝘁𝗰𝗵 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 - This is a world by itself and will have an entire section dedicated to it. We will look into concepts such as: difference between Data Warehouse, Data Lake and Data Lakehouse, what are Bronze, Silver and Golden layers in Data Lakehouse Architecture, what are SLAs, how can you leverage DBT, internals and best practices of Airflow and much more.
➡️ Everything will be containerised - you can easily use the containers you've built to 𝗗𝗲𝗽𝗹𝗼𝘆 𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀 𝘁𝗼 𝘁𝗵𝗲 𝗖𝗹𝗼𝘂𝗱.
➡️ The Template is Dynamic - as mentioned last time, in the process we will add the entire MLOps Stack to The Template. We can change it in many other ways as long as the change has a reason behind it.
I am really excited for this journey to 𝗟𝗲𝘃𝗲𝗹𝗶𝗻𝗴 𝗨𝗽. 𝗜𝗳 𝘆𝗼𝘂 𝗮𝗿𝗲 𝗮𝘀 𝘄𝗲𝗹𝗹 - 𝘁𝘂𝗻𝗲 𝗶𝗻!
MLOps Fundamentals or What Every Machine Learning Engineer Should Know
𝗦𝘁𝗿𝗲𝗮𝗺 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 𝗗𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 - 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆.
Last week we analyzed the easiest way to deploy ML Model - Batch.
Today we look into how a deployment procedure could look like for a model embedded into a Stream Processing Application - The MLOps Way.
𝗟𝗲𝘁’𝘀 𝘇𝗼𝗼𝗺 𝗶𝗻:
𝟭: Version Control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
𝟮: Feature Preprocessing: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata is saved to the Experiment Tracking System.
𝟯: Model is trained and validated on Preprocessed Data, Model related metadata is saved to the Experiment Tracking System.
𝟰.𝟭: If Model Validation passes all checks - Model Artifact is passed to a Model Registry.
𝟰.𝟮: Model is packaged into a container together with the Flink Application that will perform the inference. Model is Served.
𝟱.𝟭: Experiment Tracking metadata is connected to Model Registry per Model Artifact. Responsible person chooses the best candidate and switches its state to Production.
𝟱.𝟮: A web-hook is triggered by the action and a new version of containerised Flink Application is Deployed.
𝟲: Flink Application sources events on which Inference should be performed from one or more Kafka Topics in Real Time.
𝟳: Feature Data is retrieved from Real Time Serving API of the Feature Store.
𝟴: After Inference is performed on the event - it is outputted into Inference Kafka Topic.
𝟵: Product Applications subscribe to the Topic and perform actions on Events coming in Real Time.
𝟭𝟬: Inference results can be loaded into a Low Latency Read Capable Storage like Redis and sourced from it if reacting to each event is optional.
𝟭𝟭: Input Data can be fed to the Feature Store for Real Time Feature Computation.
𝟭𝟮: An orchestrator schedules Model Retraining.
𝟭𝟯: ML Models that run in production are monitored. If Model quality degrades - retraining can be automatically triggered.
[𝗜𝗠𝗣𝗢𝗥𝗧𝗔𝗡𝗧]: The Defined Flow assumes that your Pipelines are already Tested and ready to be released to Production. We’ll look into the pre-production flow in future episodes.
𝗣𝗿𝗼𝘀 𝗮𝗻𝗱 𝗖𝗼𝗻𝘀:
✅ Inference applied once and can be used by multiple consumers.
✅ Inference results can be replayed.
✅ Dynamic Features - available.
❗️Stream Processing is Complicated.
𝗧𝗵𝗶𝘀 𝗶𝘀 𝗧𝗵𝗲 𝗪𝗮𝘆.

𝗠𝗼𝗱𝗲𝗹 𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝗯𝗶𝗹𝗶𝘁𝘆 - 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝗮𝗹 𝗟𝗼𝗴𝘀.
Machine Learning Observability System is where you will continuously monitor ML Application Health and Performance.
One of the components of such a system is Analytical Logging.
What are Analytical Logs/Events and why should you care as a Machine Learning Engineer?
𝗟𝗲𝘁’𝘀 𝘇𝗼𝗼𝗺 𝗶𝗻:
You track Analytical Logs of your Applications - both Product Applications and your ML Services. These Logs will include data like:
➡️ What prediction was made by ML Service.
➡️ What action was performed by the Product Application after receiving the Inference result.
➡️ What was the feature input to the ML Service.
➡️ …
Example log collection architecture that you might find in the real world:
Both Product Applications and ML Services are deployed in Kubernetes. There are usually two ways to collect Analytical Logs:
𝟭: There is a fluentD sidecar container running in each Application Pod. Applications are sending logs to these sidecars which then forward them to a Kafka Topic.
𝟭.𝟭: Applications can send the logs directly to a Kafka Topic.
𝗕𝗮𝘁𝗰𝗵 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀:
This is where you will analyze ML model performance against business objectives and perform A/B Testing Experiment analysis.
𝟮: After logs are collected they are forwarded to object storage.
𝟯: Additional Data is collected from internal databases to be used together with ML Analytical Logs.
👉Data includes financial numbers - not all business metrics are defined by actions like click through rate, some models will be evaluated against financial results that might be reaching Data Systems on a schedule. E.g. Daily.
𝟰: Data is loaded into a Data Warehouse for further modeling.
𝟱: Modeled and Curated Data is used for Analytical purposes and A/B Testing.
𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀:
Some features for inference will be calculated on the fly due to latency requirements. Here you can identify any remaining Training/Serving Skew.
𝟲: Flink Application reads Data from Kafka, performs windowed Transformations and Aggregations.
𝟳: The Application alerts directly if any thresholds are breached.
𝟴: The Application forwards some data downstream to a Kafka Topic.
𝟵: Data is loaded into a low latency query capable storage like Redis or ElasticSearch or
𝟭𝟬: Downstream Applications can subscribe to the Kafka Topic and react to any incoming data or
𝟭𝟭: Read Real Time Data from Redis or ElasticSearch.

Data Engineering Fundamentals + or What Every Data Engineer Should Know
𝗦𝗽𝗮𝗿𝗸 - 𝗖𝗮𝗰𝗵𝗶𝗻𝗴.
Caching in Spark is an Application optimization technique that allows you to persist intermediate partitions to be reused in the computational DAG downstream.
𝗥𝗲𝗳𝗿𝗲𝘀𝗵𝗲𝗿:
➡️ Spark Jobs are executed against Data Partitions.
➡️ After each Transformation - number of Child Partitions will be created.
➡️ Each Child Partition will be derived from Parent Partitions and will act as Parent Partition for future Transformations.
𝗟𝗮𝘇𝘆 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻.
Spark uses Lazy Evaluation to efficiently work with Big Data. It means that any transformations on Data are first planned in the form of logical compute DAG and only on certain conditions executed.
➡️ There are two types of procedures that can be applied against Data Partitions.
👉Transformations - a transformation that is defined and evaluated as part of Spark Job DAG.
👉Actions - an action which triggers Spark Job DAG execution.
𝗧𝗼 𝘂𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝗯𝗲𝗻𝗲𝗳𝗶𝘁𝘀 𝗼𝗳 𝗖𝗮𝗰𝗵𝗶𝗻𝗴 𝗯𝗲𝘁𝘁𝗲𝗿 - 𝗹𝗲𝘁’𝘀 𝗹𝗼𝗼𝗸 𝗶𝗻𝘁𝗼 𝗮𝗻 𝗲𝘅𝗮𝗺𝗽𝗹𝗲:
Let's say we have two input Data Frames: df_1 and df_2.
1️⃣ We read them from parquet files.
2️⃣ Join them on a specific column.
3️⃣ Write the joint dataframe to disk.
4️⃣ Group and sum the joint dataframe and write it to disk.
5️⃣ Filter the joint dataframe and write it to disk.
𝗪𝗿𝗶𝘁𝗲 is the action that will trigger DAG execution.
❗️ If we don’t apply Caching - steps 1️⃣ and 2️⃣ will be executed for each action that triggers DAG execution.
✅ If we apply caching, the intermediate result of steps 1️⃣ and 2️⃣ can be persisted and reused for further steps.
❗️ Cache itself is an action and is not without costs.
❗️ Cached Data Frames occupy space in Memory or on Disk.
𝗥𝘂𝗹𝗲 𝗼𝗳 𝘁𝗵𝘂𝗺𝗯: Use Cache if the action of caching itself requires less resources than duplicated work without Cache procedure.
You can use Cache by calling either .𝗰𝗮𝗰𝗵𝗲() or .𝗽𝗲𝗿𝘀𝗶𝘀𝘁() methods on your dataframe.
➡️ .𝗽𝗲𝗿𝘀𝗶𝘀𝘁() can be configured to save the intermediate data either in memory, disk or a mix of both options. Also it can be configured to serialize or not serialize the persisted data.
➡️ .𝗰𝗮𝗰𝗵𝗲() uses persist under the hood with it configured to save the data in memory only.

𝗞𝗮𝗳𝗸𝗮 - 𝗗𝗮𝘁𝗮 𝗥𝗲𝘁𝗲𝗻𝘁𝗶𝗼𝗻 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀.
Kafka is an extremely important Distributed Messaging System to understand as other similar systems are borrowing fundamental concepts from it, last time we covered At-Least Once and At-Most Once Processing.
Today we look into Data Retention Strategies for your Kafka Topics.
𝗦𝗼𝗺𝗲 𝗿𝗲𝗳𝗿𝗲𝘀𝗵𝗲𝗿𝘀:
➡️ Data is stored in Topics that can be compared to tables in Databases.
➡️ Messages in the Topics are called Records.
➡️ Topics are composed of Partitions.
➡️ Each Record has an offset assigned to it which denotes its place in the Partition.
➡️ Clients writing Data to Kafka are called Producers.
➡️ Each Partition is and behaves as a Write Ahead Log - Producers always write to the end of a Partition.
Why do you need to understand Data Retention and how it might impact your Stream Processing Application?
➡️ Unlike a database - Kafka is usually used to pipe enormous amounts of Data hence the Data is not stored indefinitely.
➡️ Since Data is eventually Deleted, given a restart of your Stream Processing Application - it might not find all of the previously seen data.
There are generally two strategies to implement Data Retention in Kafka - Deletion and Log Compaction, 𝗹𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
➡️ Data Retention Strategies are enabled by setting 𝗹𝗼𝗴.𝗰𝗹𝗲𝗮𝗻𝘂𝗽.𝗽𝗼𝗹𝗶𝗰𝘆 to 𝗱𝗲𝗹𝗲𝘁𝗲 or 𝗰𝗼𝗺𝗽𝗮𝗰𝘁.
➡️ This is set on a Broker level but can later be configured per Topic.
𝗗𝗲𝗹𝗲𝘁𝗶𝗼𝗻:
➡️ Each Partition in a Topic is made of Log Segments.
➡️ Log Segments are closed on a certain condition. It can be on a segment reaching a certain size or it being open for a certain time.
➡️ Closed Log Segments are marked for deletion if the difference between current time and when the segment was closed is more than one of: 𝗹𝗼𝗴.𝗿𝗲𝘁𝗲𝗻𝘁𝗶𝗼𝗻.𝗺𝘀, 𝗹𝗼𝗴.𝗿𝗲𝘁𝗲𝗻𝘁𝗶𝗼𝗻.𝗺𝗶𝗻𝘂𝘁𝗲𝘀, 𝗹𝗼𝗴.𝗿𝗲𝘁𝗲𝗻𝘁𝗶𝗼𝗻.𝗵𝗼𝘂𝗿𝘀. If all of them are set, a more granular option will be used.
➡️ After being marked for deletion the segments will be cleaned up by background processes.
❗️If a Topic is configured to not close Log Segments in short enough time - the data could be never cleaned up as the segments would not close.
𝗟𝗼𝗴 𝗖𝗼𝗺𝗽𝗮𝗰𝘁𝗶𝗼𝗻:
➡️ This Strategy only works on Keyed Partitions.
➡️ Topics are compacted by retaining only the latest written record per key.
➡️ Compaction is performed by the background process consisting of a pool of threads called Log Cleaner.
