
SAI #09: Kafka - Use Cases, Pre Machine Learning Data Quality and more...
Pre Machine Learning Data Quality, Kafka - Use Cases, Data Contracts and Outbox Tables, The Collector.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
Pre Machine Learning Data Quality.
Kafka - Use Cases.
Data Contracts and Outbox Tables.
No Excuses Data Engineering Template: The Collector.
Data Engineering Meets MLOps
𝗣𝗿𝗲 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗤𝘂𝗮𝗹𝗶𝘁𝘆.
We have already seen that the Data Lifecycle before it even reaches the Machine Learning Stage is highly complex. How can we ensure the quality of Data that is fed into ML Models using Data Contract enforcement? Let’s take a closer look:
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀.
Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 𝗵𝗼𝗹𝗱 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝗻𝗼𝗻-𝗲𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗹𝗶𝘀𝘁 𝗼𝗳 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮:
👉 Schema Definition.
👉 Schema Version.
👉 SLA metadata.
👉 Semantics.
👉 Lineage.
👉 …
𝗦𝗼𝗺𝗲 𝗣𝘂𝗿𝗽𝗼𝘀𝗲𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
➡️ Improve scalability of your Data Systems.
➡️ …
𝗘𝘅𝗮𝗺𝗽𝗹𝗲 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗘𝗻𝗳𝗼𝗿𝗰𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀:
𝟭: Schema changes are implemented using version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
Applications push generated Data to Kafka Topics.
𝟮: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
𝟮.𝟭: Raw Data Topics for CDC streams.
𝟯: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry.
𝟰: Data that does not meet the contract is pushed to Dead Letter Topic.
𝟱: Data that meets the contract is pushed to Validated Data Topic.
𝟲: Data from the Validated Data Topic is pushed to object storage for additional Validation.
𝟳: On a schedule Data in the Object Storage is validated against additional SLAs contained in Data Contract Metadata and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
𝟴: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering.
𝟴.𝟭: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
𝟵: Data of High Quality is used in Machine Learning Training Pipelines.
𝟭𝟬: The same Data is used for Feature Serving in Inference.

Data Engineering Fundamentals + or What Every Data Engineer Should Know
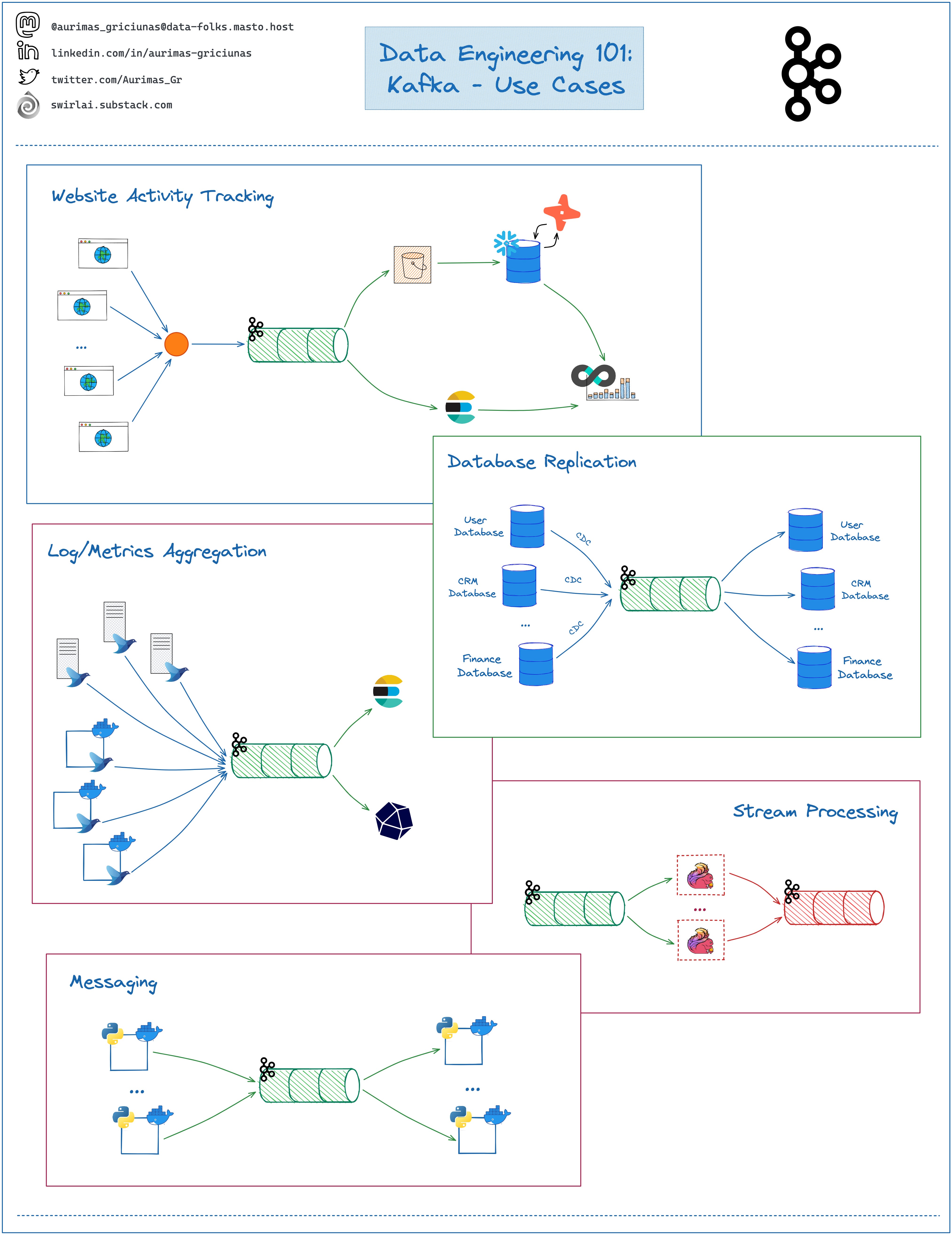
𝗞𝗮𝗳𝗸𝗮 - 𝗨𝘀𝗲 𝗖𝗮𝘀𝗲𝘀.
We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer?
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
𝗪𝗲𝗯𝘀𝗶𝘁𝗲 𝗔𝗰𝘁𝗶𝘃𝗶𝘁𝘆 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴.
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
➡️ These events are forwarded to the downstream Analytical systems or processed in Real Time.
➡️ Kafka is used as an initial buffer as the Data amounts are usually big and Kafka guarantees no message loss due to its replication mechanisms.
𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲 𝗥𝗲𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻.
➡️ Database Commit log is piped to a Kafka topic.
➡️ The committed messages are executed against a new Database in the same order.
➡️ Database replica is created.
𝗟𝗼𝗴/𝗠𝗲𝘁𝗿𝗶𝗰𝘀 𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗶𝗼𝗻.
➡️ Kafka is used for centralized Log and Metrics collection.
➡️ Daemons like FluentD are deployed in servers or containers together with the Applications to be monitored.
➡️ Applications send their Logs/Metrics to the Daemons.
➡️ The Daemons pipe Logs/Metrics to a Kafka Topic.
➡️ Logs/Metrics are delivered downstream to storages like ElasticSearch or InfluxDB for Log/Metrics discovery respectively.
➡️ This is also how you would track your IoT Fleets.
𝗦𝘁𝗿𝗲𝗮𝗺 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴.
➡️ This is usually coupled with ingestion mechanisms already covered.
➡️ Instead of piping Data to a certain storage downstream we mount a Stream Processing Framework on top of Kafka Topics.
➡️ The Data is filtered, enriched and then piped to the downstream systems to be further used according to the use case.
➡️ This is also where one would be running Machine Learning Models embedded into a Stream Processing Application.
𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴.
➡️ Kafka can be used as a replacement for more traditional messaging brokers like RabbitMQ.
➡️ Kafka has better durability guarantees and is easier to configure for several separate Consumer Groups to consume from the same Topic.
❗️Having said this - always consider the complexity you are bringing with introduction of a Distributed System. Sometimes it is better to just use traditional frameworks.
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 𝗮𝗻𝗱 𝗢𝘂𝘁𝗯𝗼𝘅 𝗧𝗮𝗯𝗹𝗲𝘀.
We already established that Data Contracts are to become one of the key topics for the upcoming years.
Today let’s look into what Outbox Tables in Operational Service Level Databases are and how we can leverage them in implementing Data Contracts.
𝗧𝗵𝗲 𝗣𝗿𝗼𝗯𝗹𝗲𝗺.
➡️ Operational Product Databases are modeled around Services that are coupled to them.
➡️ Usually Data Warehouses are fed with Raw events coming through a CDC stream that mirrors Operational Data Model.
➡️ This Data Model Does not necessarily represent intended Semantic Meaning for Analytical Data Model.
➡️ Data is additionally Transformed and modeled in the Data Warehouse to make it fit Analytical purposes.
❗️Any Change in the Service Operational Data Model might and most likely will break downstream Analytical processes depending on the data.
𝗦𝗼𝗹𝘂𝘁𝗶𝗼𝗻.
➡️ Introduction of Outbox Tables for Analytical Purposes.
➡️ Any updates to Operational Database are also made to the Outbox Table in the same Transaction.
❗️It is extremely important to do this in a single transaction to retain State Consistency of the Data.
➡️ Entities in the Outbox Table Payload field are modeled separately to fit Semantic Meaning for Analytical Data Model.
➡️ CDC is performed against the Outbox Table instead of Operational Tables.
➡️ There can be multiple or a single Outbox Table that contains all of the Data intended for Analytical Purposes.
➡️ Outbox Table will also include additional metadata like Schema Version so we can validate the correctness of the payload in the downstream systems or a Kafka Topic it should be routed to.
✅ In this way we decouple Operational Model From Analytical model and any Changes done to the Operational Model do not propagate to the Downstream Analytical Systems.

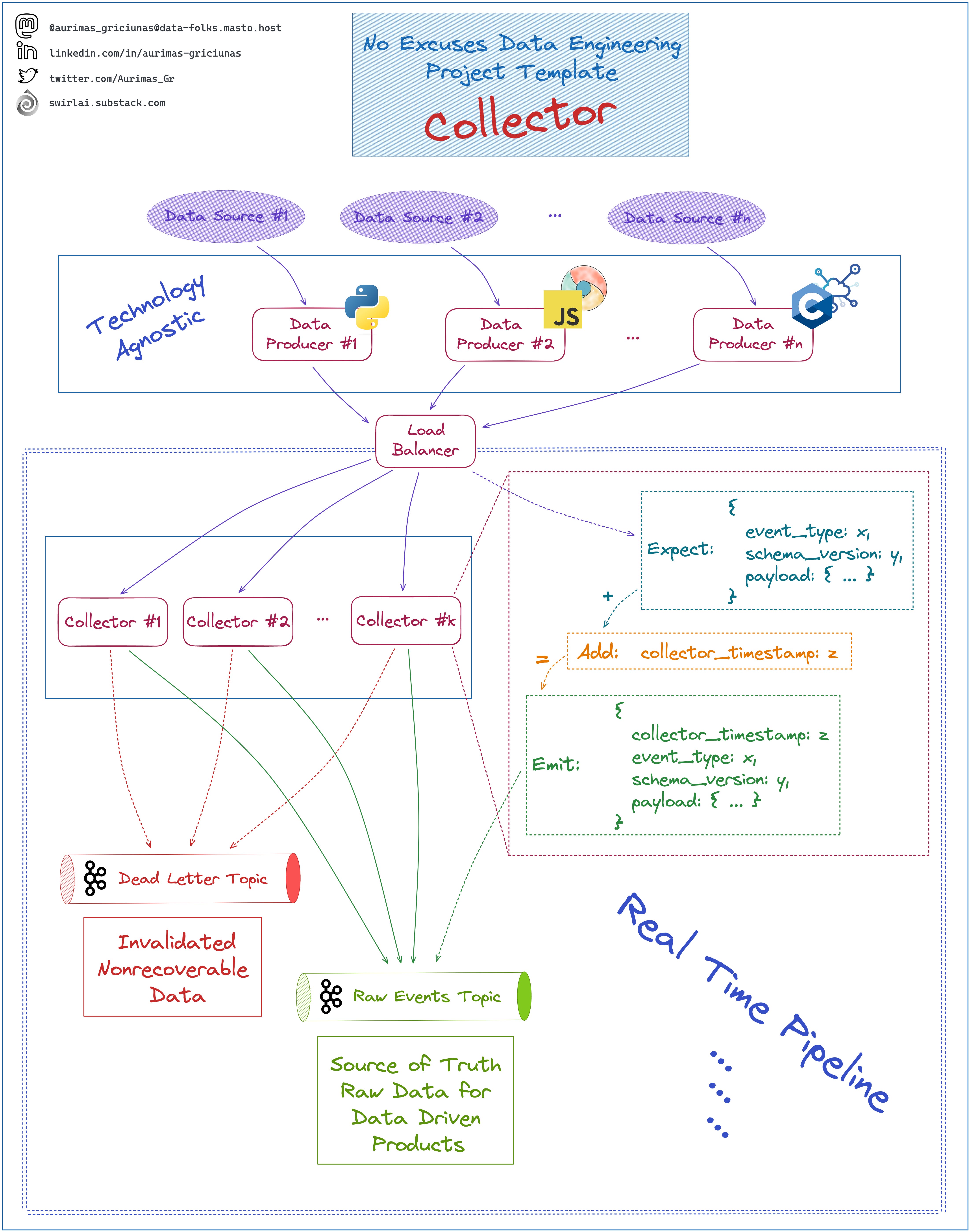
No Excuses Data Engineering Project Template: The Collector
What is the function of 𝗧𝗵𝗲 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗼𝗿?
Why and when does it even make sense to have separate 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗼𝗿 microservice in your Data Engineering Pipeline?
𝗟𝗲𝘁’𝘀 𝘇𝗼𝗼𝗺 𝗶𝗻:
➡️ Data Collectors act as a Gateway to validate the correctness of Data entering your System. E.g. we could check for top level field existence that would allow us to validate 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 later on in the Downstream Processes.
➡️ Collectors add additional metadata to the events. E.g. collector timestamp, collector process id etc.
➡️ By making The Collector a separate service we decouple Data Producers from Collectors. By doing this we allow implementation of the Producers using different Technologies enabling wider collaboration.
➡️ Consequently, Data Producers can be deployed in different parts of the 𝗡𝗲𝘁𝘄𝗼𝗿𝗸 𝗧𝗼𝗽𝗼𝗹𝗼𝗴𝘆. E.g. They can be a JS app running in a browser or a fleet of 𝗜𝗢𝗧 devices emitting events to a public Load Balancer. Or it could be a Python backend server delivering ML Predictions in a private network.
➡️ Collectors are the most sensitive part of your pipeline - you want to do as little processing and data manipulation here as possible. Usually, any errors here would result in permanent 𝗗𝗮𝘁𝗮 𝗟𝗼𝘀𝘀. Once the data is already in the System you can always retry additional computation.
➡️ Hence, we decouple Collectors from any additional Schema Validation or Enrichment of the 𝗣𝗮𝘆𝗹𝗼𝗮𝗱 and move that down the stream.
➡️ You can scale collectors independently so they are able to take any Incoming Data Amount.
➡️ Collectors should also implement a buffer. If Kafka starts misbehaving - Data would be buffered in memory for some time until Kafka Cluster recovers.
➡️ Data Output by the Collectors is your 𝗥𝗮𝘄 𝗦𝗼𝘂𝗿𝗰𝗲 𝗼𝗳 𝗧𝗿𝘂𝘁𝗵 𝗗𝗮𝘁𝗮. You will not be able to acquire this Data again - you want Raw data to be treated differently, i.e. have a longer lifecycle and most likely archive it in a low cost object storage. This Data should not be manipulated in any way, that is a task for Downstream Systems.
When does it make sense to have a 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗼𝗿 microservice?
👉 Your Data is in event/log form.
👉 Your Data is composed of many different event types.
👉 Your Data is not saved in backend databases. If it is - use Change Data Capture instead.
❗️You will only be able to use gRPC for events delivered from your Private Network. For Public Network you would use REST.
Hi! Thanks for really good content! Would you mind sharing which tool you use to make your illustrations / flow charts?