
SAI #14: Data Latency in ML Systems.
Data Latency in ML Systems, MLOps Maturity Level 2, DBMS Architecture.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week we cover the following topics:
How do we define Data Latency in ML Systems when serving Online predictions?
What is MLOps Maturity Level 2 and how do we move there from Level 1?
How are DBMS (Database Management Systems) Architected?
Bonus: Moving to MLOps Engineering from other roles.
How do we define Data Latency in ML Systems when serving Online predictions?
There are two main components you can think about when it comes to Data Latency:
➡️ How Recent is the Data that the Model being served was trained on.
➡️ How Recent are the Features that are being fed to the Model that is making Online predictions.
Generally you can split maturity of ML System Architectures into 4 levels.
Level 1:
1: Offline Features from Data Warehouse are used to train ML Models on a schedule.
2: Inference is applied on new incoming Features on a schedule.
3: Inference results are uploaded into a low latency Prediction Store like Redis.
4: Product Applications source predictions from the Prediction Store.
5: New Features are piped from Product Apps back to the DWH.
👉 Model Data Latency last time the Model was trained.
👉 Feature Latency equals to the last time the inference was applied + what was the Feature Latency at that point in time.

Level 2:
6: Data Warehouse is replaced by a Feature Store which is used for retrieving offline features for Model Training and Feature Serving in Real Time.
7: Prediction Store is replaced by a ML Model exposed as a Web Service that retrieves Features in Real Time from the Feature Store.
8: Product Applications request Inference directly from the Web Service.
9: New Features are piped from Product Apps back to the Feature Store. Upload performed via Batch Feature Ingestion API on a schedule.
👉 Model Data Latency equals to Last time the model was trained.
👉 Feature Latency is decoupled and equals to when was the last time the Features were ingested into the Feature Store.
Level 3:
10: New Features that are being piped from Product Apps back to the Feature Store are Transformed (by e.g. Flink Application) and Ingested in real time via Real Time Feature Ingestion API.
👉 Model Data Latency equals to Last time the model was trained.
👉 Feature Latency becomes Near to Real Time.
Level 4:
11: Online Model Training is introduced.
12: ML Models are continuously trained in Real Time on new incoming data and continuously redeployed in production after ensuring stability and correctness.
👉 Both Model and Feature Latency becomes Near to Real Time
❗️ Having said this, It is always a good idea to start at Level 1. With the current industry state you will very rarely move beyond Level 2.
❗️ Industry is moving forward and Real time Feature Processing is becoming attainable for more companies so you will see a lot more Level 3s in the future.
What is MLOps Maturity Level 2 and how do we move there from Level 1?
We have already established that successful Level 1 MLOps Automation (by GCP) achieves Continuous Training (CT) supported by:
➡️ Orchestration of ML Pipelines.
➡️ Introduction of strict Data and Model Validation steps in the ML Pipeline.
➡️ Introduction of ML Metadata Store.
➡️ Different Pipeline triggers in production.
➡️ Optional introduction of Feature Store.
Level 2 MLOps Automation Level is achieved by exposing ML Pipelines to CI/CD processes. By doing so any handover between ML Engineers and Ops is eradicated and true MLOps is achieved. Let’s look into such process:
1️⃣ ML Pipelines are orchestrated but you can trigger them from the experimentation environment - Notebooks.
👉 Here you iterate on new model versions and ideas.
👉 You can experiment on curated and raw data, however it will not be available in pre-prod environment so any data used by the Pipeline should end up in Feature Store before triggering CI step.
✅ Output of this stage - code of ML Pipeline in the Source Repository.
2️⃣ Continuous Integration Step for ML Pipelines.
👉 This step is triggered each time you push Pipeline code to a specific git branch. Usually it would be a release* branch.
👉 Pipeline components are unit tested.
👉 Pipeline components are integration tested (do components integrate correctly with each other and external systems like Feature Store etc.)
✅ Output - ML Pipeline packages and artifacts.

3️⃣ Continuous Delivery/Deployment Step for ML Pipelines.
👉 This step usually contains several stages.
👉 After merge to release branch a Pipeline is deployed and a Model is built and Tested for performance in pre-prod (User Acceptance Test) environments. The deployment is fully automated here.
👉 After testing the code is merged into main branch and the Model is deployed to production environments. This is done manually in most cases.
👉 There could be more environments involved.
4️⃣ Automated triggering of the ML Pipeline.
👉 Ad-hoc.
👉 Cron.
👉 Arrival of New Data.
5️⃣ ML Model Continuous Delivery.
👉 This step deploys a Model Service trained by ML Pipeline.
✅ Output - ML Model Service deployed in different environments.
6️⃣ Performance Monitoring.
👉 Here we collect live performance metrics.
✅ Output - a trigger to relaunch ML Pipeline if any metrics degrade.
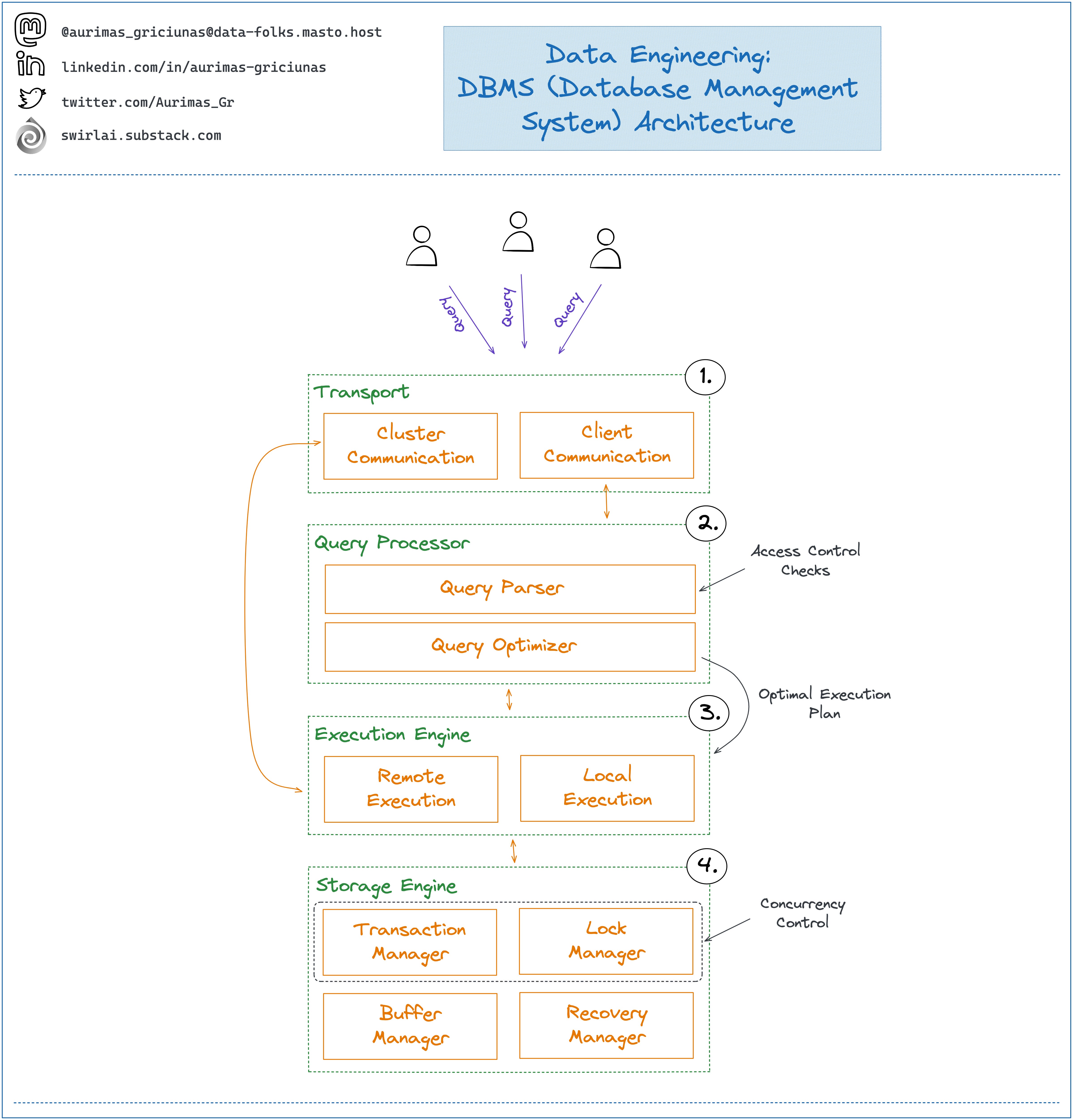
How are DBMS (Database Management Systems) Architected?
In general the DBMS is a Software System that allows a user to manage data more efficiently. It provides APIs to store, retrieve, update and delete Data stored in the Database.
As Data Engineers we sometimes take complex systems for granted but it is worth understanding at least how the general architecture of DBMSes looks like so that we can participate in discussions of choosing the right one for our use case.
Database Management Systems will be architected differently, but you are very likely to find the following logical building blocks (regardless if they are coupled via code):
1️⃣ Transport Layer - responsible for communication with clients. Receives requests in the form of queries. Also responsible for communication with other Nodes in the cluster. Passes the received query to the Query Processor.
2️⃣ Query Processor - consists of two subsystems:
👉 Query Parser - parses, validates and interprets the received Query. Access control checks are also performed here as the more granular ones require an interpreted query.
👉 Query Optimizer - constructs the most optimal Query Execution Plan leveraging internal statistics.
3️⃣ Execution Engine - carries out the Query Execution Plan, aggregates results of local and remote operations.
4️⃣ Storage Engine - interacts with the file system on the OS level, executes local queries. Consists of several subsystems:
👉 Transaction Manager - responsible for scheduling transactions.
👉 Lock Manager - locks database objects so that multiple transactions can’t modify the same data simultaneously preventing violation of physical data integrity.
❗️Transaction and Lock Managers together are responsible for Concurrency Control.
👉 Buffer Manager - caches data pages in memory to reduce number of times physical storage is accessed. Cached pages can be returned if requested as long as the on-disk representation has not been changed manually without syncing with the page cache.
👉 Recovery Manager - responsible for restoring database system state in case of failure and maintaining write-ahead transaction log used for recovery.
Popular types of DBMSes:
➡️ Relational.
➡️ In-memory.
➡️ Hierarchical.
➡️ Network.
➡️ …
Bonus: Moving to MLOps Engineering from other roles.
Usually MLOps Engineers are people tasked with building out the ML Platform in the organization.
This means that the skill set required is very broad - naturally very few people start off with the full set of skills you would need to brand yourself as a MLOps Engineer. This is why I would not choose this role if you are just entering the market.
However, you can get into the role from various sides once you already have some experience. Here are some examples - If you currently are:
ML Engineer: this is the easiest one since if you are currently successful in your role you might already have skills that are needed to become a successful MLOps Engineer. What you will need to do though is switch from an execution to a service role. So the main shift is mental rather than technical.

Infrastructure/Cloud Engineer: you are most likely good with infrastructure architecture, IaaC, Cloud Services etc. These are all crucial skills to have in the ML platform team.
DevOps Engineer: you have probably mastered CI/CD infrastructure and very well know how to template and automate things, how to increase developer velocity - each of these being a necessity to become MLOps engineer.
Software Engineer: There are a number of areas that software engineering skills could be leveraged in ML platform team, e.g. coding up clean interfaces, backend services, UIs to be used by platform adopters. On top of that, you are probably as good with CI/CD infrastructure as most DevOps engineers are.
In any case - be prepared to learn a lot as MLOps Engineers are generalists and it usually takes a lot of time to acquire the full-stack.
Along my journey to become an ML Engineer (with a MLOps mentality) I performed several of these roles.
Thesis Internship: Data Scientist role
First job: Cloud Engineer
Second job: DevOps Engineer
Third job : ML Engineer (with an MLOps mentality)