
SAI #16: Feature vs. Concept Drift.
Introducing SwirlAI Data Talent Collective, Feature vs. Concept Drift, Website Activity Tracking System Design.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week in the Newsletter:
Introducing SwirlAI Data Talent Collective.
Feature vs. Concept Drift.
Website Activity Tracking System Design.
Introducing SwirlAI Data Talent Collective.
We are all facing uncertainty when it comes to the global economic condition. Recent tech layoffs devastated many and I decided to wait no more and try to help the community anyway I can.
Today I am announcing the first one of the many to come community initiatives this year - the first Data Focused Talent Collective.
How does it work?
1: Community members apply to join the collective. I curate the applications and act as a gateway.
❗️You can apply in private or public mode - if you are in private mode your identity will be hidden and only revealed if you accept to be approached by a Collective Partner.
2: Once approved and placed into collective - you are in and available for contact by Collective Partners
3: Job Board filled with Data positions (focussed on Europe, US and remote for now) are available to you for browsing and application. There are now more than 200 open data related positions you can apply to.
4: You can access and browse the Job Board right at this moment even without joining The Collective.
5: From the other side of the funnel organizations apply to join as Collective Partners. I curate the applications and act as a gateway.
6: After the application is approved - Collective Partners are in and eligible for further actions.
7: Collective Partners can place their job adds into the Job Board. I curate the job ads and act as a gateway.
8: Collective Partners are eligible to browse the list of Collective Members and invite them for a chat.
Applications are free for both sides.
Who is this for?
It is a Data Focused Talent Collective. So if you are:
➡️ Data Engineer.
➡️ Data Scientist.
➡️ Machine Learning Engineer.
➡️ MLOps Engineer.
➡️ Analytics Engineer.
➡️ Data Analyst.
➡️ Data Architect.
➡️ Data Focused Leader/Manager.
Then the initiative is for you.
If you are a company looking to fill your hiring pipeline of Data Roles and you want to partner with me on this initiative - it is for you.

Feature vs. Concept Drift.
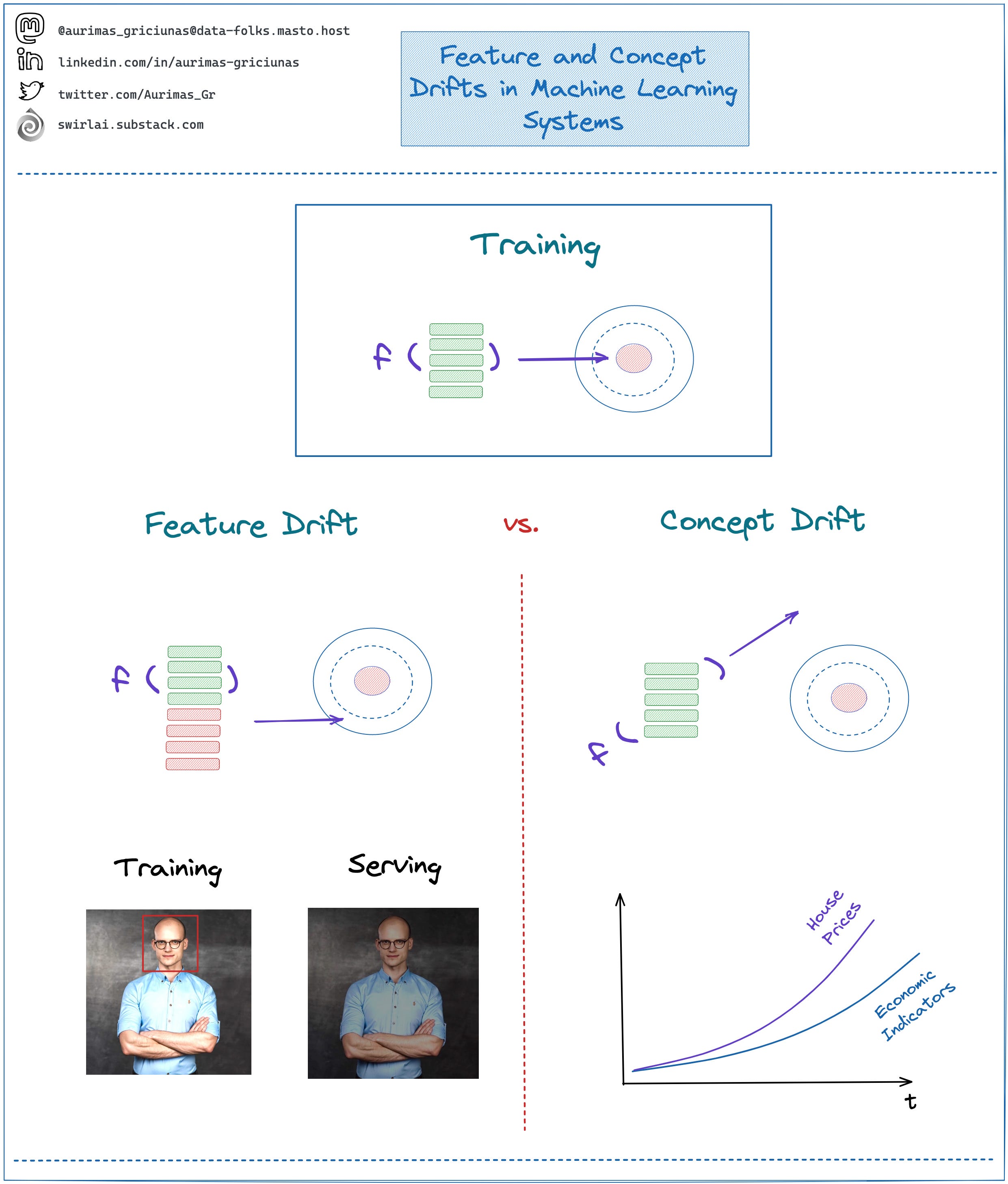
What are Feature and Concept Drifts in Machine Learning Systems?
Your Machine Learning systems can fail in many more ways than regular software.
The most dangerous failure modes are the silent ones. Two unavoidable culprits that will eventually make your model performance metrics degrade are:
➡️ Feature Drift: Also known as Data Drift.
👉 It happens when the population on which the model inference is performed shifts.
👉 You start applying ML Models on data that they have been under-trained on.
Examples:
👉 You increase exposure to one particular marketing channel which you haven’t had enough exposure to before.
👉 You are moving into new markets.
👉 You trained your object detection model on a brightly lit images. However, the location where you are applying it in real time generated photos is dark.
👉 You train your speech recognition models on a high quality audio. However, there is lots of background noise at the location where it is being applied.
➡️ Concept Drift: This phenomenon occurs even when the distribution of the data you feed to the model does not change. It’s the functional relationship between model inputs and outputs that changes.
Examples:
👉 You use geographical regions to predict housing prices, as the economical situation over time in the region changes so will the house prices.
As a MLOps practitioner you have to make sure that your model performance is being continuously monitored and corrective actions taken as soon as model performance metrics degrade below a specific predefined threshold.
Website Activity Tracking System Design.
What is the high level architecture of a Website Activity Tracking System?
If a website is part of your business at some stage tracking User Activity Data becomes a key part of your success. There are multiple paid tools like Google Analytics or Adobe Analytics for this. However, you might want to implement your own process to have more flexibility around what you can do with the data.
Let's look into the components of such systems:
1: JavaScript Trackers - these are JS libraries embedded into the user browser. When the user performs specific actions the library tracks it and sends out an event (in Json form) with additional metadata about the action to a predefined endpoint.
2: A Load Balancer - this is a Load Balancer of your choice exposed via a public endpoint that is indicated in JS Trackers. An extremely important piece of the architecture - it ensures high availability of the endpoint and can be configured to protect against DDoS attacks and perform additional authentication.
3: Collectors - these applications (most likely written in Java) act as gateways between arbitrary events that are coming in and your analytical systems. Data sent by JS Trackers is validated here for top level fields needed for further processing. We can choose to discard invalidated events or store them for additional inspection. Here we also buffer the data for a small amount of time in case downstream data systems become unavailable. In this way we avoid data loss.

4: Distributed Queue (Raw Event Data Stream) - a system like Kafka is placed between collectors and downstream processes. This is done to alleviate any chokepoints and application failures.
✅ Collectors do not need to buffer data as they can send data directly to Kafka.
✅ If processes consuming from Kafka go down we can simply restart them and continue consuming.
✅ Kafka is extremely scalable and can ingest almost limitless amounts of Data if configured correctly.
5: Validators - this is a consumer group reading from Raw Events Data Stream. It could be a Flink application or a plain java or kafka-streams app. Each event is validated against a predefined schema to make sure that downstream Analytics Systems would not be affected by low quality data.
❗️ Each raw event has to have an event type and schema version embedded into it so that the Validator knows what to validate against.
✅ There is very likely to be a deployed Schema Registry - Validators will be sourcing schema information from there.
6: Validated and Invalidated Data Streams - additional Kafka Topics to decouple validation from further processing. These are also used to split Data that is ready for further processing from Invalidated data to be further analyzed and alerted on.
7: Analytics System - here we already know if the Data is ready for further consumption in analytics systems. We can start either real time or batch Transformations and move it further down the Data Value Chain.