


SAI #17: Patterns for implementing Business Logic in Machine Learning Services.
Patterns for implementing Business Logic in Machine Learning Services, Feature Platforms.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week in the Newsletter:
Patterns for implementing Business Logic in Machine Learning Services.
Feature Platforms.
Patterns for implementing Business Logic in Machine Learning Services.
Machine Learning Models usually do not stand on their own. There will be additional business or other processing logic before you feed the data to the Trained Model and after you retrieve the inference results.
You can think of the final Deployable as:
Inference Results = Preprocessing + Business Logic + Machine Learning Model + Post-Processing + Business Logic

Single Service Deployment.
The most straightforward way to package this Deployable is to have all of the additional processing logic coupled with the ML Model and deploy it as a single service.

Here is how it would work for an Request-Response type of deployment:
Backend Service calls the ML Service exposed via gRPC.
ML Service retrieves required Features form a Feature Store. Preprocessing and additional Business Logic is applied on retrieved Features.
The resulting data is fed to ML Model.
Inference Results are ran against additional Post-Processing and Business Logic.
Results are returned to the Backend Service and can be used in the Product Application.
Business Logic decoupled from the Machine Learning Model.
A more complicated way is to have a separate Service that sits in between the Backend Service and the Service exposing ML Model.

Here is the breakdown of the diagram:
Backend Service calls the Service containing Business Logic Rules exposed via gRPC.
Service containing Business Logic Rules calls the ML Service exposed via gRPC.
ML Service retrieves required Features form a Feature Store. Preprocessing is applied on retrieved Features.
The resulting data is fed to ML Model.
Inference Results are ran against additional Post-Processing.
Results are returned to the Service containing Business Logic Rules that are then applied on the inference results.
Final results are returned to the Backend Service and can be used in the Product Application.
When does this added complexity starts to make sense?
Quite often in the Real World situations Machine Learning Model Deployments are ensembles of multiple models chained after each other or producing derived results from a mix of Inference Results.
In this case different teams could and most likely would be working on developing different part of the system. As an example we could take a Recommender System, different teams could be working separately on:
Candidate Retrieval.
Candidate Ranking.
Business Logic.
Decoupling of Business Logic starts to make sense here because each pease of the puzzle can be developed and tested for performance separately. We will dig deeper into all of this in a separate long form Newsletter in the future. So keep tuned in!

Feature Platforms.
What do you need to know about Feature Platforms as a Machine Learning Engineer?
Feature Platform sits between Data Engineering and Machine Learning Pipelines and it solves the following issues:
➡️ Eliminates Training/Serving skew by syncing Batch and Online Serving Storages (5️)
➡️ Enables Feature Sharing and Discoverability through the Metadata Layer - you define the Feature Transformations once, enable discoverability through the Feature Catalog and then serve Feature Sets for training and inference purposes trough unified interface (4️, 3️).
The ideal Feature Platform should have these properties:
1️⃣ It should be mounted on top of the Curated Data Layer
👉 The Data pulled into the Feature Platform should be of High Quality and meet SLAs, Curating Data inside of the FS System is a recipe for disaster.
👉 Curated Data could be coming in Real Time or Batch.
👉 You will usually find Data Engineers curating Real Time Data and Analytics Engineers working with Batch Data.
2️⃣ Feature Platforms should have a Feature Transformation Layer that manages its own compute resources.
👉 This element could be provided by a vendor or you might need to implement it yourself.
👉 The industry is moving towards a state where it becomes standard for vendors to include Feature Transformation part into their offering.
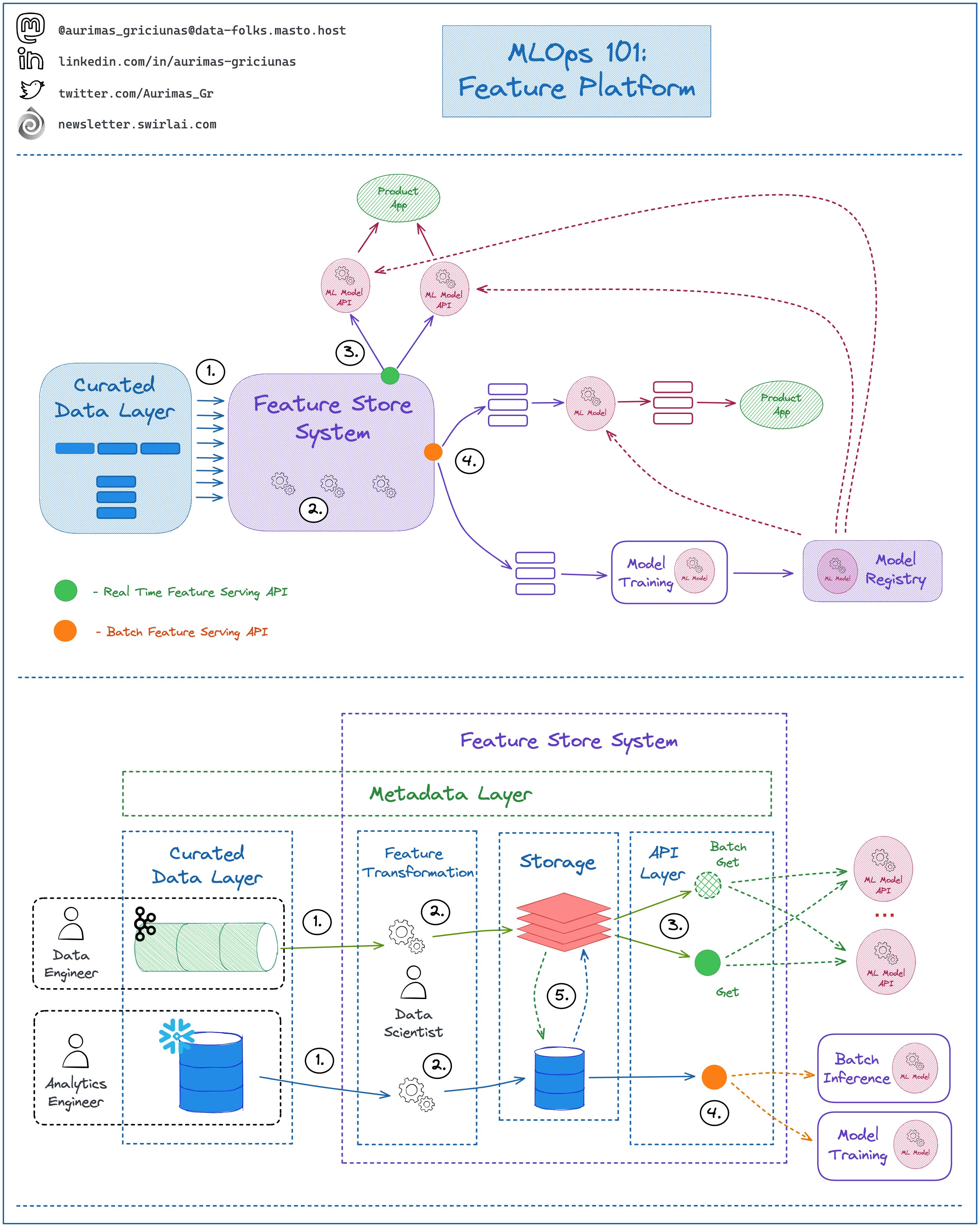
3️⃣ Real Time Feature Serving API - this is where you will be retrieving Features for low latency inference. The System should provide two types of APIs:
👉 Get - you fetch a single Feature Vector.
👉 Batch Get - you fetch multiple Feature Vectors at the same time with Low Latency.
4️⃣ Batch Feature Serving API - this is where you fetch Features for Batch inference and Model Training. The API should provide:
👉 Point in time Feature Retrieval - you need to be able to time travel. A Feature view fetched for a certain timestamp should always return its state at that point in time.
👉 Point in time Joins - you should be able to combine several feature sets in a specific point in time easily.
5️⃣ Feature Sync - regardless of how ingested the Data being Served should always be synced. Implementation can vary, an example could be:
👉 Data is ingested in Real Time -> Feature Transformation Applied -> Data pushed to Low Latency Read capable Storage like Redis -> Data is Change Data Captured to Cold Storage like S3.
👉 Data is ingested in Batch -> Feature Transformation Applied -> Data is pushed to Cold Storage like S3 -> Data is made available for Real Time Serving by syncing it with Low Latency Read capable Storage like Redis.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.
Thank you for the post!
The graphs are very clear as always and you have definitely inspired me to use them more in my work!
I have couple of discussion points regarding the business logic and ML services:
1. I am a proponent of bundling ML code with business logic as it is usually coupled anyways - rules depend on the output OR rules are very light wrapper in which case it does not even matter that much where to put them (maybe). However, I have recently think of a situation where it might be worth separation - when ML deployment is done through some kind of managed service (e.g. MLFlow on Databricks cloud). This way, we can keep the business logic services pointing to the specific versions of the model. I think this brings some nice things to the table - for example it is easier (in my view) to run several versions of the ML model simultaneously. What is your take?
2. Another point is about feature extraction. You have them accessed from the ML service (in a separated case), but my intuition would be to keep that service as close to "pure function" as possible. Mainly - all the input should come with the "request". Do you see any issues with this approach?
3. And the last point concerns you example about the business logic stitching together result from multiple ML models. I am wondering more about team structures (team topologies) that enables this parallel work. Given that this whole peace made up of three parts needs to produce consistent and good results - therefore those components are coupled. How do you handle this then? Have seen good examples?? From my experience, the same team owned all those services and would deploy the whole pipeline usually even just one part changed - basically the whole pipeline was treated as a single unit, but it was distributed because some parts could use a lot smaller machines than others.
Once again, thank you for writing. There is such an array of interesting topics and discussions!