
SAI #18: Implementing ML Inference in Streaming Applications.
Implementing ML Inference in Streaming Applications, Types of Training/Serving Skew.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week in the Newsletter:
Implementing ML Inference in Streaming Applications.
Types of Training/Serving Skew.
Me appearing on a podcast as a guest and geeking out about MLOps.
Implementing ML Inference in Streaming Applications.
What are the two ways you will find Machine Learning Inference Implemented in Streaming Applications in the real world?
We already looked at the different ways ML Models can be deployed. When it comes to Streaming Applications you will usually see two patterns.
Embedded Pattern where ML Model is embedded into the Streaming Application itself.
1: While Data is continuously piped through your Streaming Data Pipelines, an application (e.g. implemented in Flink) with a loaded model continuously applies inference.
2: Additional features are retrieved from a Real Time Feature Store Serving API.
3: Inference results are passed to Inference Results Stream.
4: Backend product services can subscribe to the Inference Stream directly.
5: Optionally, Inference Results are piped to a low latency storage like Redis and are retrieved by the Backend Service from there.
✅ Extremely fast - data does not leave the Streaming application when Inference is applied.
✅ Easy to manage security - data only traverses a single application.
❗️ Hard to Test multiple versions of ML Models. The Streaming app is a consumer group so to have multiple versions of ML Model you will have multiple consumer groups reading the entire stream or have multiple ML models loaded into memory and implement intelligent routing inside of the application.
❗️ Complicated collaboration patterns when it comes to multiple people working on the same project.
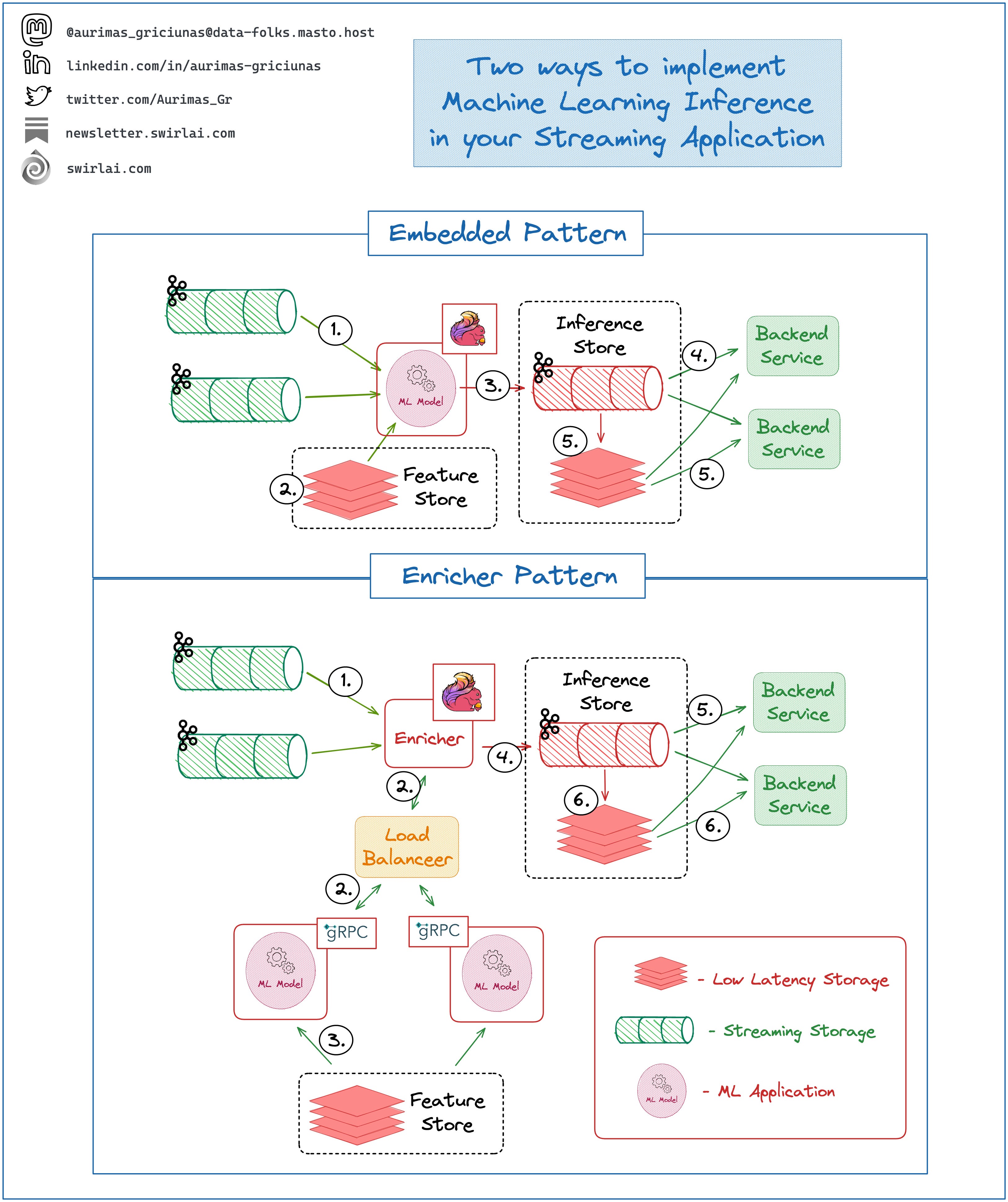
Enricher Pattern where Streaming Application uses a decoupled ML Service to enrich the Streamed data.
1: Data from Streaming Storage is consumed by an Enricher Application (e.g. implemented in Flink).
2: Enricher Application calls the ML Service exposed via gRPC or REST and enriches the Streaming Payload with Inference Results.
3: Additional features are retrieved by the ML Service from a Real Time Feature Store Serving API.
4: Enricher passes the payload enriched with Inference Results to the Inference Results Stream.
5-6: The same as 4-5 in the Embedded Pattern.
✅ Flexible when it comes to deployment of multiple versions of ML Model. (e.g. implement routing per partition in keyed Kafka Topic - events with a certain key will always go to a specific version of ML Service).
✅ Easy to release new versions of the model - Streaming Application does not need to be restarted.
❗️ Network jumps will increase latency.
❗️ Microservices are complicated to trace.
Types of Training/Serving Skew.
What are the two types of Training/Serving Skew and why do they happen?
The phenomenon of Training/Serving Skew is something you are very likely to run into at some point in time and it causes an instant ML Model Performance degradation when the Model is deployed when compared to offline Training environments.
Let's look into the two ways this might happen:
Infrastructure and Technology related.
Let’s take a closer look into a System that will most likely suffer from Training/Serving Skew.
1️⃣ Data is collected in real time either from a CDC stream or Directly emitting events from an application.
2️⃣ Data is moved to a Data Warehouse.
3️⃣ Data is modeled in the Data Warehouse.
4️⃣ We perform Feature Transformations and use Transformed Features for Training ML models. We will most likely use Python at this point.
5️⃣ Load Static Features into a low latency storage like Redis to be used in Real Time Model Inference.
The Model we trained was also using some of Dynamic Real Time Features which we are not able to serve from the Batch System, consequently:
6️⃣ We implement Preprocessing and Feature Transformation logic for Dynamic Features inside of Product applications. This logic will most likely be implemented in a different programming language that was used in Batch Feature Transformations. E.g. PHP.
Why does this cause issues?
➡️ Feature Transformation is performed using different technologies, even well intentioned implementations can result in different outputs for the same Feature Calculation.
➡️ Production Applications are built by Developers who might be working in a separate silo from Data Scientists.

Data Related.
This type of skew happens when the population on which we train the Model is not representative to the population to which the Model is Served.
Here are few straightforward examples:
➡️ House Pricing Model trained on US Data is used in Australia.
➡️ Object Detection Model trained on well lit pictures is used in a poorly lit warehouse.
➡️ …
❗️ Differences in Feature Distributions in Batch Training vs. Real Time Inference will cause unexpected Model Predictions that could be disastrous for your business.
✅ We can Detect Skews by choosing a safe Model Release Strategy like Shadow or Canary Release.
✅ We Should monitor Skews in production systems - they should be visible right after the deployment when compared to Feature Drift that happens over time.
Check out me appearing as a guest on one of neptune.ai podcasts.
I talk with the Founder and CEO of Neptune Piotr Niedzwiedz about all that MLOps is. We touch topics like Feature Stores, Data Versioning, ML Pipelines and more.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.