


SAI #19: The Data Value Chain.
The Data Value Chain, Data Contracts in the Data Pipeline, The 4 types of ML Model Deployment.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week in the Newsletter:
The Data Value Chain.
Data Contracts in the Data Pipeline.
The 4 types of ML Model Deployment.
The Data Value Chain.
How does the Data Value Chain look like and what do we need to know about efforts to bring the Data up the chain?
We can benefit greatly towards understanding ROI from a well designed Data Flow and involvement of relevant non business Stakeholders at a correct point in time.
Let’s say we are interested in building out a new Data Product powered by a Machine Learning Model.
Here are some Data Flow elements that are important - note that we go from the downstream to the upstream and not vice versa:
1️⃣ Engineered Features: Do we already have Features available in the Feature Store that could be directly used for the ML Driven Product Idea that is being conceived?
👉 Investment: minimal, if we do have the data - we will be able to start a PoC really quickly.
👉 Involve: Data Scientists and Machine Learning Engineers.
2️⃣ Curated Data: Can we derive required Features from the Data that is already Curated?
👉 Investment: minimal to medium, Data here is already Golden - quality is assured and SLAs are met.
👉 Involve: Analytical Engineers and Data Engineers.
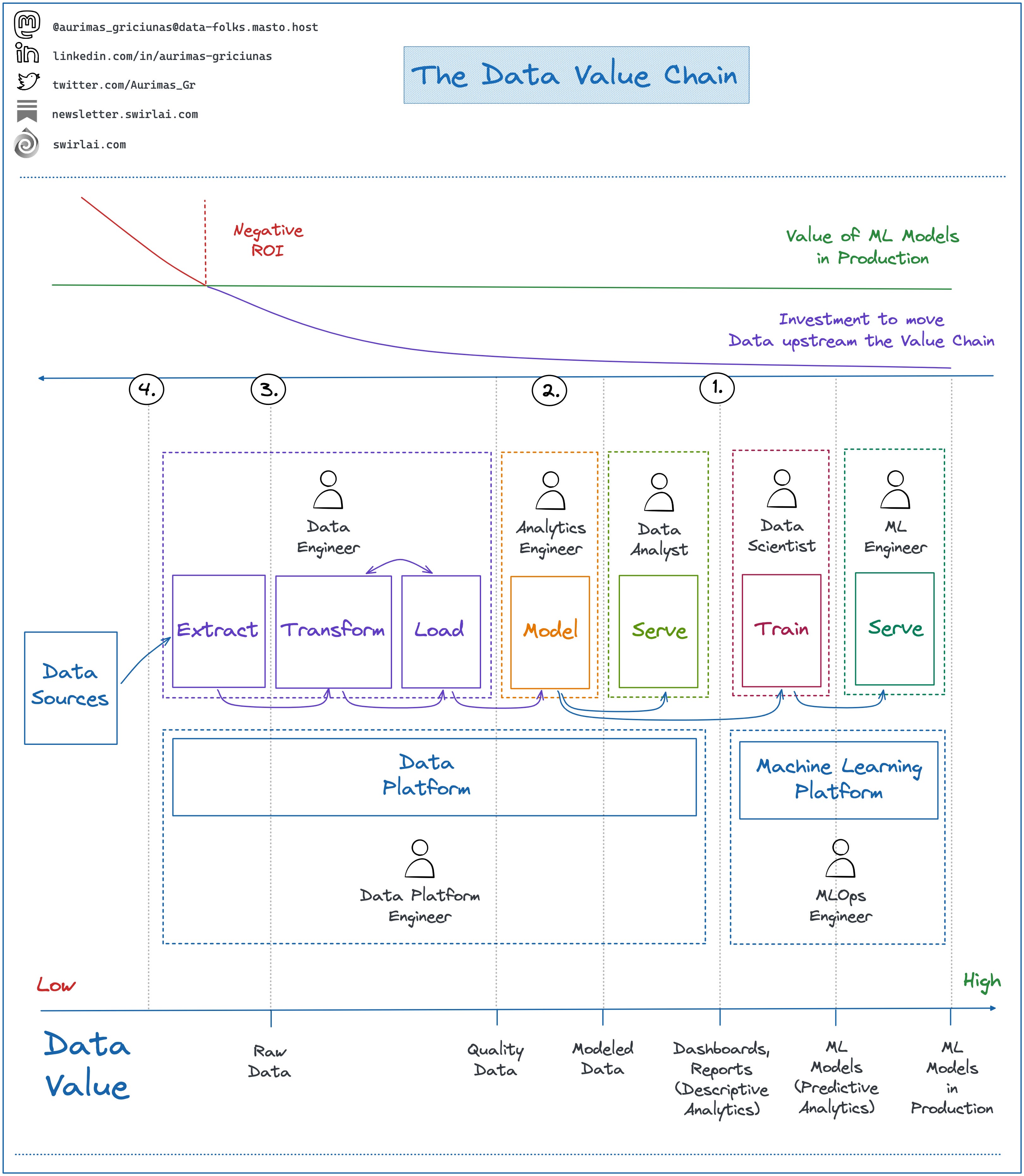
3️⃣ Raw Data: Could we derive any Features from Raw Data? If yes - is it possible for it to become Curated? Can we ensure the Quality? Is the Data current and are we receiving it in regular intervals? Is it possible to establish meaningful SLAs?
👉 Investment: medium to high.
👉 Involve: Data Engineers.
❗️This is where we will start seeing negative ROI.
4️⃣ Data Acquisition: The last frontier. If we don't have the needed Data anywhere we might try to acquire it from external systems.
👉 Investment: High.
👉 Involve: Software Engineers, Data Engineers.
❗️This is where most of the ideas will result in negative ROI.
[Important]: after going one step upstream always remember to add up any downstream investments when calculating ROI.
Data Contracts in the Data Pipeline.
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
Data Contract should hold the following non-exhaustive list of metadata:
👉 Schema of the Data being Produced.
👉 Shema Version - Data Sources evolve, Producers have to ensure that it is possible to detect and react to schema changes. Consumers should be able to process Data with the old Schema.
👉 SLA metadata - Quality: is it meant for Production use? How late can the data arrive? How many missing values could be expected for certain fields in a given time period?
👉 Semantics - what entity does a given Data Point represent. Semantics, similar to schema, can evolve over time.
👉 Lineage - Data Owners, Intended Consumers.
👉 …
Some Purposes of Data Contracts:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to where it was generated.
➡️ Improve scalability of your Data Systems.
➡️ Reduce intermediate Data Handover Layer.
➡️ …
Example implementation for Data Contract Enforcement:

1️⃣ Schema changes are implemented in a git repository, once approved - they are pushed to the Applications generating the Data and a central Schema Registry.
2️⃣ Applications push generated Data to Kafka Topics. Separate Raw Data Topics for CDC streams and Direct emission.
3️⃣ A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Schema Registry.
4️⃣ Data that does not meet the contract is pushed to Dead Letter Topic.
5️⃣ Data that meets the contract is pushed to Validated Data Topic.
6️⃣ Applications that need Real Time Data consume it directly from Validated Data Topic or its derivatives.
7️⃣ Data from the Validated Data Topic is pushed to object storage for additional Validation.
8️⃣ On a schedule Data in the Object Storage is validated against additional SLAs and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
9️⃣ Consumers and Producers are alerted to any SLA breaches.
🔟 Data that was Invalidated in Real Time is consumed by Flink Applications that alert on invalid schemas. There could be a recovery Flink App with logic on how to fix invalidated Data.
The 4 types of ML Model Deployment.
Even if you will not work with them day to day, the following are the four ways to deploy a ML Model you should know and understand as a MLOps/ML Engineer.
Batch:

👉 You apply your trained models as a part of ETL/ELT Process on a given schedule.
👉 You load the required Features from a batch storage, apply inference and save the results to a batch storage.
👉 It is sometimes falsely thought that you can’t use this method for Real Time Predictions.
👉 Inference results can be loaded into a real time storage and used for real time applications.
Embedded in a Stream Application:

👉 You apply your trained models as a part of Stream Processing Pipeline.
👉 While Data is continuously piped through your Streaming Data Pipelines, an application with a loaded model continuously applies inference on the data and returns it to the system - most likely another Streaming Storage.
👉 This deployment type is likely to involve a real time Feature Store Serving API to retrieve additional Static Features for inference purposes.
👉 Predictions can be consumed by multiple applications subscribing to the Inference Stream.
Request - Response:
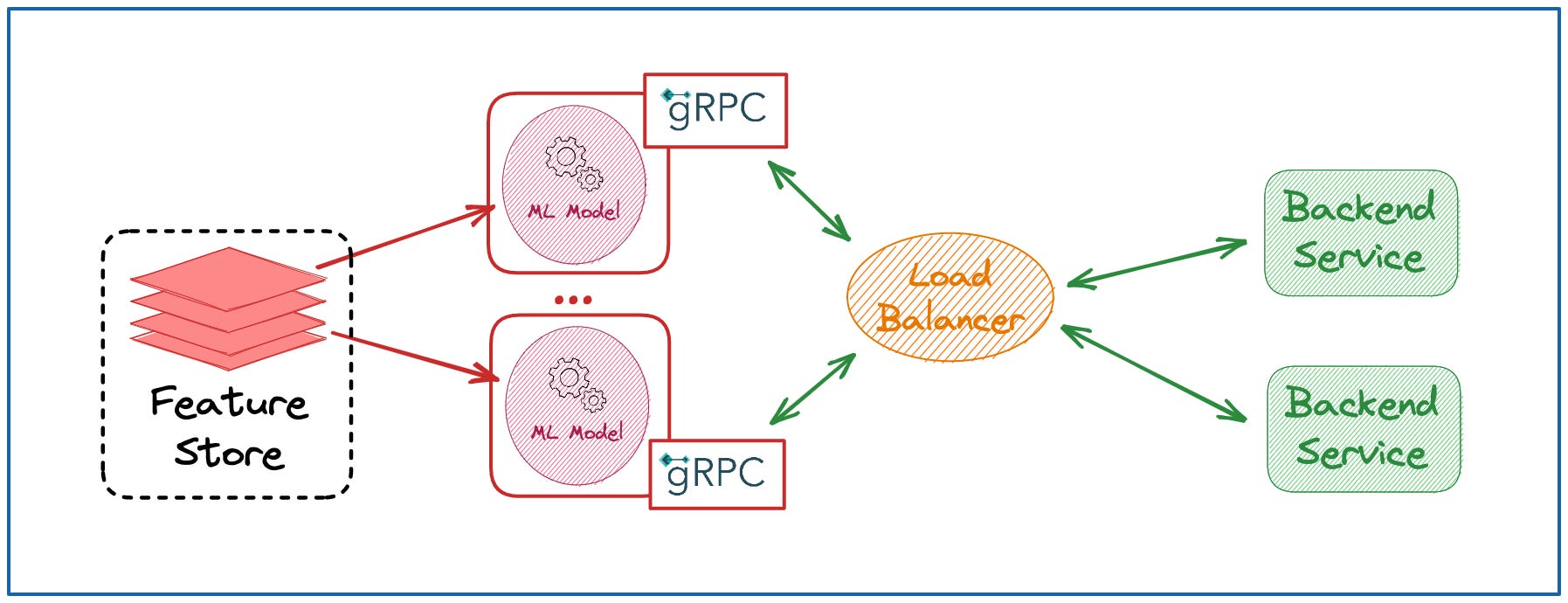
👉 You expose your model as a Backend Service (REST or gRPC).
👉 This ML Service retrieves Features needed for inference from a Real Time Feature Store Serving API.
👉 Inference can be requested by any application in real time as long as it is able to form a correct request that conforms API Contract.
Edge:
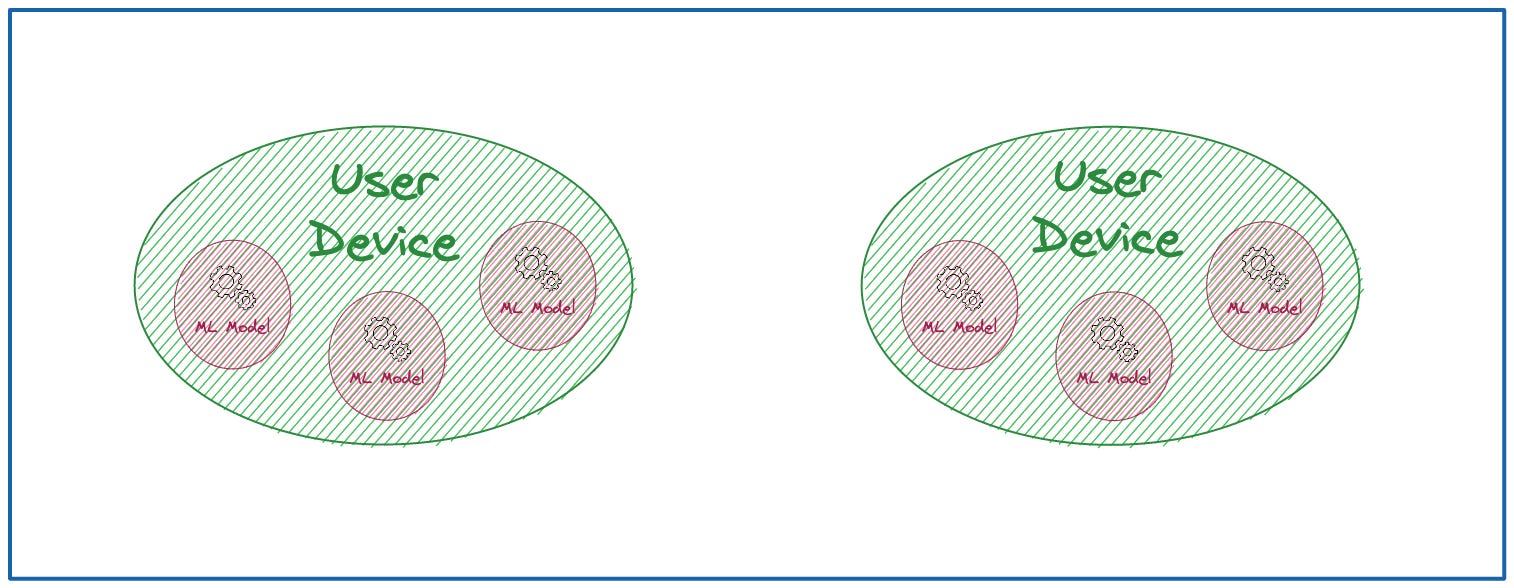
👉 You embed your trained model directly into the application that runs on a user device.
👉 This method provides the lowest latency and improves privacy.
👉 Data in most cases is generated and lives inside of device significantly improving the security.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.
in your first diagram of value chain , is it the other way around? ML Engineer in "Train" layer and Data Scientist in "Serve" Layer