
SAI #21: What is Continuous Training (CT) in Machine Learning Systems?
Continuous Training (CT) and Data Quality in Machine Learning Systems.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week in the Newsletter:
Continuous Training (CT) in Machine Learning Systems.
Data Quality in Machine Learning Systems.
5 books to get you up to speed on the end-to-end Data Lifecycle.
Continuous Training (CT) in Machine Learning Systems.
Continuous Training is the process of automated ML Model retraining in Production Environments on a specific trigger. Let’s look into some prerequisites for this:
1️⃣ Automation of ML Pipelines.
👉 Pipelines are orchestrated.
👉 Each pipeline step is developed independently and is able to run on different technology stacks.
👉 Pipelines are treated as a code artifact.
✅ You deploy Pipelines instead of Model Artifacts allowing Continuous Training In production.
✅ Reuse of components allows for rapid experimentation.
2️⃣ Introduction of strict Data and Model Validation steps in the ML Pipeline.
👉 Data is validated before training the Model. If inconsistencies are found - Pipeline is aborted.
👉 Model is validated after training. Only after it passes the validation is it handed over for deployment.
✅ Short circuits of the Pipeline allow for safe CT in production.
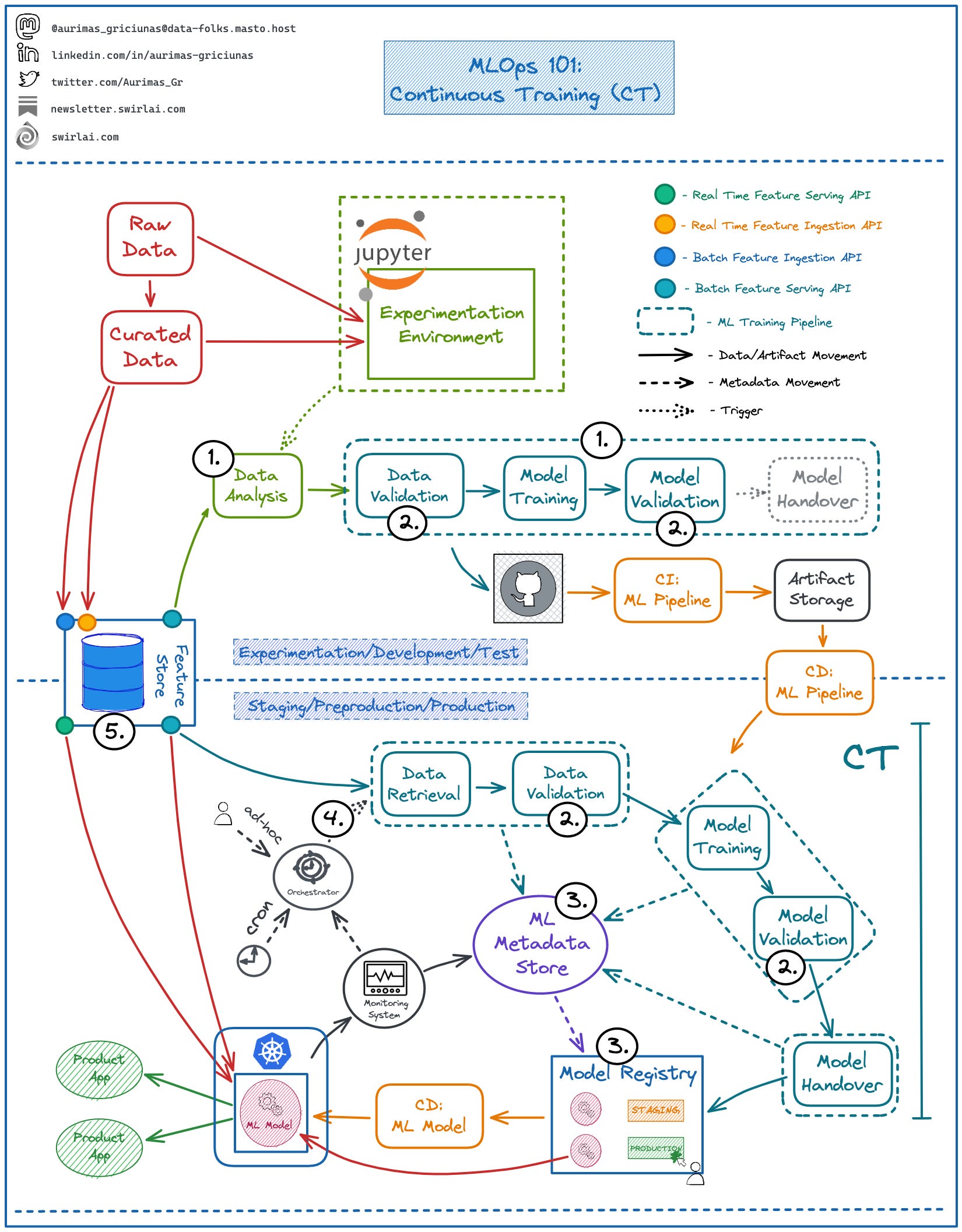
3️⃣ Introduction of ML Metadata Store.
👉 Any Metadata related to ML artifact creation is tracked here.
👉 We also track performance of the ML Model.
✅ Experiments become reproducible and comparable between each other.
✅ Model Registry could and in some cases should be treated as part of ML Metadata Store.
4️⃣ Different Pipeline triggers in production.
👉 Ad-hoc.
👉 Cron.
👉 Reactive to Metrics produced in Model Monitoring System.
👉 Arrival of New Data.
✅ This is where the Continuous Training is actually triggered.
5️⃣ Introduction of Feature Store (Optional).
👉 Avoid work duplication when defining features.
👉 Reduce risk of Training/Serving Skew.
My thoughts on Continuous Training:
➡️ Introduction of CT is not straightforward and you should approach it iteratively. The following could be good Quarterly Goals to set:
👉 Experiment Tracking is extremely important at any level of ML Maturity and the least invasive in the process of ML Model training - I would start with ML Metadata Store introduction.
👉 Orchestration of ML Pipelines is always a good idea, there are many tools supporting this (Airflow, Kubeflow, VertexAI etc.). If you are not doing it yet - grab this next, also make the validation steps part of this goal.
👉 The need for Feature Store will wary on the types of Models you are deploying. I would only suggest prioritizing it if you have Models that perform Online predictions as it will help with avoiding Training/Serving Skew.
👉 Don’t rush with Automated retraining. Ad-hoc and on-schedule will bring you a long way.
Data Quality in Machine Learning Systems.
It is extremely important to note that we need to ensure Data Quality upstream of ML Pipelines, trying to do it in the pipeline itself will cause unavoidable failure when working at scale. One of the recent concepts that can be leveraged here is Data Contracts.
Data Contract is an agreement between Data Producers and Data Consumers about the qualities to be met by Data being produced.
Data Contract should hold the following non-exhaustive list of metadata:
👉 Schema Definition.
👉 Schema Version.
👉 SLA metadata.
👉 Semantics.
👉 Lineage.
👉 …
Some Purposes of Data Contracts:
➡️ Ensure Quality of Data in the Downstream Systems.
➡️ Prevent Data Processing Pipelines from unexpected outages.
➡️ Enforce Ownership of produced data closer to the source.
➡️ Improve scalability of your Data Systems.
➡️ …
Example Architecture Enforcing Data Contracts:
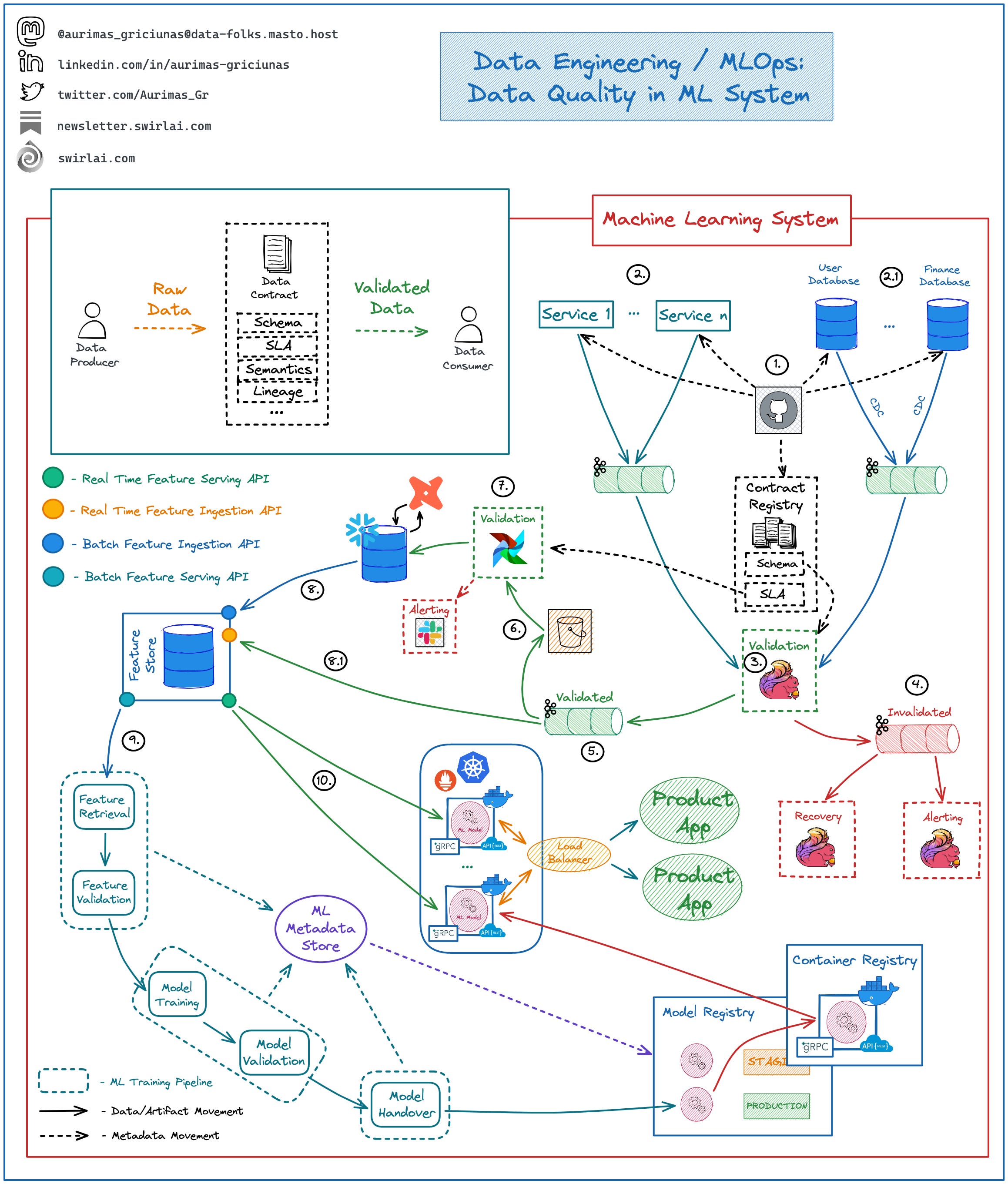
1: Schema changes are implemented in version control, once approved - they are pushed to the Applications generating the Data, Databases holding the Data and a central Data Contract Registry.
Applications push generated Data to Kafka Topics:
2: Events emitted directly by the Application Services.
👉 This also includes IoT Fleets and Website Activity Tracking.
2.1: Raw Data Topics for CDC streams.
3: A Flink Application(s) consumes Data from Raw Data streams and validates it against schemas in the Contract Registry.
4: Data that does not meet the contract is pushed to Dead Letter Topic.
5: Data that meets the contract is pushed to Validated Data Topic.
6: Data from the Validated Data Topic is pushed to object storage for additional Validation.
7: On a schedule Data in the Object Storage is validated against additional SLAs in Data Contracts and is pushed to the Data Warehouse to be Transformed and Modeled for Analytical purposes.
8: Modeled and Curated data is pushed to the Feature Store System for further Feature Engineering.
8.1: Real Time Features are ingested into the Feature Store directly from Validated Data Topic (5).
👉 Ensuring Data Quality here is complicated since checks against SLAs is hard to perform.
9: High Quality Data is used in Machine Learning Training Pipelines.
10: The same Data is used for Feature Serving in Inference.
Important note: ML Systems are plagued by other Data related issues like Data and Concept Drifts. These are silent failures and while they can be monitored, we don’t include it in the Data Contract.
5 books to get you up to speed on the end-to-end Data Lifecycle.
I am a strong believer that you should strive to understand the entire end-to-end Data System if you want to achieve the best results in your career progression.
This means having high level knowledge of both Data Engineering and Machine Learning Systems supplemented by a dose of Systems Thinking. So here is the list of books that will help you grow in these areas.

1️⃣ “Fundamentals of Data Engineering” - A book that I wish I had 6 years ago. After reading it you will understand the entire Data Engineering workflow and it will prepare you for further deep dives.
2️⃣ “Designing Machine Learning Systems“ - A gem of 2022 in Machine Learning System Design. It will introduce you to the entire Machine Learning Lifecycle and give you tools to reason about more complicated ML Systems.
3️⃣ “Machine Learning Design Patterns“ - The book introduces you to 30 Design Patterns for Machine Learning. You will find 30 recurring real life problems in ML Systems, how a given pattern tries to solve them and what are the alternatives. Always have this book by your side and refer to it once you run into described problems - the book is gold.
4️⃣ “Designing Data-Intensive Applications“ - Delve deeper into Data Engineering Fundamentals. After reading the book you will understand Storage Formats, Distributed Technologies, Distributed Consensus algorithms and more.
5️⃣ “System Design Interview: An Insider’s Guide“ (volume 1 and 2) - While these books are not focusing on Data Systems specifically they are non-questionable “must reads” to grow your systems thinking. It covers multiple IT systems that you would find in the real world and explains how to reason about scaling them as the user count increases.
[NOTE]: All of the books above are talking about Fundamental concepts, even if you read all of them and decide that Data Field is not for you - you will be able to reuse the knowledge in any other Tech Role.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.