
SAI #22: Decomposing the Data System.
This week we look into how to decompose the Data System for better reasoning.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
This week we will look into first step of the process of Decomposing Large Scale Data Systems into smaller Fundamental pieces.
As you progress in your Data Career you are very likely to become responsible for larger pieces of infrastructure. You will be leagues ahead of your competition if you start learning to decompose and understand these systems as early as possible.
Why would you learn to decompose?
✅ Different Tech Stack in different Layers.
✅ Different Roles responsible for different Layers.
✅ Each Layer can be scaled separately.
✅ Each Layer will suffer from different possible bottlenecks.
✅ By decomposing it you will be able to understand the total latency of event processing and tune separate pieces to meet SLAs.
✅ Learning to do it will boost your Systems Thinking significantly.
✅ …
The very first split that you should be doing before zooming in even more is depicted in the following diagram:
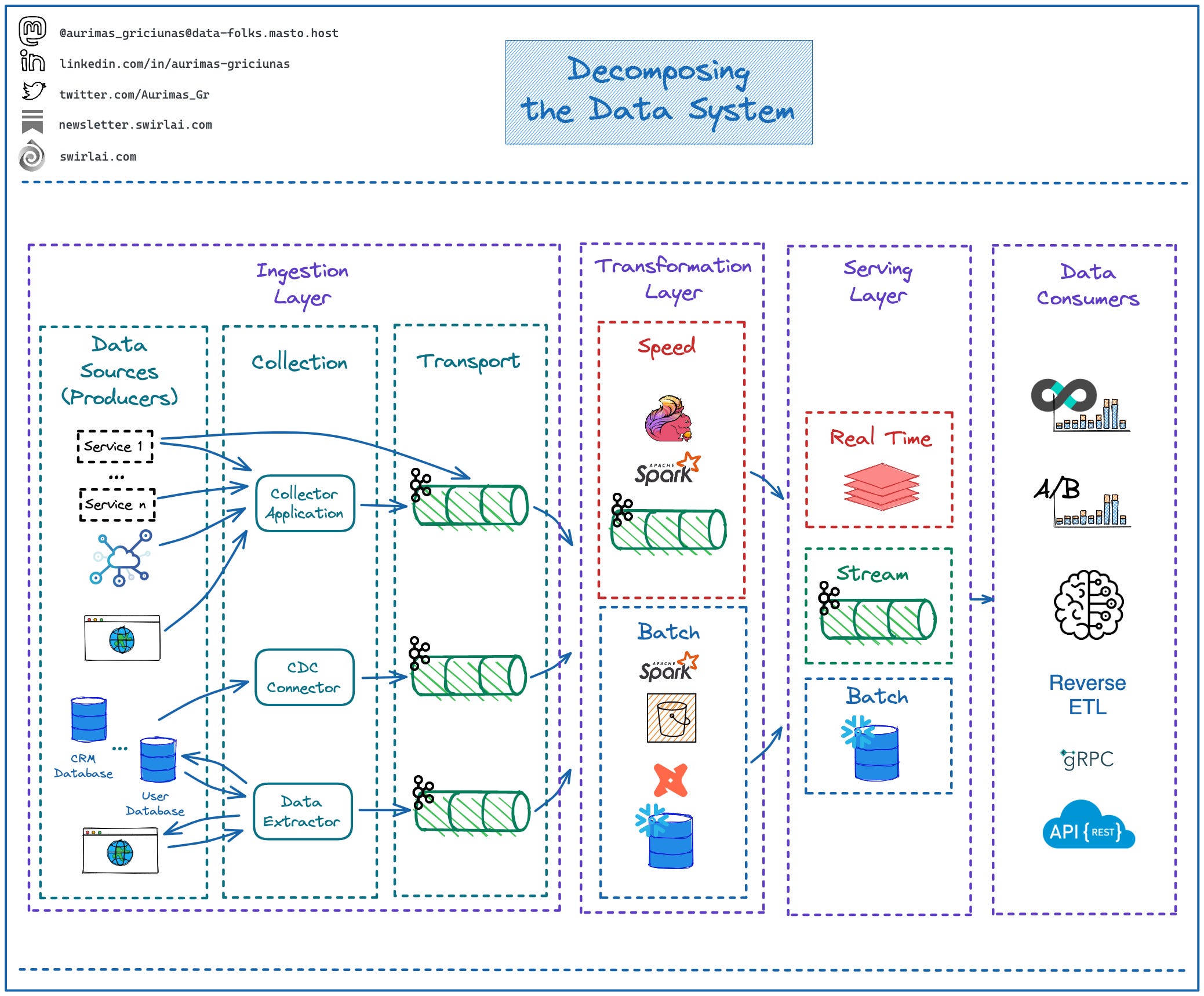
Let’s zoom in into individual pieces.
Data Ingestion Layer.
This is where we extract and validate Data for further transformations down the stream. For easier reasoning we split it down further.
Data Sources:

As a Data Architect you need to understand how the data is produced and what possible options to connect it with the Data System are. Also, Data Contracts will be ideally implemented here. Some of the Data Sources that you will run into in almost every company:
1: Internal Services - these can be simple backend services emitting events that are pushed downstream for Data Analytics purposes or Machine Learning Models exposed as REST or gRPC APIs that emit features and predictions for monitoring or usage in further Model Training purposes.
2: IoT (Internet of Things) device fleets.
3: Websites - website activity events can be pushed by the website code itself (A) or we might be scraping the data from the internal Network (B).
4: Data could be gathered from Third Party SaaS offerings like Salesforce. Salesforce for example allows you to bot poll for changes via REST API and connect to their push api that emits events in real time.
5: The most common source of data are the Internal Backend Databases. These could hold Marketing, User, Financial data etc.
…
Collection:
Rarely the data produced by Data Sources will be pushed directly downstream. This subsystem acts as a proxy between External Sources and the Data System. You are very likely to see one of three proxy types here:
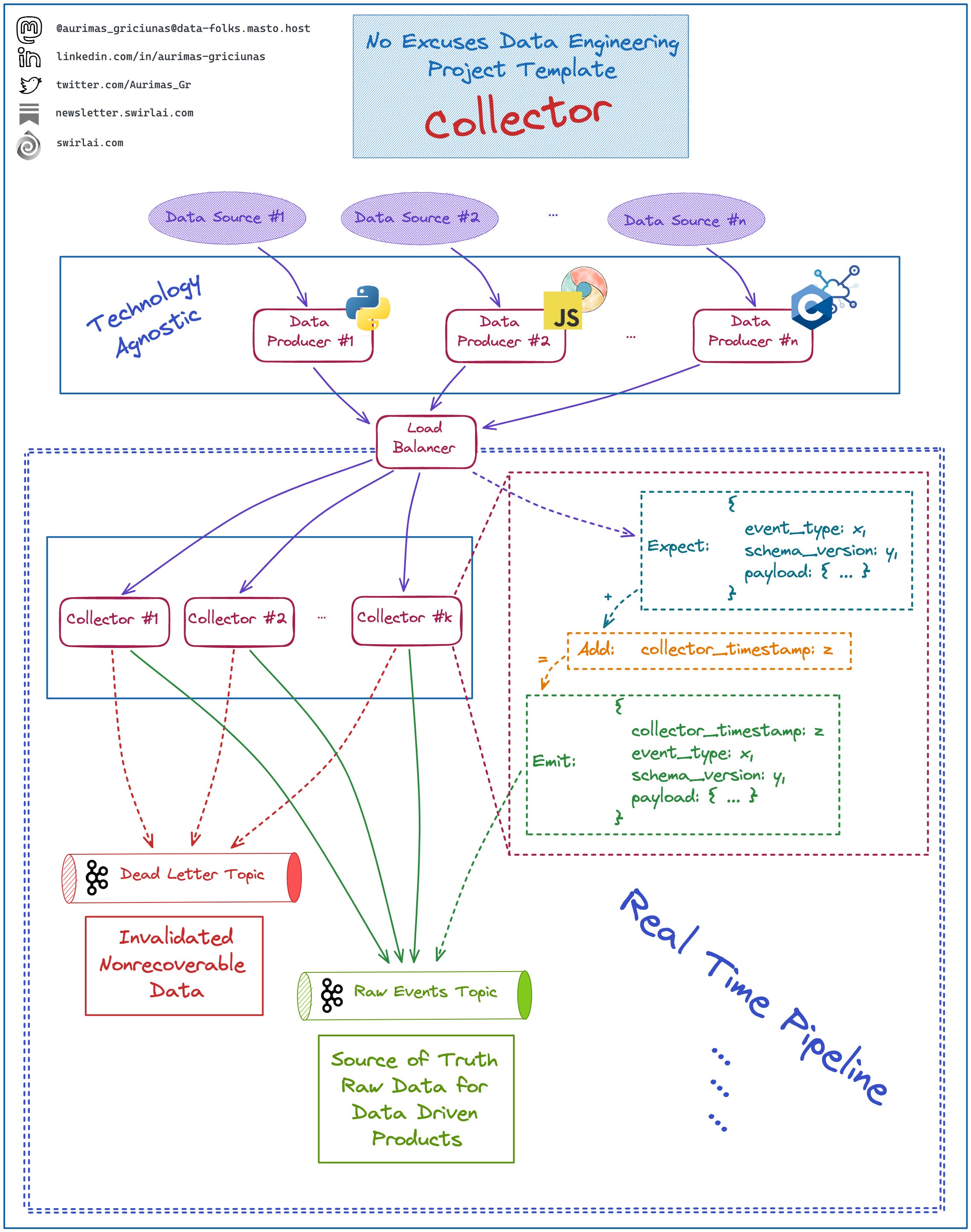
➡️ Collectors - applications that expose a public or private endpoint to which Data Producers can send the Events. I have covered viable implementation of the collector in one of my previous issues, here is the diagram:
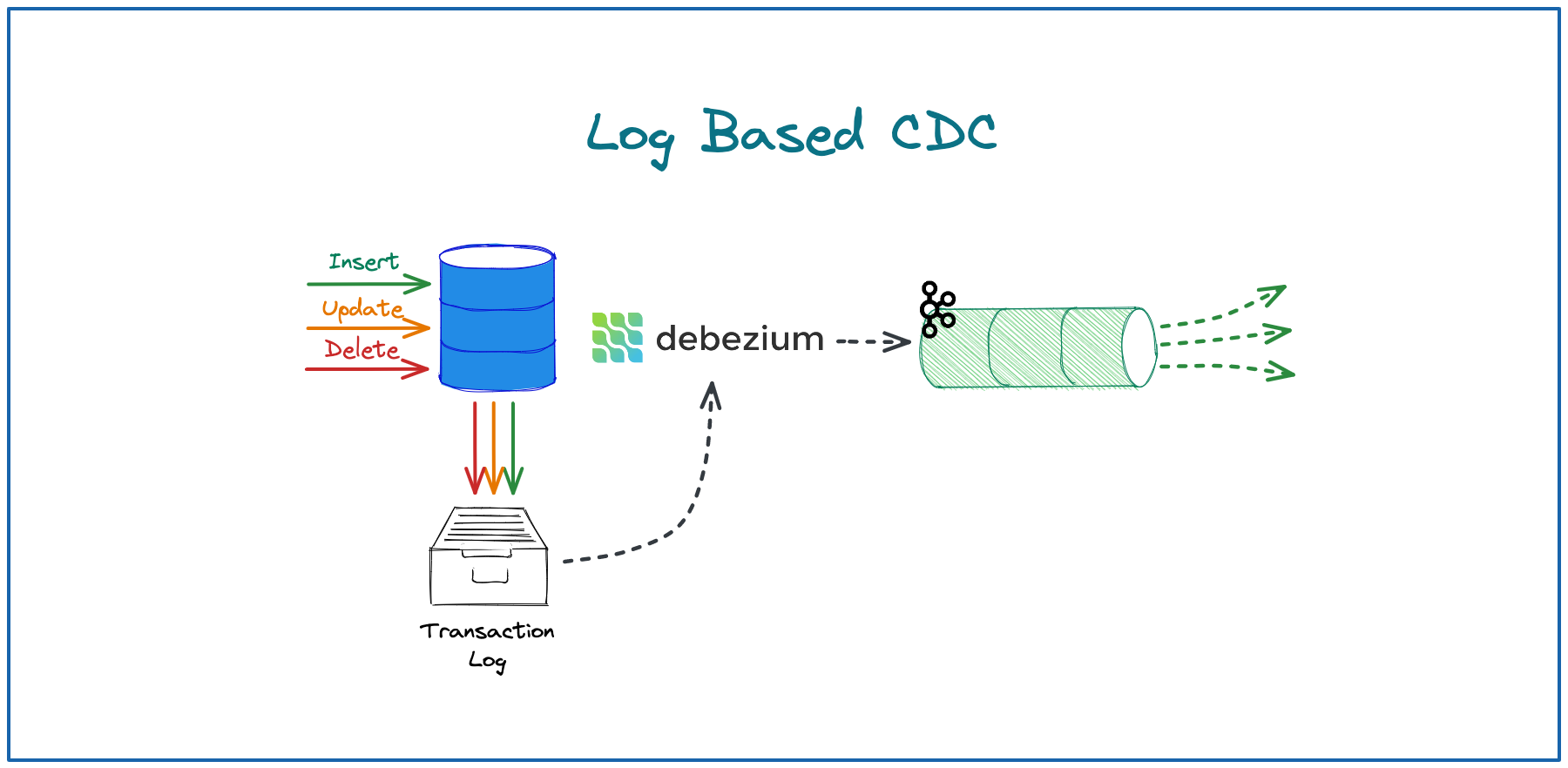
➡️ CDC Connectors - applications that connect to Backend DB event logs and push selected updates happening against the DB to the Data System. You are most likely see tools like Debezium here. I have also covered them before, here is a diagram:
➡️ Extractors - applications written by engineers that poll for changes in external systems like websites and push the Data down the stream.

Transport:
In most cases you will see a Distributed Messaging system before the Data moves down the stream. Also, data validation can happen at this stage to alleviate stress from computations happening down the Data value Chain.

Transformation Layer (we will delve deeper into this layer in further episodes):
Batch:
You will find either a Data Warehouse or a Lake House here.
Speed:
Some transformations are required in Near to Real Time and will be done by connecting Directly to the Distributed Messaging Stream by e.g. a Flink Cluster.
Serving Layer (we will delve deeper into this layer in further episodes):
This Layer is used to expose data for the end user, there are generally three levels of latency.
Batch:
This layer is usually implemented by exposing Data via Data Marts in the Data Warehouse or Golden Datasets in the Lakehouse.
Stream:
Some Data might be served via Distributed Queue where multiple consumers can subscribe to the streams.
Real Time:
Some Data is exposed via Low Latency Data Store like Redis, Cassandra or ScyllaDB.
Hope you learned something new today and see you in the next episode!
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.
Hi Aurimas,
Thanks for the reading, it's really complex each one of the steps and it's useful understand the start point where the data is born.
Thanks!
Great Article