
SAI #23: Deconstructing a Feature Store.
This week we look into ins and outs of a Feature Store.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
“When should I consider adding a Feature Store element to my MLOps stack?” is the question that I get asked regularly. Today, we look into the parts that make up a functioning Feature Store and try to answer the prior question.
Before trying to understand what problems are solved by Feature Stores let us review how it plugs into the overall MLOps architecture.

1️⃣ (Graph 1) Feature Stores are mounted on top of the Curated Data Layer.
The Data pulled into the Feature Platform should be of High Quality and meet SLAs.
Curated Data could be coming in Real Time or Batch.
What it usually means in practice is this:
For Batch case the data you will be pulling to the Feature Store lives in one of (or multiple) Data Marts in your Data Warehouse or Golden Datasets in your Lakehouse.
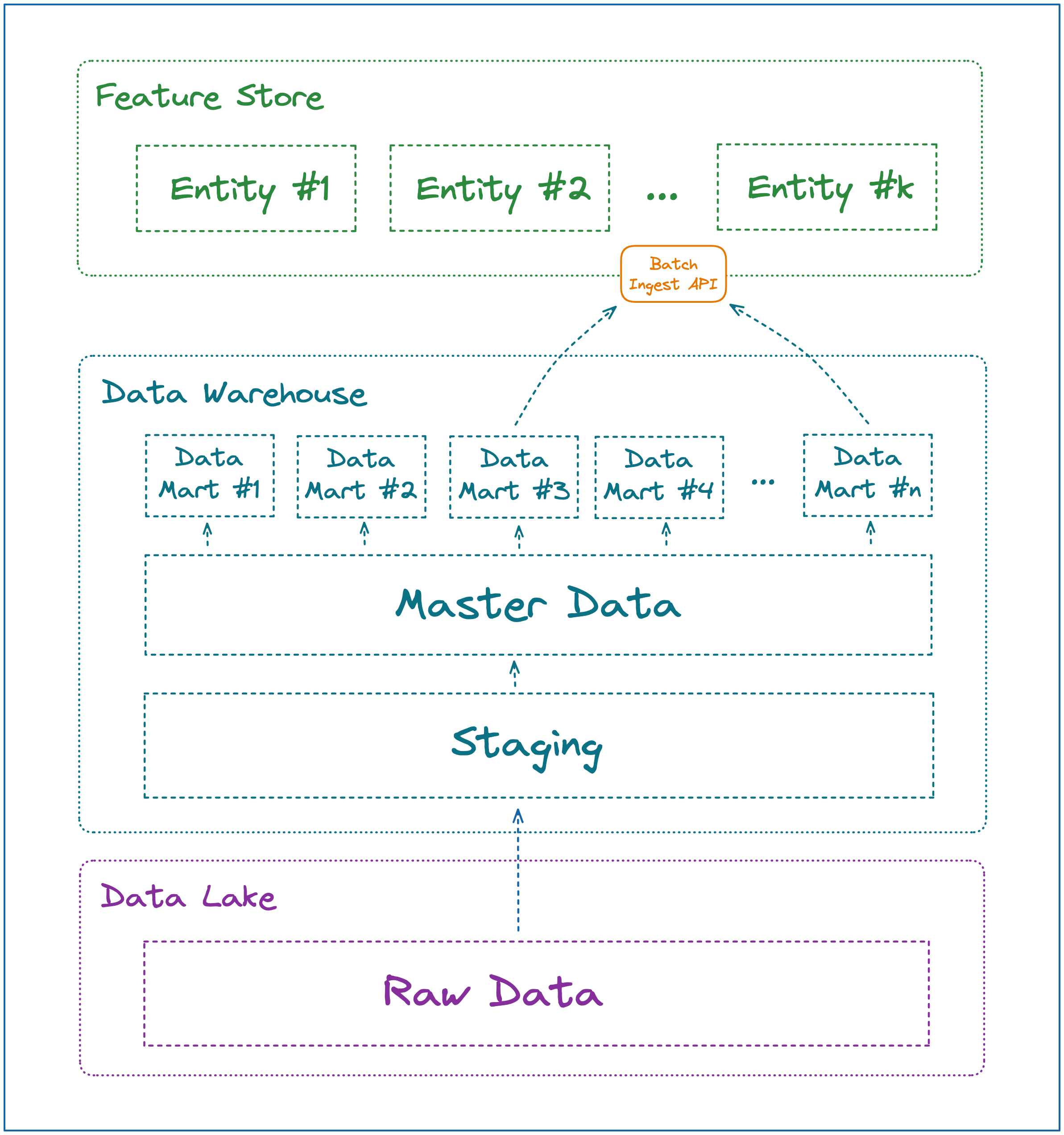
For Real Time case - you will be pushing Data to the Feature Store from a Distributed Queue. Before the data is pushed to the FS it will be first curated via a single or multiple Stream Processing Applications.

You will usually find Data Engineers curating Real Time Data and Analytics Engineers working with Batch Data. This happens due to complexities involved in building Stream Processing applications. The tendency of tooling being continuously simplified is most likely to change this in the future.
2️⃣ (Graph 1) Feature Stores might or might not have a Feature Transformation Layer that manages its own compute resources.
This element could be provided by a vendor or you might need to implement it yourself. If the Later is the case - it will have to be implemented via processes depicted in Graphs 1 and 2.
The industry is moving towards a state where it becomes standard for vendors to include Feature Transformation part into their offering. This means that you can forego Data Aggregation steps in Stream Processing case and do it directly in the Feature Platform on the ingested Curated Data.
3️⃣ (Graph 1) Real Time Feature Serving API - this is where you will be retrieving Features for low latency inference. An effective Feature Store should provide two types of APIs:
Get - you fetch a single Feature Vector.
Batch Get - you fetch multiple Feature Vectors at the same time with Low Latency.
Batch Get is extremely useful when you want to retrieve multiple entity vectors in a single API call in asynchronous way.
There are still Feature Store Products that do not support Batch Get for Real Time Feature Serving API - in this case you will have to implement it yourself.
4️⃣ (Graph 1) Batch Feature Serving API - this is where you fetch Features for Batch inference and Model Training. The API should provide:
Point in time Feature Retrieval - you need to be able to time travel. A Feature view fetched for a certain timestamp should always return its state at that point in time.
Point in time Joins - you should be able to combine several feature sets in a specific point in time easily.
So what problems does Feature Store solve?
You will usually find the following problems to be solved by Feature Stores when browsing the web:
Cataloguing of Features.
Feature Sharing.
Data Leakage.
Training/Serving Skew.
A need to do feature processing multiple times.
The truth is that the main problem solved here is the Training Serving Skew and a need to do feature processing multiple times, all others are just cherry on the top.
Simply put - Feature Store ensures that preprocessing happens before the data is pushed to the Store hence removing the need to do that before you feed the Features to the ML Model for training or inference purposes.
The Training/Serving Skew is addressed by:
5️⃣ (Graph 5) Feature Sync - regardless of how ingested the Data being Served should always be synced. Implementation can vary, an example could be:
👉 Data is ingested in Real Time -> Feature Transformation Applied -> Data pushed to Low Latency Read capable Storage like Redis -> Data is Change Data Captured to Cold Storage like S3.
👉 Data is ingested in Batch -> Feature Transformation Applied -> Data is pushed to Cold Storage like S3 -> Data is made available for Real Time Serving by syncing it with Low Latency Read capable Storage like Redis.

When do I need a Feature Store?
Before answering the question let us take a closer look into a composition of a Real Time Inference service. The simplest form is depicted in Graph 6:

Backend Service (Client) calls the ML Service exposed via gRPC.
ML Service retrieves required Features form a Feature Store. Preprocessing and additional Business Logic is applied on retrieved Features.
The resulting data is fed to ML Model.
Inference Results are ran against additional Post-Processing and Business Logic.
Results are returned to the Backend Service and can be used in the Product Application.
From (Graph 5) it becomes clear when you do not need it:
If you are only doing Batch training and inference you can as easily utilise the Data Warehouse and Feature Store is just an unnecessary overhead.
If you are only ingesting Batch Features it is also relatively easy to set up a batch job that would sync your Data Warehouse with an Online Storage.
Also from Graph 6 we can see that not having a Feature Store only becomes viable if the Backend Service already knows Feature Values when calling the ML Service.
We should consider adding a Feature Store if:
We are Working with Real Time Data.
The Features stored in the Feature Store are reused by multiple Machine Learning Models.
The Features are expensive to compute and we don’t want to do that each time we train a model or apply inference.
We must introduce the Feature Store if:
The Feature set is not known by the Backend Service that is calling ML Service.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.
(Graph 1) Feature Stores might or might not have a Feature Transformation Layer that manages its own compute resources.
Can you elaborate more about this? Which vendors provides this layer?