
SAI #24: Feedback Loops in Machine Learning System.
I cover 3 main areas of feedback required in effective Machine Learning System.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
Your Machine Learning Models are only useful when deployed. You can keep them being useful only by observing their behaviour in production. This week I cover feedback loops that you must implement in your Machine Learning System to have effective overview over it.
Before doing that, let’s take a birds-eye view into stages involved in a typical Machine Learning Project:
A: All begins at the ideation stage where business meets data professionals to raise a hypothesis that is evaluated against the feasibility. They do so by answering questions like:
Do we need Machine Learning to solve the problem?
Do we have data assets needed to build the Machine Learning model?
Will acquiring such assets eventually result in a positive ROI?
Can Machine Learning Systems that are currently available handle the business use case when implemented?
…

B: Once it is agreed that you want and need to build the model - data scientists experiment with the available data assets to build the PoC of the model which is handed over to the next stage:
C: The model is productionised by transforming it into a Machine Learning System - in modern MLOps this would usually mean a ML Pipeline deployed into production environment enabling Continuous Training (CT). This stage also makes your ML Service part of the wider Software System.
D: Monitoring Stage is where you track performance of your models running in Production. This is also from where the feedback will be fed into previous stages creating the feedback loop we are interested in.
The Feedback Loops.

There are 3 main types of feedback flowing back to your Machine Learning System that you must implement.
A (Figure 2): There is a single type of feedback flowing from Monitoring to Experimentation stage. It is Online Testing - it means monitoring of a business metric in production that you decide to evaluate your model on. The choice will depend on the type of your business, some popular ones being conversion rate, click-through rate, revenue per user etc. The most popular methods of implementing online testing are:
A/B Testing - you deploy two models to production, expose X% of your users to a control model (usually the model that won previous A/B Testing process) and (100 - X)% to a challenger model. You run this experiment until a statistically significant difference between metrics being produced by the models is shown. You continue to expose the winner model as control to your user base while you deploy a new challenger model to compete against it.

Multi-armed bandits - you deploy multiple models. The best performing model is exposed to the largest portion of your user base. Business metrics are continuously calculated in the backend and the proportions of exposure are shifted in the favour of best performing model.

Interleaving Experiments - each user in the user base is exposed to multiple models at the same time. A good example is ranking of search results in your website - in this case multiple models would rank the search candidate set and then the top results from all models would be mixed and shown to the user. This approach is limited to the type of metrics that models can be evaluated on - it works well for metrics like click-through rate but it would be hard to assign metrics like revenue per user to a specific model.
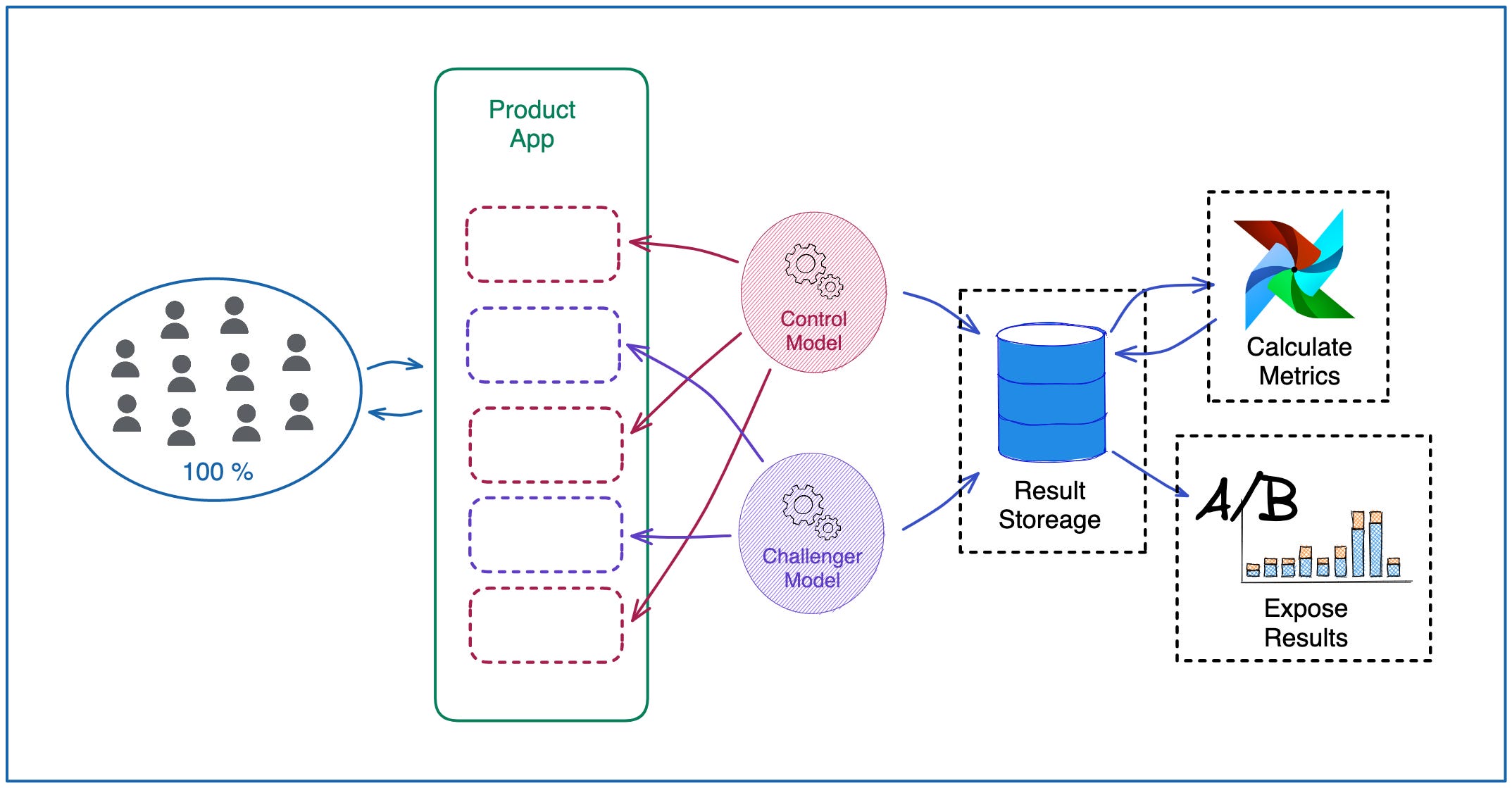
Online Testing is the feedback loop that gives visibility to Data Scientists on what does and doesn’t work in their experiments and drives direct business value improvement of your ML Systems.
B (Figure 2): There are two types of feedback flowing from Monitoring to Deployment Stage:
First type is the regular service monitoring. You monitor things like service latency, response codes, hardware consumption etc. We will not go deeper into this type of feedback as it is not specific to Machine Learning Systems.
The second type is related specifically to the nature of Machine Learning Systems and it is monitoring of Feature and concept Drifts. Here is a short explanation of both:
Feature Drift: Also known as Data Drift.
It happens when the population on which the model inference is performed shifts which essentially means that you start applying ML Models on data that they have been under-trained on.
Examples:
👉 You increase exposure to one particular marketing channel which you haven’t had enough exposure to before.
👉 You are moving into new markets.
👉 You trained your object detection model on a brightly lit images. However, the location where you are applying it in real time generated photos is dark.
👉 You train your speech recognition models on a high quality audio. However, there is lots of background noise at the location where it is being applied.

Concept Drift: This phenomenon occurs even when the distribution of the data you feed to the model does not change. It’s the functional relationship between model inputs and outputs that changes.
Examples:
👉 You use geographical regions to predict housing prices, as the economical situation over time in the region changes so will the house prices.
B type ML System related feedback loop is extremely important to the people operating Machine Learning Models in production - any detected drift signals that it might be about time to retrain the models even if no change in the model parameters is needed.