

SAI #26: Partitioning and Bucketing in Spark (Part 1)
Let's look into the difference between Partitioning and Bucketing in Spark.

👋 This is Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. The goal is to help You UpSkill and keep you updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
For me, partitioning of data in Spark has always been the area that was hard to master. Nevertheless, learning it is worth the effort as it will improve your querying and processing performance in complex data processing jobs significantly. There are two main ways of how you can logically and physically split the data in Spark:
Partitioning is a very well known technique that every Data Engineer using Spark has performed in their day-to-day.
Bucketing is a technique that strikes fear as both the concept behind it and successful implementation is hard to grasp.
In this newsletter episode we will look from a high level into the difference between the two, we will delve deeper in the future episodes.
Why do we partition the data?
When working with big data there are many important things we need to consider about how the data is stored both on disk and in memory, we should try to answer questions like:
Can we achieve desired parallelism?
Can we skip reading parts of the data?
How is the data colocated?
Answer to the first question is connected to splitting the datasets into multiple pieces that are then stored on disk - in most of the systems we call these pieces partitions.
In Spark, the second question is addressed by partitioning and bucketing procedures while the third - by bucketing only.
Procedure causing the largest hit on Spark Job performance is Shuffle. It is so because:
It requires movement of Data through the Network.
Shuffle procedure also impacts disk I/O since shuffled Data is saved to Disk.
Shuffle is triggered by so called Wide transformations. Here is a short description:
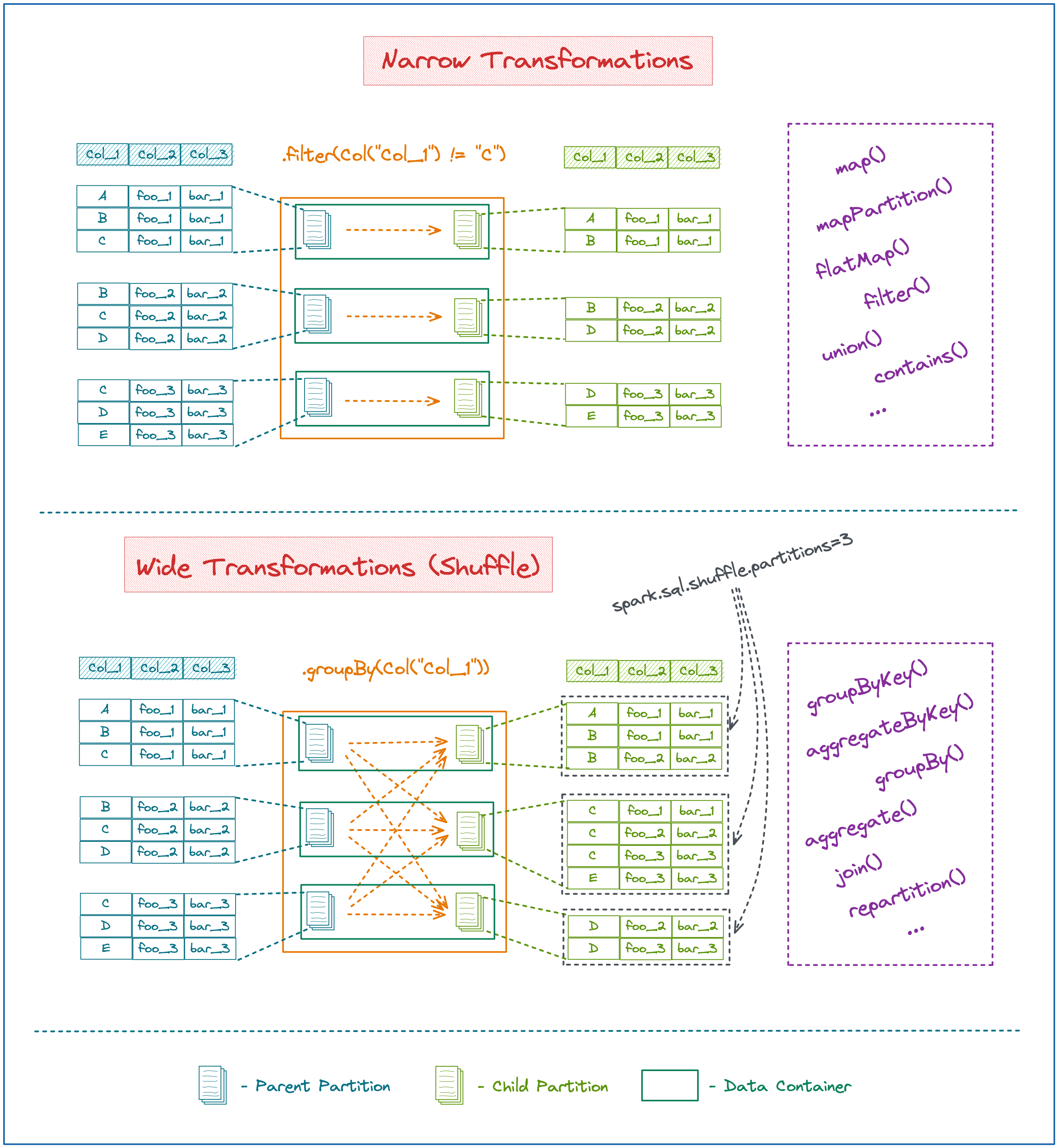
Narrow Transformations
These are simple transformations that can be applied locally without moving Data between Data Containers.
Locality is made possible due to cross-record context not being needed for the Transformation logic.
E.g. a simple filter function only needs to know the value of a given record.
Functions that trigger Narrow Transformations are map(), mapPartition(), flatMap(), filter(), union(), contains() etc.
Wide Transformations
These are complicated transformations that trigger Data movement between Data Containers.
This movement of Data is necessary due to cross-record dependencies for a given Transformation type.
E.g. a groupBy function followed by sum needs to have all records that contain a specific key in the groupBy column locally. This triggers the shuffle.
Functions that trigger Wide Transformations are groupByKey(), aggregateByKey(), groupBy(), aggregate(), join(), repartition() etc.
Conclusion: Tune your applications to have as little Shuffle Operations as possible.
Partitioning
Partitioning is the most widely used method that helps consumers of the data skip reading the entire dataset each time only a part of it is needed.
Partitioning in Spark API is implemented by .partitionBy() method of the DataFrameWriter class. You provide to the method one or multiple columns to partition against. The output is the dataset written to disk split by the partitioning column, each of the partition is saved into a separate folder on disk, each folder can maintain multiple files (this behaviour is controlled by the setting spark.sql.shuffle.partitions that denotes the amount of shuffle partitions).

We want to partition data because it allows Spark to perform Partition Pruning. This means that given we filter on a column that we used to partition the dataframe, Spark can plan to skip the reading of files that are not falling into the filter condition.
The problem with partitioning is that each distinct value in a column will result in creation of a new folder (partition). This eventually prevents us from using high cardinality columns for partitioning purpose as it would result in too many files being created on disk.

Additionally, partitioning does not give us much when it comes to data colocation hence not helping to avoid shuffle during wide transformations. Let's look into how Bucketing can help with this issue.
Bucketing
Bucketing in Spark API is implemented by .bucketBy() method of the DataFrameWriter class. The procedure of Bucketing can be described by the following diagram.
It is important to note that in Spark we can perform bucketing only when saving the dataset as a table since the metadata of buckets has to be saved somewhere. Usually, you will see Hive metadata store leveraged here.
You can bucket on one or multiple columns of your dataset, you will need to provide number of buckets you want to create. Bucket number for a given row is assigned by calculating a hash on the bucket column and performing modulo by the number of desired buckets operation on the resulting hash.
All rows of a dataset being bucketed are assigned to a specific bucket.
The previous procedure results in rows with the same bucket column values collocated together when saved to disk. Why is it important?
If we run the bucketing procedure with the same amount of buckets on two dataframes and bucket them both on the column which is intended to be used for joining the given dataframes, we essentially mirror the colocation of join keys in the resulting buckets. This means that once Spark performs a join between the two dataframes, it does not need to shuffle the data as the required data is already collocated in the executors correctly and Spark is able to plan for that.
The same goes when only a single dataframe is involved in a wide transformation, e.g. column values for groupBy operation will be always colocated together avoiding the Shuffle.
So when to Partition and when to Bucket?
The answer can be summarised as follows:
If you know that you will often perform filtering on a given column and it is of low cardinality, partitioning on that column is a way to go.
If you will be performing complex operations like joins, groupBys and windowing and the column is of high cardinality, you should consider bucketing on that column.
There are many caveats and nuances you need to know when it comes to Bucketing specifically. We will be doing a deep dive into both Partitioning and Bucketing in one of the future episodes.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.