
SAI Notes #02: Encoding in Parquet.
Let's look into the types of Encoding in Parquet Files.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This week in the weekly SAI Notes:
Encoding in Parquet.
Dictionary Encoding.
Run Length Encoding (RLE).
Combining Dictionary Encoding and RLE.
Delta Encoding.
Taking advantage of parquet encoding when using Spark.
Encoding in Parquet
There are many cases when we might want to transform original data into different representation. It could be done to allow the embedding representation to cary more context (e.g. Deep Learning embeddings) or to reduce the size required to store the data on disk and in memory (e.g. Parquet encodings).
To process the encoded data you will need to decode it, but usually the decoding procedure that is required is more lightweight then I/O costs incurred when reading data or sending it over the network.
Today, we will look into lossless encoding techniques (no data is lost after we decode the data) implemented when writing Parquet Files:
There are three main types of encoding used in Parquet Files:
Dictionary Encoding.
Run Length Encoding (RLE).
Delta Encoding.
Let’s look into all of them in more detail and try to understand why and when it makes sense to use each.
Dictionary Encoding
These are the steps taken by Dictionary Encoding:
Each of the distinct values per column are extracted into a dictionary (lookup table) and given a numerical index.
Initial values in the column are replaced by these indexes and are later mapped via the lookup dictionary.
When does it make sense to use Dictionary Encoding?
The data in the column is of low enough cardinality.
Given a most extreme case when all of the values in a column are unique, this encoding approach would increase the storage needed as the dictionary would map to each value one-to-one. Consequentially we would add the index values two times (one in the Column itself and one in the dictionary).
Additional benefits of Dictionary Encoding:
Ordering of the values is not important.
All datatypes can be encoded for efficient file size reduction.
Run Length Encoding (RLE)
These are the steps taken by Run Length Encoding (RLE):
Table columns are scanned for sequence of repeated values.
Sequence of repeated values is transformed into object containing two values:
Number of times the value was repeated sequentially.
The value itself.
The column is then transformed into sequence of these two value objects.

When does it make sense to use Run Length Encoding (RLE)?
The data in the columns are ordered.
The data is of low enough cardinality.
Similarly like in dictionary encoding case, given a most extreme case when all of the values in a column are unique, this encoding approach would increase the storage needed as there would be a new entry created in the column for each row in the column.
Additional benefits of Run Length Encoding:
The compression achieved can be significant given a low cardinality nature of the column.
In the most extreme case where the column only has a single unique value, you would only need to write two values after the encoding - the number of times the value repeats and the value itself.
Combining Dictionary Encoding and RLE
Given the ideal scenario when the data is fully ordered in each column, it would not make sense to use anything other than RLE, however this is never the case in the real world as you will have to order the column sequentially which will reduce the orderliness of values each time we sort.
This is why it extremely beneficial to combine both Dictionary and RLE encodings sequentially.
These are the steps taken in this case:
Apply dictionary encoding on the column.
Apply RLE encoding on the resulting column using the index values in the column that was result of the previous step.
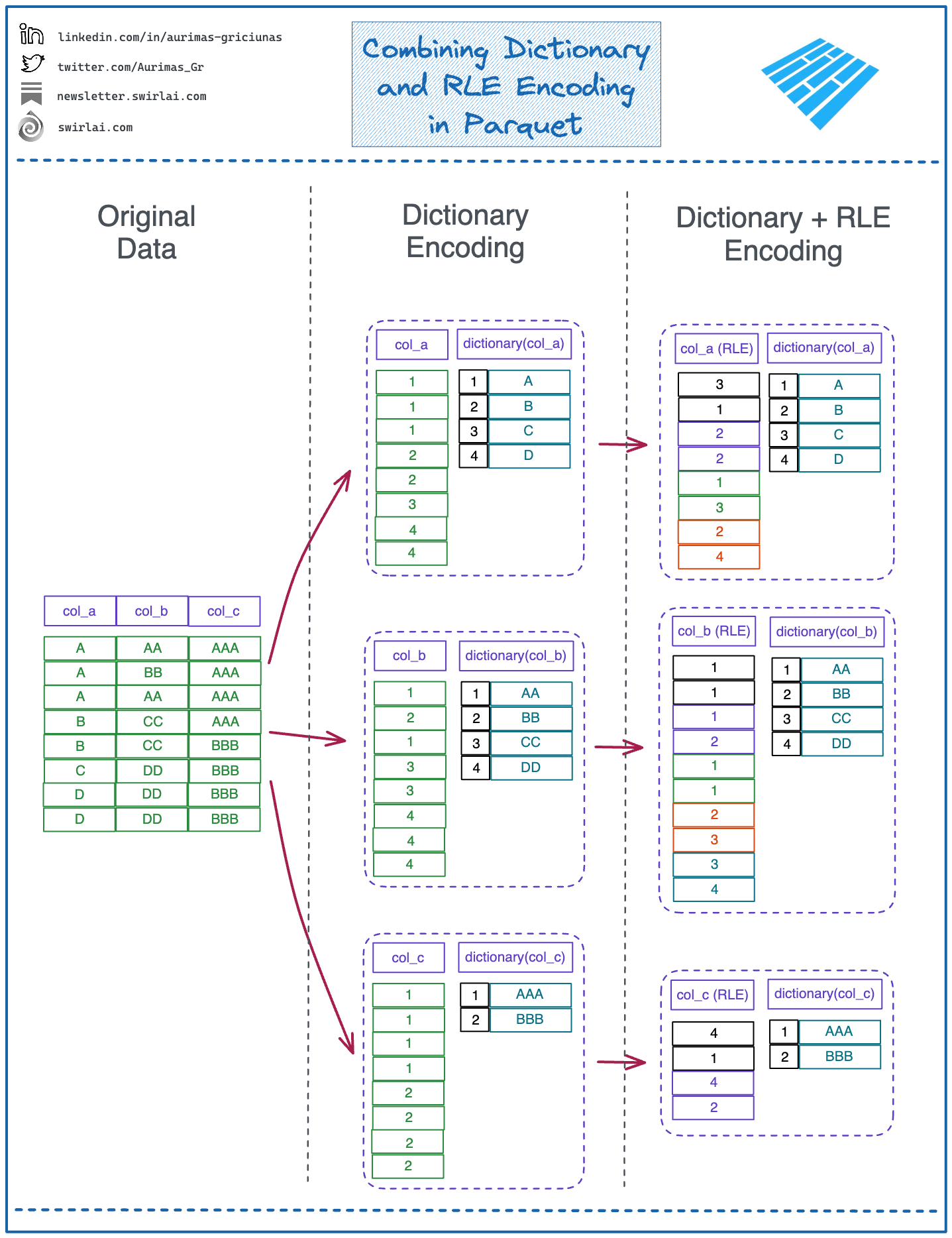
When does it make sense to combine Dictionary and RLE encodings?
The data in the column is both well ordered and of low enough cardinality.
Given a most extreme case when all of the values in a column are unique, this combination of encoding procedures would increase the storage needed as there would be a new entry created in the column for each row in the column and an additional dictionary entry per original value.
Delta Encoding
One more encoding technique that is often overlooked is called Delta Encoding. These are the steps taken by Delta Encoding:
Record the first value of the column.
Calculate the difference between the current value and the previous value and save it as record representation.
Move to the next record in the column and apply the previous procedure.
Continue until you reach the end of the column.
When does it make sense to use Delta Encoding?
Original column type takes up a lot of space.
The column is of high cardinality.
The variation between consequent record values in the column is low.
A very good example of when Delta Encoding makes sense is the timestamp columns of time series data. Why?
Each of the values in the column is very likely to be unique.
Timestamp Data Type takes a lot of space.
Difference between consequent values is likely to be low (single digit seconds or milliseconds)
Each of the timestamp values gets replaced by a small integer.
Taking advantage of parquet encoding when using Spark
Here are few important notes:
Encoding on parquet is really write time optimisation that is then utilised when reading and processing data.
Spark implements previously mentioned encoding techniques automatically and out of the box when writing data.
You need to correctly order the data for the encodings to produce good compression results.
Let’s understand how we should prepare the data before writing it to parquet:
Remember that the techniques work best for ordered columns of low cardinality.
We are very likely to be performing some sort of partitioning when writing parquet.
You will want for the ordering to be persisted after the data is partitioned.
Here is how you take advantage of previous information:
First sort your Spark Dataframes by the columns you will be partitioning by.
Then, in the same .sort() or .orderBy() call include remaining columns you would like to utilise in the increasing order of cardinality.
[IMPORTANT]: Sorting of Spark Dataframes invokes shuffle operation which is expensive. You should weigh the gain of encoding the data against the cost of shuffle carefully.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.