
SAI Notes #04: CI/CD for Machine Learning.
Let's look into how CI/CD is different for ML projects compared to regular software.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This week in the weekly SAI Notes:
CI/CD for Machine Learning.
Organisational Structure for Effective MLOps Implementation.
ML Systems in the context of end-to-end Product Delivery.
CI/CD for Machine Learning.
MLOps tries to bring to Machine Learning what DevOps did for regular software. The important difference that Machine Learning aspect of the projects brings to the CI/CD process is treatment of Machine Learning Training pipeline as a first class citizen of the software world.
A large misalignment that I see in the industry is ML Training Pipelines being not treated as a separate entity from CI/CD Pipelines and their steps being executed as part of the CI/CD Pipeline itself. So let’s establish this:
CI/CD pipeline is a separate entity from Machine Learning Training pipeline. There are frameworks and tools that provide capabilities specific to Machine Learning pipelining needs (e.g. KubeFlow Pipelines, Sagemaker Pipelines etc.).
ML Training pipeline is an artifact produced by Machine Learning project and should be treated in the CI/CD pipelines as such.
What does it mean? Let’s take a closer look:
Regular CI/CD pipelines will usually be composed of at-least three main steps. These are:
Step 1: Unit Tests - you test your code so that the functions and methods produce desired results for a set of predefined imputs.
Step 2: Integration Tests - you test specific pieces of the code for ability to integrate with systems outside the boundaries of your code (e.g. databases) and between the pieces of the code itself.
Step 3: Delivery - you deliver the produced artifact to a pre-prod or prod environment depending on which stage of GitFlow you are in.
How does it look like when ML Training pipelines are involved?

Step 1: Unit Tests - in mature MLOps setup the steps in ML Training pipeline should be contained in their own environments and Unit Testable separately as these are just pieces of code composed of methods and functions.
Step 2: Integration Tests - you test if ML Training pipeline can successfully integrate with outside systems, this includes connecting to a Feature Store and extracting data from it, ability to hand over the ML Model artifact to the Model Registry, ability to log metadata to ML Metadata Store etc. This CI/CD step also includes testing the integration between each of the Machine Learning Training pipeline steps, e.g. does it succeed in passing validation data from training step to evaluation step.
Step 3: Delivery - the pipeline is delivered to a pre-prod or prod environment depending on which stage of GitFlow you are in. If it is production environment, the pipeline is ready to be used for Continuous Training. You can trigger the training or retraining of your ML Model ad-hoc, periodically or if the deployed model starts showing signs of Feature/Concept Drift.
Organisational Structure for Effective MLOps Implementation.
What is the Organisational Structure for Effective MLOps Implementation?
MLOps strives to deliver to ML Products what DevOps does for regular software. However, delivering an end-to-end MLOps best practices based Machine Learning Product is not an easy task.
While MLOps tooling space is already highly mature, I see a lot of inefficiencies in MLOps implementation due to ineffective organisational structures.
DevOps principles dictate:
👉 Software development should flow inside of a single team boundaries without unnecessary cross team handovers.
👉 Feedback from a deployed product should also efficiently flow inside of a single team.
The same principles should be followed when delivering ML Systems. Here are some of my thoughts:
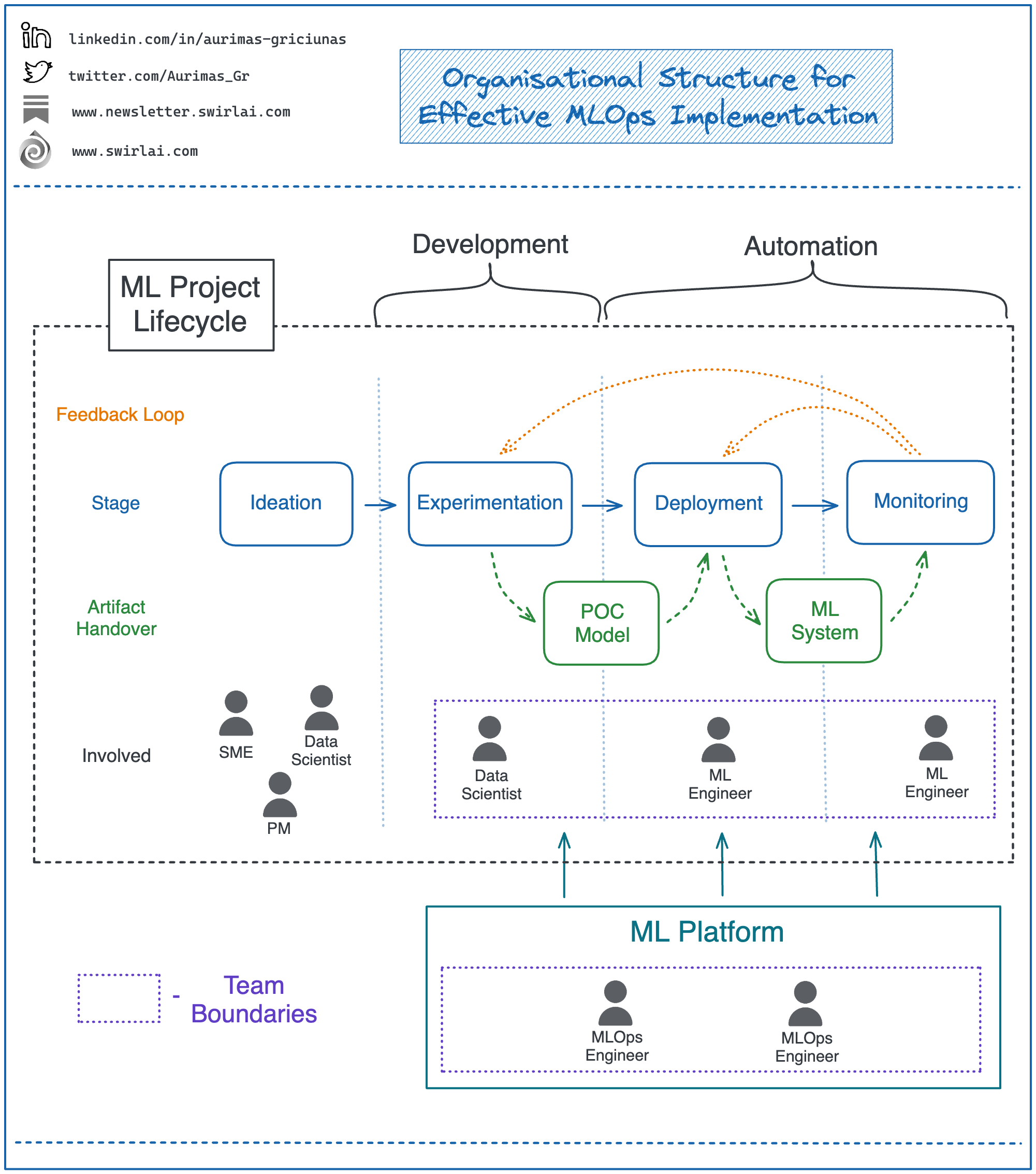
➡️ ML Product development has to efficiently flow inside of a single end-to-end ML Team comprised of Data Scientists and ML Engineers. Any handover outside of the team should be eliminated and the feedback should also flow without any interruptions in the boundaries of the same team.
➡️ The main factor preventing this from happening is the Extraneous Cognitive Load placed on such an end-to-end ML Team as the amount of tools and capabilities required for delivery of end-to-end ML Product is huge.
➡️ We need a ML Platform Team that would support end-to-end ML Teams when implementing MLOps practices. By doing so we remove excessive Extraneous Cognitive load from the end-to-end ML Team.
➡️ Previous point involves management and maintenance of infrastructure required to deliver ML Products as well as working together with end-to-end ML Teams to understand what new capabilities should be added to the ML Platform.
➡️ Inside of the end-to-end ML Team, Data Scientists are responsible for iteration over the ML Product while ML Engineers are responsible for stitching up the capabilities provided by ML Platform and providing automation to the ML Product.
[Important]: There is no free lunch. Platform teams come with a huge cost and they could even hurt the effectiveness of end-to-end ML Teams if not set up correctly. Also, you only need a Platform Team once you start scaling the amount of ML Projects pushed to production.
ML Systems in the context of end-to-end Product Delivery.
Machine Learning Systems do not live in isolation and are part of a larger ecosystem that allows to expose ML Predictions to the End User.
Let’s take a closer look into how this system usually looks like in a mature MLOps setup:
End-to-end ML Teams build and deliver ML Systems that are deployed in the form of Machine Learning Pipelines.
These Pipelines create Machine Learning models that expose inference results in one of the three main ways - Batch, Stream, Real Time.
Inference results from previous step are exposed under a given contract, general backend services implement the contract to retrieve the inference results to be used in Product applications.
Backend services expose the Inference results enriched with business logic via a REST or gRPC API. Backend services are queried in real time by Frontend Services
Frontend Service exposes business logic to the End User.

Why is this important? Here are few of the reasons:
A. Backend and Frontend Services are developed by the Product Delivery Teams. This means that when it comes to ML powered features, there are usually at-least two teams involved in developing the application logic responsible for serving the End User.
B. The Online Testing (A/B Tests, Interleaving Experiments, Multi-armed bandits) is performed against actions that are made by the End User. According to MLOps and DevOps principles, this feedback has to flow without interruption to the team responsible for building ML Models, which is the end-to-end ML Team.
C. Choosing which ML Models are deployed to production for A/B testing is usually implemented on the boundary of ML Service and the Backend Service in a form of a Feature Toggle that is part of the Backend Service - this is usually also implemented via part of a Developer Platform that is not exposed through the ML Platform. Consequently, end-to-end ML Teams do not have direct control of which model versions are exposed to the End User for online testing.
[Important]: In order to enable continuous development and feedback flow inside of the boundaries of end-to-end ML Team, you need to expose the capability of choosing what combination of models are deployed for A/B testing to the team.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.
New subscriber, long time reader - love your work. One thing I could suggest to make your content go above and beyond, is to have a git code version of your concepts outlined. Even just a really simple overview of how some of the key concepts are brought together (e.g. an automated retraining pipeline). Obviously an entire project with the end to end integration of components etc. all built out is a pipe dream, but just some code examples of key aspects of your articles would be awesome!
I tend to agree with what you’ve outlined here Aurimas.
The benefits you’ve listed are in my mind some of the strongest indicators of successful organisations, particularly those in environments that reward rapid innovation. Collocation ultimately reduces a lot of wasted effort, which should positively impact quality and velocity.
The challenges are also big headwinds, and something that any team looking to try this approach must be fully aware of. I think they are also ultimately solvable challenges, with perhaps the toughest being that of finding a single threaded technical lead for the team. Maybe that’s not important? Having an ML lead and a technical lead that can collaborate may solve for this without the hunt for an elusive jack of all trades (this has its down sides too).
The reason I made this comment is that I have just finished a 3 week project where we collocated and the results were really quite amazing. We were able to move quickly, and the empathy you speak of missing... well by working together we learn to understand one another. Happy to keep diving into this with you as I think it’s a fascinating pattern that may yield great results.