
SAI Notes #06: Machine Learning Model Compression.
Let's review the methods of Compressing Machine Learning Models and why you might need it.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This week in the weekly SAI Notes:
Machine Learning model compression and why you might need it.
Thoughts on Latency of Feedback Loops in Machine Learning applications.
Machine Learning model compression and why you might need it.
When you deploy Machine Learning models to production you need to take into account several operational metrics that are in general not ML related. Today we talk about two of them:
👉 Inference Latency: How long does it take for your Model to compute inference result and return it.
👉 Size: How much memory does your model occupy when it’s loaded for serving inference results.
Both of these are important when considering operational performance and feasibility of your model deployment in production.
👉 Large models might not fit on a device if you are considering edge deployments.
👉 Latency of retrieving inference results might make business case non feasible. E.g. Recommendation Engines require latencies in tens of milliseconds as ranking has to be applied as the user browses your website or app in real time.
👉 …
You can influence both latency and model size by applying different Model Compression methods, most popular of them being:
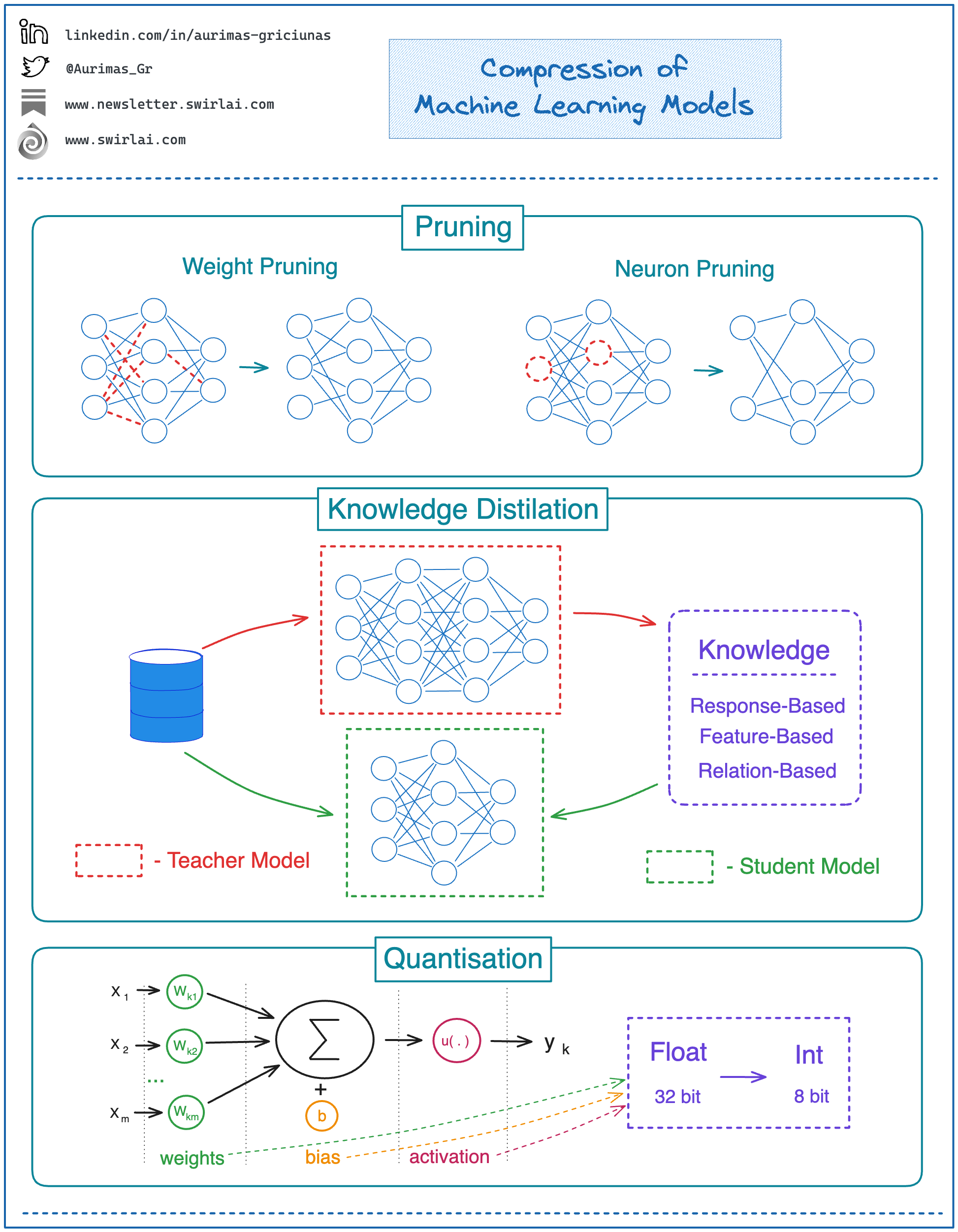
➡️ Pruning: this method is mostly used in tree-based and Neural Network algorithms. In tree-based ones we prune leaves or branches from decision trees. In Neural Networks we remove nodes and synapses (weights) while trying to retain ML performance metrics.
✅ In both cases the output is a reduction in the number of Model Parameters and model size.
➡️ Knowledge Distillation: this type of compression is achieved by:
👉 Training an original large model which is called the Teacher model.
👉 Training a smaller model to mimic the Teacher model by transferring knowledge from it, this model is called the Student model. Knowledge in this context can be extracted from the outputs, internal hidden state (feature representations) or a combination of both.
👉 We then use the “Student” model in production.
➡️ Quantisation: a most commonly used method that doesn’t have much to do with Machine Learning. This approach uses fewer bits to represent model parameters.
👉 You can apply quantisation techniques both during the training and after the models has been already trained.
👉 In regular Neural Networks what is quantised are Model Weights, Biases and Activation Functions.
👉 Most usual quantisation is from float to integer (32 bits to 8 bits).
➡️ …
[Important]: while the above methods do reduce the size of the models and by doing so allowing them to be deployed in production scenarios, there is almost always a reduction in accuracy so be careful and evaluate it accordingly.
Thoughts on Latency of Feedback Loops in Machine Learning applications.
Feedback Loops are something constantly overlooked during the planning phase of Machine Learning Projects.
There are numerous questions in the Feedback Loop context that you need to answer before you start working on building the ML model that will help push your business forward. Two obvious ones are:
➡️ Are my Software Systems ready to provide feedback?
A deployed ML model will eventually take shape resembling a regular Software Application. Even the simplest model with a capability of instant feedback will need to receive it from an application serving the product to the customer. This means the ability to log specific actions that happen in your application - be it backend or frontend.
There are different aspects you need to consider for different types of deployments.
Example: given ML Model deployed as a Real Time Service, you can log your model inference results from the server itself or gather application feedback from JavaScript in customers device. If it is an Edge deployment you might need both prediction and frontend application logs traversing the public internet.
➡️ How long will it take to get feedback once inference is made?
The answer to this question could vary from milliseconds to hours to well… forever. It really depends on the problem being solved and the business metric you will be using to evaluate the model. I like to split the latency of the feedback into three main clusters:
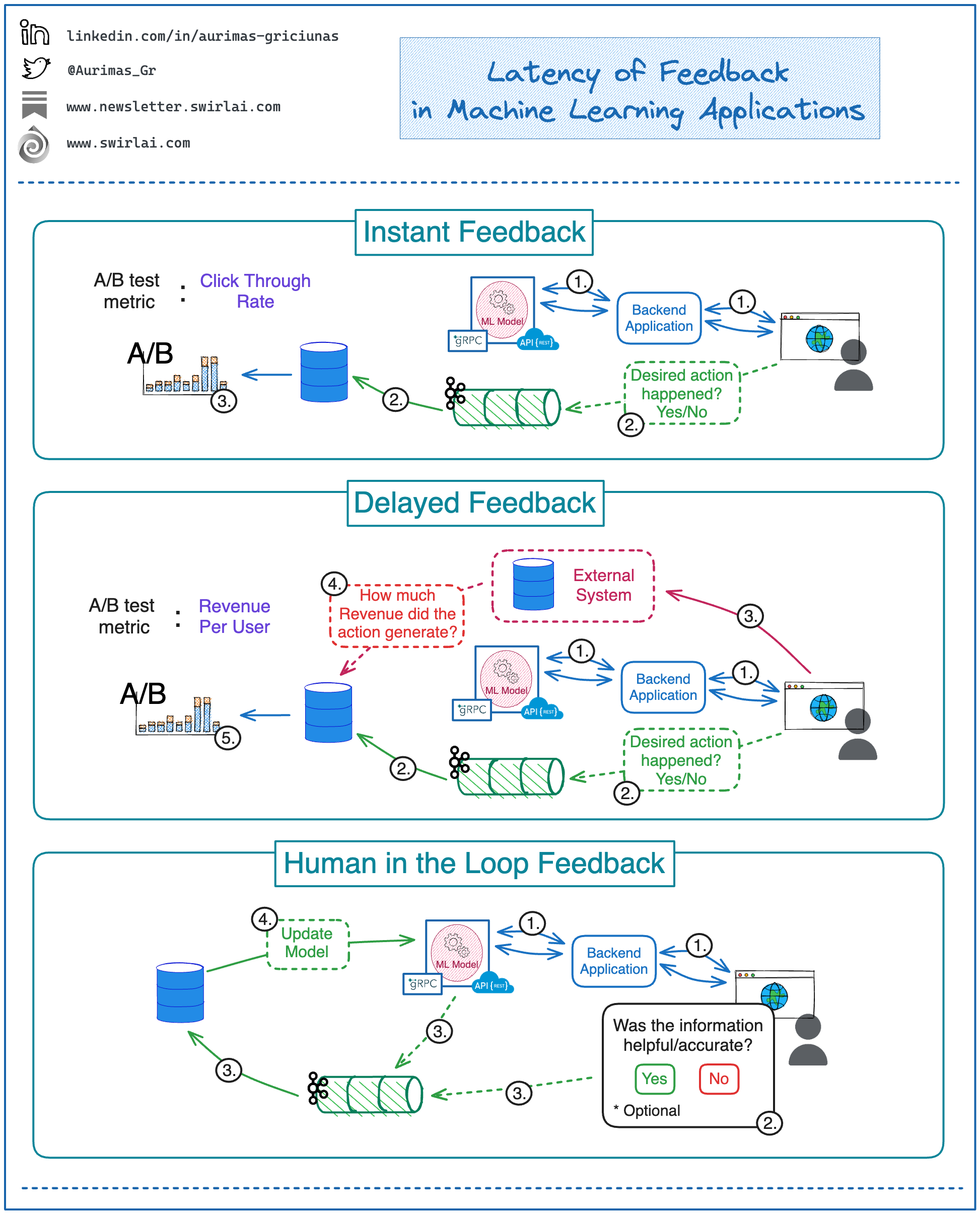
👉 Instant Feedback.
These are applications that return business metrics instantly. A good example is recommendation engine where we only care about if the user clicked on a recommendation.
Example high level architecture.
1: While the user is browsing a website, the frontend application is requesting recommended items from the chain of a backend application and a ML model exposed as a Real Time service (there are usually two or more models deployed for A/B testing). Recommendation is generated and shown to the user.
2: User either clicks on the recommendation or not. Information about the action is propagated to the Data Warehouse.
3: Data is aggregated for statistical A/B Test results. We use Click Through Rate to determine the winner of the test.
👉 Delayed Feedback.
These applications are usually tested against business metrics that are not only action based but care about some other business metric as well. A good example is generated revenue, while some systems will be able to estimate the revenue instantly, it is more common to receive revenue numbers in batch mode once per day or on a different schedule. Recommendation engine could be used as an example as well.
Example high level architecture.
1: Same as the previous example.
2: Same as the previous example.
3: This time around, even if the click-out happens, the revenue received depends on the actions taken by the user in the website that the user has clicked-out to and we do not control anymore. The third party calculates the money it owes to us and every day sends over the aggregated information with the identifier of the click-out id.
4: Data is joined to the user sessions identifying specific models that generated the click-out and revenue data is then aggregated for statistical A/B Test results. We use Revenue per User to determine the winner of the test.
👉 Human in the Loop Feedback.
Models that work with image classification or language translation could never get any feedback unless you implement the ability for the user to give the feedback manually.
Example high level architecture.
1: We are providing a Language Translation (or GPT like) service in the form of a website. A user enters a text in a given language and we translate it to a selected one.
2: Once the translation is generated, a popup appears where the user can optionally provide feedback - choose if the translation was accurate or not.
3: The feedback data together with the original and translated text is propagated to the Data Lake.
4: The Data is used to continuously improve the Translation model.
[Important]: Don’t get into a situation where you have a model running in production but no means of monitoring its predictive capability to solve your Business Problem.
Join SwirlAI Data Talent Collective
If you are looking to fill your Hiring Pipeline with Data Talent or you are looking for a new job opportunity in the Data Space check out SwirlAI Data Talent Collective! Find out how it works by following the link below.