
SAI Notes #08: LLM based Chatbots to query your Private Knowledge Base.
And how you can build one easily.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This week in the weekly SAI Notes:
Why can’t you use available commercial LLM APIs out of the box to query your Internal knowledge base.
Different ways you could try to implement the use case.
Easy way to build a LLM based Chatbot to query your Internal Knowledge Base using Context Retrieval outside of LLM.
There is an increasing number of new use cases discovered for Large Language Models daily. One of the popular ones I am constantly hearing about is document summarisation and knowledge extraction.
Today we look into what an architecture of a chatbot to query your internal/private Knowledge Base that leverages LLMs could look like and how a Vector Database facilitates its success.
The article assumes that you are already familiar with what a LLM is. What is important here is the most simple definition of it - you provide context/query in the form of a Prompt to the LLM and it returns an answer that you can use for the downstream work.
Let’s return to our use case, a Chatbot that would be able to answer questions only using knowledge that is in your internal systems - think Notion, Confluence, Product Documentation, PDF documents etc.
Implementation approaches one could consider.
Why can't we just use a pure commercial LLM API like ChatGPT powered by e.g. GPT-4 to answer the question directly?
What are the problems with this approach?
Commercial LLMs have been trained on a large corpus of data available on the internet. The data has more irrelevant context about your question than you might like.
The data contained in your internal systems of interest might have not been used when training the LLM - it might be too recent and not available when the model was trained. Or it could be private and not available publicly on the internet. At the time of writing only data up until September 2021 is included in training of OpenAI GPT-3.5 and GPT-4 models.
Currently available LLMs have been shown to produce hallucinations inventing data that is not true.
The next approach one could think off:
Formulate a Question/Query in a form of a meta-prompt.
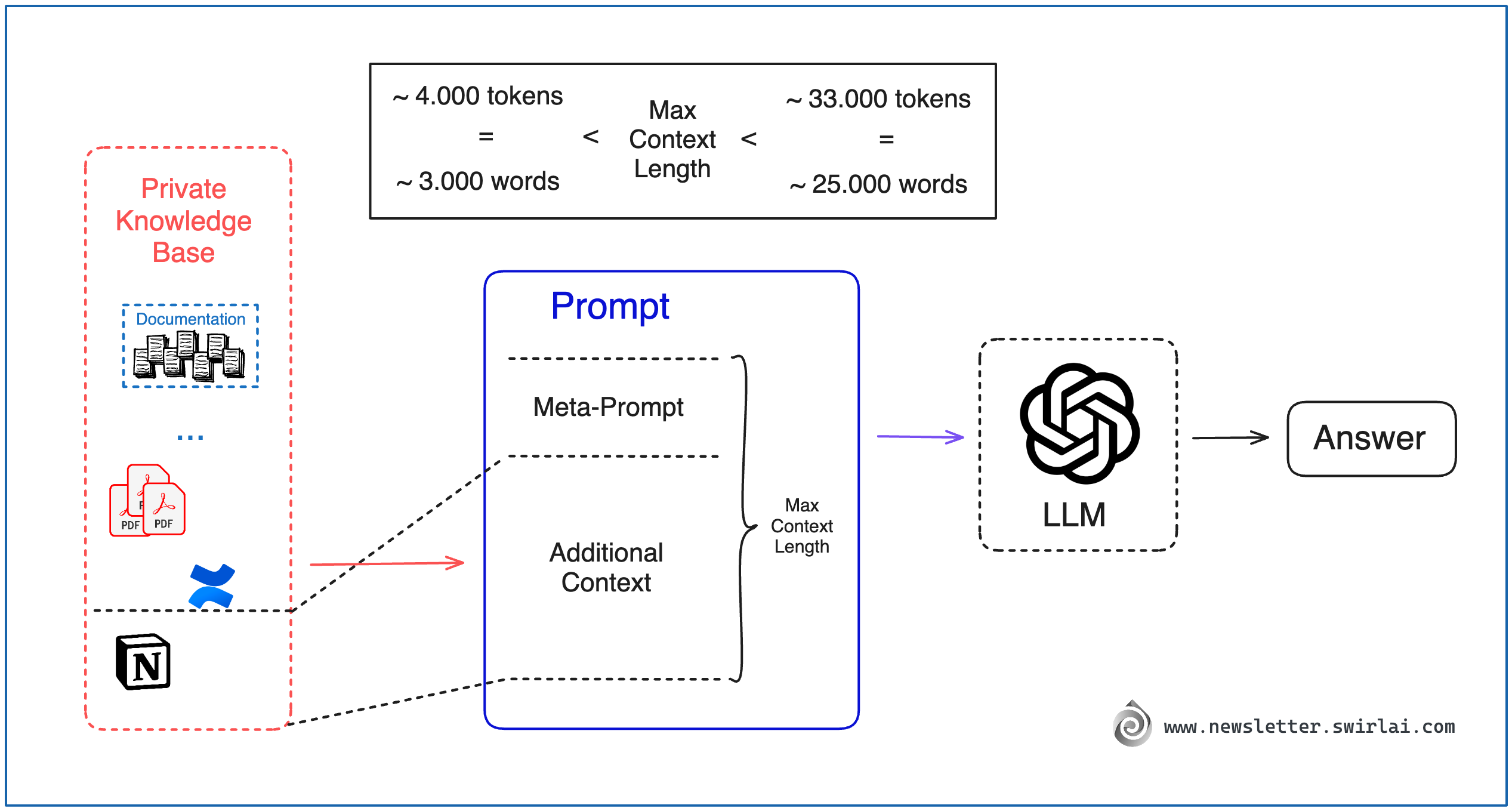
Pass the entire Knowledge Base from internal documents together with the Question via a prompt.
Via the same meta-prompt, instruct the LLM to only use the previously provided Knowledge Base to answer the question.
What are the problems with this approach?
There is a Token Limit of how much information you can pass to LLM as a prompt, it will vary for different commercially available LLMs.
At the time of writing the input context length varies from ~4.000 to ~33.000 tokens for different types of LLMs commercially available from OpenAI.
1.000 tokens map roughly to 750 words, so the maximum prompt length is ~25.000 words. It is a lot and could fit large amounts of information but will most likely not be enough for larger Knowledge Bases.
There are workarounds of how you could push more context to LLM like trying to compress the context or split it into several inputs.
Even if you would be able to pass the entire knowledge base to the prompt, Commercial LLM interface providers charge you for the amount of tokens you provide as a prompt. Additionally, there is yet no way to cache the knowledge base on the LLM side that would allow you to pass the relevant data corpus only once. Consequently, you would need to pass it each time you ask the question, which would inflate the price of API use tremendously.
One more approach could be:
Use an OSS model.
Fine-tune it on the corpus of your internal data.
Use the fine-tuned version for your chatbot.
What are the problems with this approach?
OSS models are inherently less accurate than commercial solutions.
You will need specialized talent and a large amount of time to solve the fine tuning challenge internally.
Fine Tuning does not solve the hallucination challenge of LLMs.
Hosting the LLM in house will be costly and require dedicated talent as well.
Input size limit is only partially solved, passing the Knowledge corpus each time when asking a question would be still too expensive.
So what is an easy to implement alternative?
Enter the context retrieval outside of the LLM. How does it work and how the architecture for the application utilizing it would look like?
First step is to store the knowledge of your internal documents in a format that is suitable for querying. We do so by embedding all of your internally held knowledge using an embedding model:
Split text corpus of the entire knowledge base into chunks - a chunk will represent a single piece of context available to be queried. Keep in mind that the data of interest can be coming from multiple sources of different types, e.g. Documentation in Confluence supplemented by PDF reports.
Use the Embedding Model (explanation of what an Embedding model is and how to choose one is out of scope for this article and will be covered in the later episodes) to transform each of the chunks into a vector embedding.
Store all vector embeddings in a Vector Database (We covered what a Vector DB is in an article here).
Save text that represents each of the embeddings separately together with the pointer to the embedding (we will need this later).

Next we can start constructing the answer to a question/query of interest:
Embed a question/query you want to ask using the same Embedding Model that was used to embed the knowledge base itself.
Use the resulting Vector Embedding to run a query against the index in Vector Database. Choose how many vectors you want to retrieve from the Vector Database - it will equal the amount of context you will be retrieving and eventually using for answering the query question.
Vector DB performs an Approximate Nearest Neighbour (ANN) search for the provided vector embedding against the index and returns previously chosen amount of context vectors. The procedure returns vectors that are most similar in a given Embedding/Latent space.
Map the returned Vector Embeddings to the text chunks that represent them.
Pass a question together with the retrieved context text chunks to the LLM via prompt. Instruct the LLM to only use the provided context to answer the given question. This does not mean that no Prompt Engineering will be needed - you will want to ensure that the answers returned by LLM fall into expected boundaries, e.g. if there is no data in the retrieved context that could be used make sure that no made up answer is provided.
To make it a real Chatbot - face the entire application with a Web UI that exposes a text input box to act as a chat interface. After running the provided question through steps 1. to 9. - return and display the generated answer. This is how most of the chatbots that are based on a single or multiple internal knowledge base sources are actually built nowadays.
We will build such a chatbot as an upcoming hands on SwirlAI newsletter series so Stay tuned in!
Thoughts around the current limitations discussed at the beginning of an article.
The limitations discussed are the problem of the current state of technology.
As technology advances, we might see the limits of the prompt lengths becoming increasingly longer.
Implementations of caching context on the LLM side is very likely to be built in the future, allowing to pass large corpuses of context once and reusing it.
Conclusion.
At this point in time the architecture of chatbots that are able to query Private Knowledge Bases are less complicated than one might think.
They have less to do with Machine Learning and are more of a Software Engineering feat to nail.
It is very unlikely that you would need to do any development on the LLM side and rather just use already existing LLMs as a glue for constructing answers to the question given extracted context.
Thank you for reading! If you like the content, consider supporting my work by subscribing and sharing the article in your circles.
Largely the accepted way of doing this for now, but it's far from perfect. In my experience your system prompt has to be very exact in order to stop it hallucinating. The other problem is with chunking the data itself - if you're passing several large documents and the chunks are of set length, it can and often will infer bad context just based on chunk cutoffs. Small, semi-structured individual documents seem to perform far better than chunking.
Can you an end to end project that covers:
RAG assistance In LLM based chatbots for context and reducing mistakes
Fine tuning open source LLM mode
Mixe media vector embedding
Re ranking things like that..
It will be onebigassproject for sure.