
A Guide to Kubernetes (Part 2): Different ways to deploy your application.
Deployments, Jobs, CronJobs and their use cases.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This is a continuation of the Part 1 on Kubernetes where we covered:
Why Kubernetes for Data Engineering and Machine Learning.
General Kubernetes Resources for application configuration:
Namespaces.
ConfigMaps.
Secrets.
Deploying Applications:
Pods.
Deployments.
Services.
As we have already covered in the first part of the article - Pods are almost never used by themselves. This is due to the fact that it would be hard to scale Pods almost in the same way as raw containers - you would need to define multiple Pods and make sure that they are always running. That is why K8s provides multiple special workload resources that take care of deploying and scaling sets of pods for you, you simply define the rules of how to do that.
Today we will talk about the different ways you can deploy sets of Pods to a Kubernetes cluster. We already covered one of the options in the last article - the Deployment. In this issue we will review it and introduce 3 new ways that supplement what Deployments can not do. The four ways are:
Deployment.
Job and CronJob.
DaemonSet.
StatefulSet.
In this Newsletter episode I cover :
Deployment.
Job and CronJob.
In the next one:
DaemonSet.
StatefulSet.
Together with explanations of each I will provide:
Use cases.
Example Kubernetes resource definitions that you can use to create the resources in your local or remote Kubernetes cluster.
This part of the guide assumes that you have successfully finished all of the setup requirements from Part 1 as they are needed for you to be able to follow the tutorial. Additionally, it will be useful to read through the entirety of Part 1 as we will be using terms explained there without spending much time explaining them in this article.
Why is it useful to know all of the ways to deploy an application in a Kubernetes cluster?
The premise has been set - you develop your application, containerise it and then deploy it to Kubernetes in the form of a Pod. This is how you deploy a single instance of your entire software system, most likely your system is composed of multiple applications. You will need multiple sets of applications running in your cluster performing different kinds of work and communicating with each other in different ways. In order to scale your end-to-end application flow, you will need to employ ways of horizontal and vertical scaling for different parts of the system.
This is where different ways of managing sets of Pods come into play. If you either already have worked with Kubernetes in real life, or you are about to, you will very soon run into situations where using Deployment for every application type cuts just short in specific functionalities.
Let's see why. It is very helpful to start thinking from the ground up and find out the functionalities each of the application deployment types lack. Let’s start with the Deployment.
Deployment
Deployment is a way to manage a set of multiple identical replicas of a Pod. Deployments are mainly used when we work with applications that do not need any statefulness for performed work.
You define a number of Pod replicas you want to have running in the K8s cluster, deployment makes sure that this amount of Pod is always running.
Deployment makes sure that each of the pods gets a unique name assigned. The names will always start with the deployment name appended with “-<random value>”.
Deployments manage releases of new versions of your Pods, once you change the definition of a pod - the Deployment makes sure that a new version is released gracefully according to the rules you defined. It does so by creating new versions of ReplicaSets that manage sets of Pods underneath while gracefully shutting down the old ones.
Deployments enable you to gracefully roll back to previous versions of deployed applications. The procedure is similar to what happens in the release of new Deployment versions.

Creating a Deployment
Let’s recap how we create a deployment. In this guide, similarly as in the Part 1, we will be using Kubernetes resource definition files in the form of Yaml to define the resources we will be creating.
Before we do anything, if you don’t have a namespace to which to deploy your applications, you can create one by running:
kubectl create namespace swirlaiSimilarly like in previous tutorials, we will be deploying our applications to the swirlai namespace. Save the following content into a file named deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: swirlai-deployment
namespace: swirlai
spec:
replicas: 3
selector:
matchLabels:
app: swirlai
template:
metadata:
labels:
app: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80For simplicity reasons, we are deploying a nginx container per Pod. If you are interested in more complex deployments, check out the first part of SwirlAI Data Engineering Project Master Template implementation where we code up and deploy a full fledged FastAPI service and deploy it as a Deployment that is capable of communicating with other applications in the cluster.
After you save the file, run
kubectl apply -f deployment.yamlCheck if everything executed correctly by running
kubectl get deployments -n swirlai
We can see that 3 pods have been started successfully and are operating as expected.
Definition of the Deployment resource is easily derived from the original Pod resource definition. There are additional properties unique to the Deployment, but anything that goes under .spec.template.spec is just a copy of .spec definition of the Pod resource definition file.

What happens if we delete one of the Pods managed by the Deployment?
Let’s try it out:
kubectl get pods -n swirlai
Note the name of one of the pods and delete it.
kubectl delete pod swirlai-deployment-65778fdd85-8jz7v -n swirlaiLet’s see what happens after the deletion
kubeclt get pods -n swirlai
As expected - the deleted pod will be recreated by the Kubernetes Controllers with a different Pod name.
Use cases for a Deployment
Stateless microservices. Regular web applications are almost always deployed as Deployments because they are designed to run indefinitely and get instructions about the work to be done from other applications.
Streaming applications when the application ID is handled automatically by the streaming framework used.
Why is Deployment not enough?
As you have most likely noticed, deployments are meant to manage indefinitely running applications. If the application fails or you delete one of the Pods that the Deployment is managing, they will be restarted in an attempt to heal the application and bring it to the desired state that you define via Deployment resource. So how do you manage applications that have finite work to perform and need to stop/exit once the work is done? Jobs and CronJobs are meant specifically for that.
Job and CronJob
Jobs are meant to cover for the Deployment inability to run finite work. A good example is a data extraction job. You download the required data, push it to the downstream data systems and terminate the application. While there are separate Frameworks targeted specifically for the use of Data Engineers (e.g Airflow), Kubernetes supports this natively with Jobs and CronJobs.
You define a number of times the defined Pod needs to exit with the successful state.
You define a number for the parallelism - how many Pods will be started at the same time to perform work. Each successful exit counts towards the required success count in the previous step.
A Job makes sure that the application succeeds this many times by continuously starting new Pods to keep the count of running Pods that is equal to defined Parallelism.
You define the number of retries you are comfortable with if Pods fail.
Similarly like in the case of Deployment, a Job makes sure that each of the pods gets a unique name assigned. The names will always start with the deployment name appended with “-<random value>”.
Before moving forward, let’s clean up our namespace:
kubectl delete deployments -n swirlai --allWhy do I cover Job first?
In the first part of SwirlAI Data Engineering Project Master Template implementation we implemented the Data Producer piece of the project as a Deployment. In the real world scenario, such an application would be either scheduled with a framework like Airflow or could be deployed directly to Kubernetes as a Job or a CronJob depending if we want to extract the data continuously on a schedule or once. We will rewrite the application to be in a form of a Job in the next episode of the SwirlAI Data Engineering Project Master Template series.
Creating a Succeeding Job
Copy the following code to the file named job.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: swirlai-job-success
namespace: swirlai
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)It is worth understanding some of the definitions:
As regularly, we are creating the Job in swirlai namespace.
The job is named swirlai-job-success because we are planning for this one to succeed.
In order for the job to succeed, we expect 5 Pods to finish in successful state as per .spec.completions.
2 Pods will be kept spawned (.spec.parallelism) to do the work as long there are completions to cover out of the 5 previously defined.
We only allow for one failure as per .spec.backoffLimit.

Similarly like with other resources you need to only plug in a pod definition under the .spec.template.spec. In the Job case this is a definition of work that we expect to succeed. For this example we will be using a Python container and execute Python code in it:
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)Super simple code that sleeps for 3 seconds, prints “I succeeded!” and exits with status code 0 which marks the successful execution of the script.
Let’s create the Job:
kubectl apply -f job.yamlCheck the status by running:
kubectl get jobs -n swirlaiAt the beginning you should see something like following.
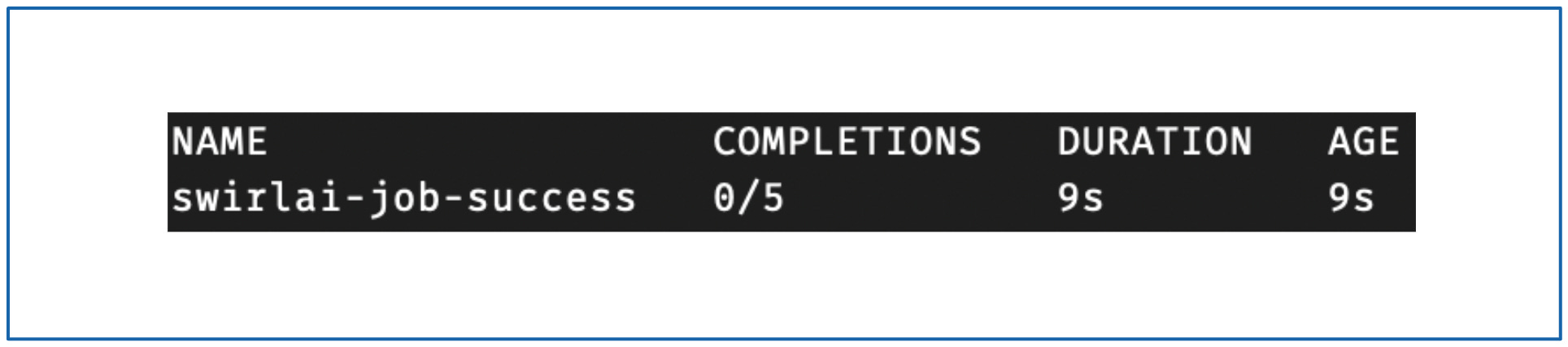
In a minute or so, after running the same command you should see:

This marks a succeeded job. If you would run
kubectl get pods -n swirlaiYou will see something similar to

This shows the five pods that succeeded to execute and were managed by the Job. By the age column we can also see that the Pods were executing in groups of 2 and the last one finished alone. Below picture represents the stages that led to a successful job completion.

Creating a Failing Job
Let’s do a minor change to the script that we are executing inside of the container:
import os, sys, time
time.sleep(3)
print("I Failed :(")
sys.exit(1)Lets save this to a job-fail.yaml:
apiVersion: batch/v1
kind: Job
metadata:
name: swirlai-job-failure
namespace: swirlai
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I Failed :(")
sys.exit(1)Now, instead of exiting with status code 0, the code will fail with status code 1. Let’s see what happens with the job
kubectl apply -f job-fail.yaml Inspect the result with
kubectl get jobs -n swirlai
Unfortunately, this is the state of the job that will not change further - it has failed. You can inspect the pods by running
kubectl get pods -n swirlai
As expected we started 2 Pods as per .spec.parallelism. The first fail indicated a failed Job and the Job Controller did not attempt to start any new Pods in attempt to achieve the required number of successes. The following picture describes the stages that the Job went through:

While Job covers the use case of running applications that are meant to complete finite amounts of work, it is still a lot of manual work if your goal is to perform this work on a schedule. This is where the CronJob resource comes in.
CronJob
A CronJob has a very intuitive name as it does exactly what the name suggests - creating Jobs on a Cron Schedule. For an example, let’s create a CronJob, that creates previously defined succeeding Job every 1 minute.
Add the following code to a file named cronjob.yaml:
apiVersion: batch/v1
kind: CronJob
metadata:
name: swirlai-cronjob-success
namespace: swirlai
spec:
schedule: "* * * * *"
jobTemplate:
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)The syntax is very intuitive when comparing to the Job resource definition, the relation is described in the following image:

Create the CronJob by running
kubectl apply -f cronjob.yamlLet Kubernetes do it’s job for a few minutes and then run
kubectl get jobs -n swirlai
After 3 minutes, we can see that the CronJob has created 3 new Jobs that all finished in a successful state.
Use cases for a Jobs and CronJobs
ETL jobs. If you want to do Extraction or Transformation Jobs in your ETL Pipeline, they would almost always run with the final state in mind. Even more likely they would be scheduled to run periodically, let’s say daily. Ofcourse, you would probably use a Framework like Airflow for your Data Engineering needs, but doing it directly on Kubernetes is also an option.
Performing updates on a Database schema that is already running.
Preparation of a file system or a Database for your other application that relies on it. While you could do that manually, a full fledged production system deployment on Kubernetes would usually include a database preparation job as part of your Resource definition bundle. Jobs are very often coupled with Deployments as while Deployments are locally stateless, very often they rely on a remote state of a Database.
Clean up tasks. These could be one-off or scheduled to perform clean up on e.g. a file system to clean up space for the application to function properly.
That’s it for today! Hope to see you in the next one.
Great article, thank you for that ! Could you write about a project using LLM-powered application + vector storage + Kubernetes ? I see a lot of those nowadays
The Job vs Deployment has been explained really well! Kudos!