
A Guide to Kubernetes (Part 1).
And why you want to master it as a Data Professional.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
This is the first part of my Guide to using Kubernetes.
I was introduced to Kubernetes (K8s) around 6 years ago while working as a ML Engineer. At that point in time the system was already popular and well known between technology enthusiasts and used in companies with strong engineering functions that needed capabilities that would allow seamless scaling of applications. From the moment I was introduced to the system I got obsessed with it and what it had to offer. As time went on I had touch points with K8s in most of the companies I’ve worked for, even led a Cloud Native Transformation in one of them. When Cloud Native Computing Foundation came out with their Kubernetes Certifications I naturally jumped on the boat and am currently a proud holder of all 3 of them - Certified Kubernetes Application Developer, Certified Kubernetes Administrator and Certified Kubernetes Security Specialist, or as better known for their acronyms - CKAD, CKA and CKS.
So why do I believe in Kubernetes? What problems does it solve? What do you need to know about it in your day-to-day life as a Data Professional? I will try to answer these questions in this multi-part series on Kubernetes.
On top of learning the theory behind K8s, we will also use it in most of the hands-on implementations of projects in this Newsletter. The first one is coming out next week where I will be covering the first piece of The SwirlAI Data Engineering Project Master Template - The Collector.
This episode of the Newsletter will cover most of what we will need for our future project deployment and that is why I wanted to roll it out first, before we go into any hands-on.
A thought to spike your excitement when it comes to the series: we will be deploying literally everything in our hands-on tutorials on Kubernetes, and to make it even more exciting - we will eventually do that with a single click. Plus, you will be able to bring all of that to any major cloud vendor seamlessly. Also, like you to be able to pass at least CKAD exam after finishing these series + doing some hands-on. As we progress with the content I will give you tips on what to keep in mind when preparing for the exams if you choose to take them.
In the first part we cover:
Why Kubernetes for Data Engineering and Machine Learning.
General Kubernetes Resources for application configuration:
Namespaces.
ConfigMaps.
Secrets.
Deploying Applications:
Pods.
Deployments.
Services.
This scratches only the surface of Kubernetes, but you will already be able to craft useful applications by just understanding how to use these concepts.
You can find the second part of the guide here:

Why Kubernetes for Data Engineering and Machine Learning.
First, let’s look into the Kubernetes system from a bird's eye view. What is Kubernetes (K8s)?
It is a container orchestrator that performs the scheduling, running and recovery of your containerised applications in a horizontally scalable and self-healing way. It is important to note that while I will mostly be using Docker icons to represent containers in the diagrams, K8s can orchestrate almost any type of container out there.
Kubernetes architecture consists of two main logical groups:
Control plane - this is where K8s system processes that are responsible for scheduling workloads defined by you and keeping the system healthy live. The control plane by itself is a big component of a Kubernetes cluster but as an application developer you will almost never be exposed to it directly. Cloud hosted Kubernetes services also manage Control Planes for you. We will look into Control Planes in detail in one of the later episodes of Kubernetes series.
Worker nodes - this is where containers are scheduled and being run. You will be mostly exposed to these nodes as an application developer. The concepts that will be relevant are: resources available on the nodes, colocation of different applications next to each other on the same node, persistent storage needed for your applications etc.
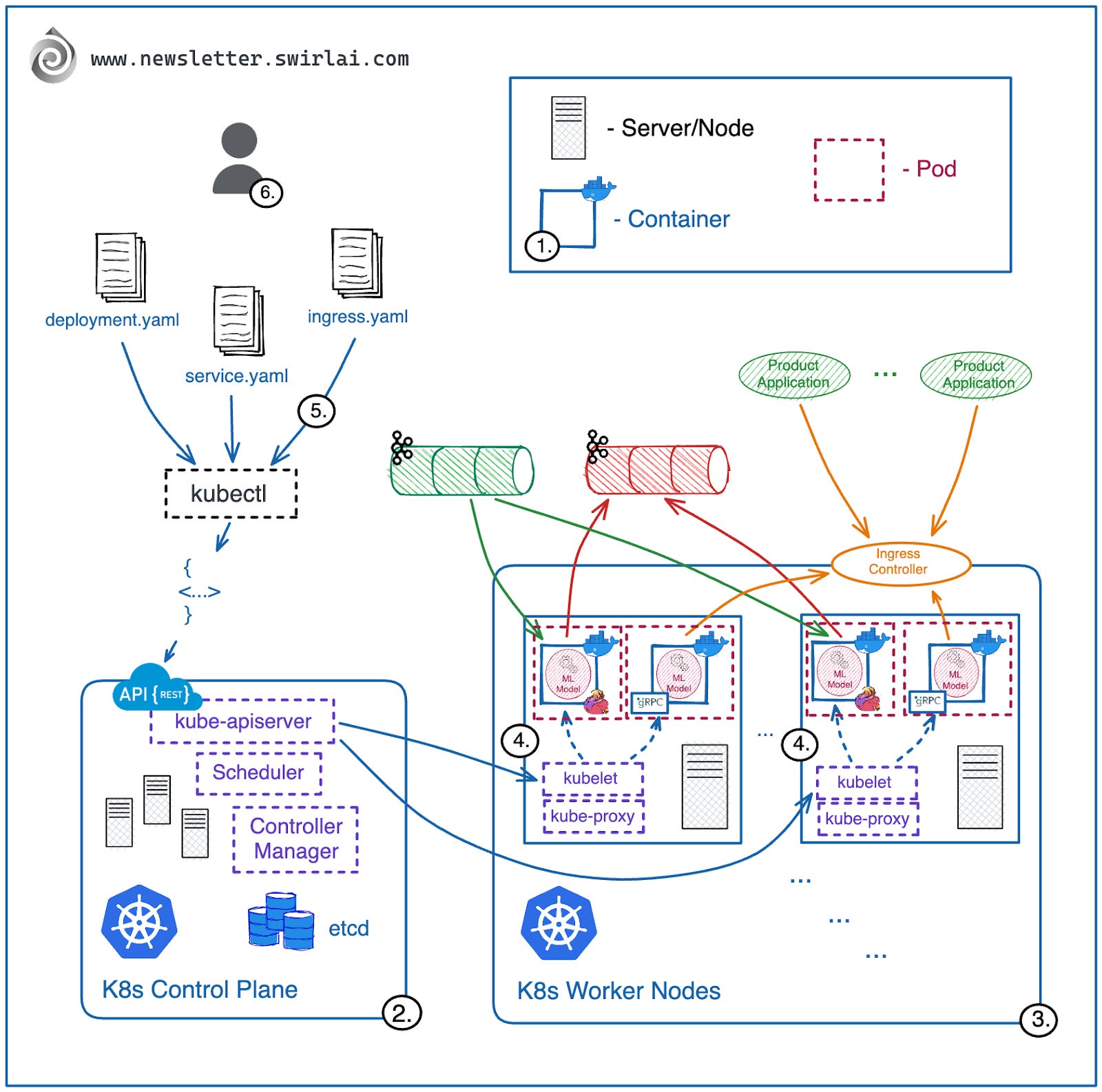
How does Kubernetes help you?
You can have thousands of Nodes (usually you only need tens of them) in your K8s cluster, each of them can host multiple pods (containers). Nodes can be added or removed from the cluster as needed. This enables unrivaled horizontal scalability.
Kubernetes provides an easy to use and understand declarative interface to deploy applications. Your application deployment definition can be described in yaml, submitted to the cluster and the system will take care that the desired state of the application is always up to date. This is extremely important as by bringing Kubernetes language to your organisation you also normalize it, by doing so you unify how your developers communicate and explain architectures.
Users are empowered to create and own their application architecture in boundaries pre-defined by Cluster Administrators. Administrators can ensure the isolation of a specific user or a team, they can define resource quotas and boundaries of where the applications deployed by a specific team can run.
So what added value can you expect out of this as a Data Engineer, ML or MLOps Engineer?
In most cases you can deploy multiple types of ML Applications into a single cluster, you don’t need to care about which server to deploy to - K8s configurations will take care of it.
You can run your models (and multiple versions of them simultaneously) as a Real Time service.
Next to Real Time services you can also deploy Streaming Applications.
You can also schedule and run applications as Batch Jobs.
Additionally, you can deploy popular ETL Orchestration Frameworks like Airflow on top of your K8s cluster and run Airflow tasks on dedicated pods with different dependencies installed on each of them.
The configuration is straightforward and easy to learn.
You can request different amounts of dedicated machine resources per application.
If your application goes down - K8s will make sure that a desired number of replicas is always alive.
You can roll out new versions of the already running application using multiple strategies - K8s will safely do it for you.
You can expose your ML Services to be used by other Product Applications with few intuitive resource definitions.
Few important notes:
Having said this, while it is a bliss to use, usually the operation of Kubernetes clusters is what is feared. It is a complex system.
Master Plane is an overhead, you need it even if you want to deploy a single small application.
Before we move to the next stage.
This tutorial assumes that you either have access to a remote Kubernetes cluster or have deployed a local one via one of the multiple ways. I also assume that you have a kubectl client installed and configured to access the K8s cluster.
I myself am using a Mac and running a local K8s cluster that is provided by Docker Desktop, you can find how to set it up on Windows and Mac here.
If you are running on Linux, the easiest way is to use a Minikube instance. More on setting it up here. Note that you can use Minikube on Mac or Windows as well.
I also assume that the reader has knowledge of Docker. I will be releasing my own tutorial series on Docker but that will come later down the road.
Note: almost anything that we will work on locally can be transferred to any K8s cluster with no changes in the configuration (this is one of the amazing aspects of working with Kubernetes).
General Kubernetes Resources.
We now know about a few benefits that K8s can bring to your day-to-day life as a Data Professional. When it comes to low level infrastructure of the cluster itself, there is little you need to know as it is usually taken care of by Server Administrators. What you need to know and understand are the virtual Kubernetes resources that allow you to compose your application. A K8s resource is what you define and submit to the K8s API. The definition is then parsed and the cluster makes sure that what you defined is what is always the state of the cluster and applications in it.
Let’s start with the very simplest of the resources - a Namespace.
Namespaces
A Namespace in Kubernetes is just a logical grouping of other resources that you will be creating in the cluster. You usually create a resource in a Namespace, there are only a few Global Resource types that are created globally and not tied to a specific Namespace.
Kubernetes clusters start off with several Namespaces precreated by default and you will be creating or assigned newly created Namespaces to which you would be deploying your application resources. Namespaces are important because they allow you and the administrators to:
Isolate permission boundaries in a single Namespace. Namespaces are usually used as a layer of Role Based Access Control isolation. You can have different permission sets of what users are allowed to do per Namespace and which users are even allowed into a Namespace.
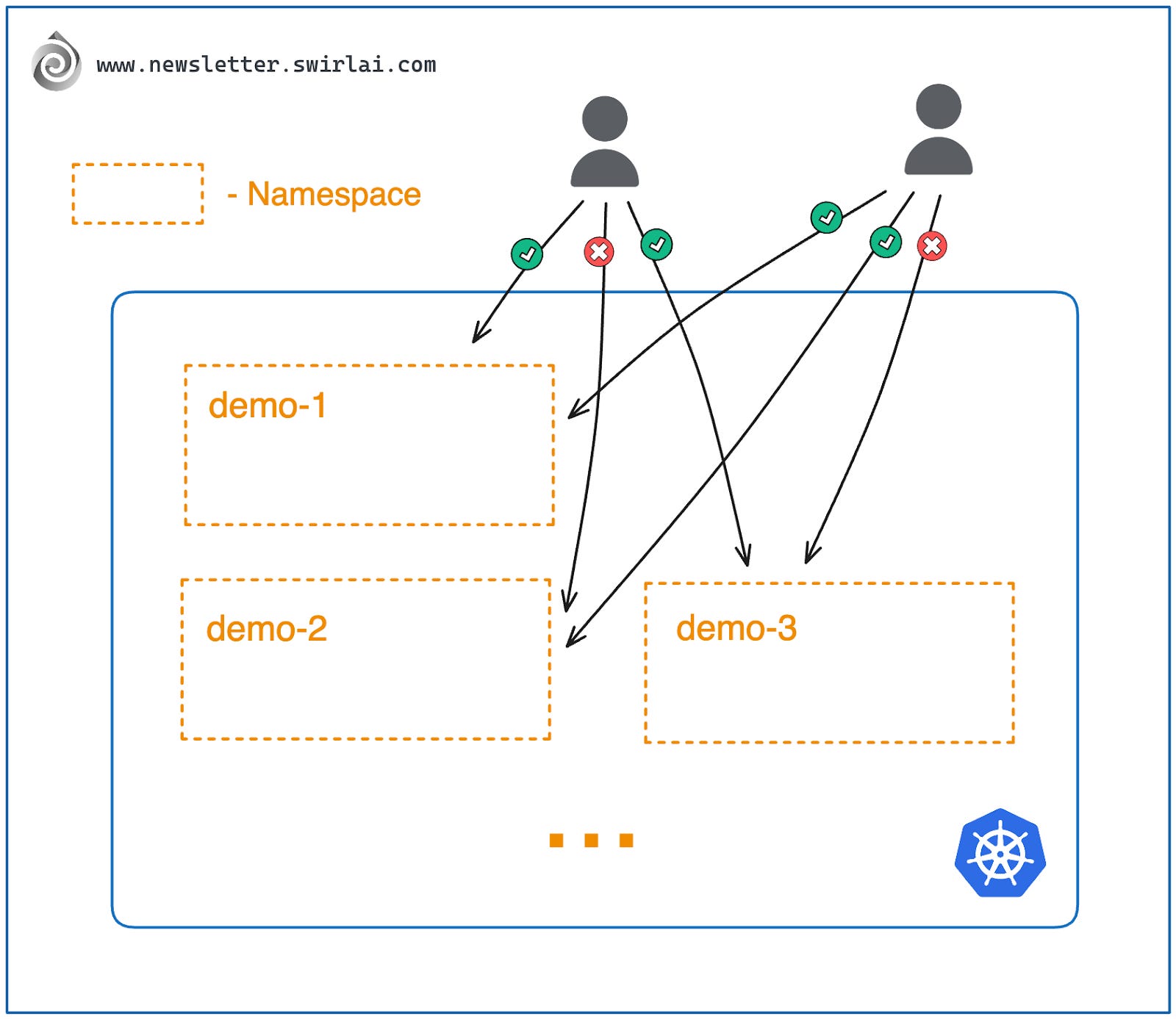
Isolate applications in Namespaces. Namespaces have their own space of unique resource names. If you are creating an application named swirl-ai-app in the namespace demo, you will also be able to create an application named swirl-ai-app in a different namespace e.g. demo-2. This behavior allows you to more easily normalize naming of applications between Namespaces as you do not need to think about naming conventions to keep uniqueness.

Create unique sets of Variables and Secrets per Namespace. Only by being allowed to use this Namespace and variables will you be allowed access to use them inside of your applications. This allows for easier management of not only K8s internal resource access but external credentials as well.

You can create a namespace named swirlai by saving the following into a file named namespace.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: swirlaiThen by executing the following command:
kubectl apply -f namespace.yamlInspect the successful result by running:
kubectl get namespacesYou should see something similar to this:

ConfigMaps
I already mentioned configmaps while describing namespaces. Given the name, it is no surprise that configmaps are one of the ways of storing configuration in Kubernetes that can later on be used by applications deployed in the same Namespace where the configmap was created. There are mainly two ways of how a configmap is used in K8s.
Storing Key-Value pairs of configuration and ingesting it into an application at runtime. Usually it is done by setting application runtime environmental variables.
Storing contents of a file as a string of the configmap value and mounting it as a file for an application to read at runtime. This is extremely useful if e.g. you are running a framework like Airflow on kubernetes, by utilizing configmaps you are able to mount the entire airflow.cfg to be used by Airflow while defining it on Kubernetes configuration level.
The use cases for configmaps are countless but one of the most clear examples I can think of is configuring different environments of your application.
Let’s say you have three namespaces: dev, staging and prod. The names speak for themselves.
You are developing an application that needs to move between these 3 environments before deployment.
You want to make as little hardcoded changes for different environments in application code as possible so you parametrize the behavior. E.g. databases the application connects to, throttling configuration etc.
You inject the parameters via configmaps - since the application code is parameterized, you are able to deploy the same codebase without any changes to the different namespaces, the only changes needed are in K8s per namespace parameters.
You can create a configmap named config in swirlai namespace by saving the following into a file named configmap.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: config
namespace: swirlai
data:
environment: dev # key-value
db-host: localhost # key-value
airflow.cfg: | # key-value, config as a file content
[core]
# The folder where your airflow pipelines live, most likely a
# subfolder in a code repository. This path must be absolute.
dags_folder = /usr/local/airflow/dags
# The folder where airflow should store its log files
# This path must be absolute
base_log_folder = /usr/local/airflow/logs
...Then by executing the following command:
kubectl apply -f configmap.yaml
Inspect the successful result by running:
kubectl get configmaps -n swirlaiYou should see something similar to this:

Secrets
Secrets is yet another mechanism in K8s to share configuration, this time - sensitive configuration like passwords or other credentials. It is important to note, that Secrets are not as secret as they might seem, the data stored in a secret is simply base64 encoded, so if you are allowed to retrieve it from Kubernetes Servers you will be able to decode it without much problems. A modern and more secure way of allowing application access to secured information is storing these secrets in one of the available third party secret vaults and injecting these secrets directly from there at application runtime.
Having said this, if you do not have a vault connected to your cluster, you will still need to manage your secrets somehow so let’s look into creating vanilla secrets in K8s. If you will be using them, be sure to restrict access so that only authorized personnel could view and retrieve them.
First, we need a base64 encoded string that we want to secure. Let’s say we want to secure super-secret, base64 representation of the string is c3VwZXItc2VjcmV0, you can get it by running the following on Mac:
echo -n 'super-secret' | base64You can create a secret named secret holding required information under key secret-data in swirlai namespace by saving the following into a file named secret.yaml:
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: swirlai
data:
secret-data: c3VwZXItc2VjcmV0Then by executing the following command:
kubectl apply -f secret.yaml
Inspect the successful result by running:
kubectl get secrets -n swirlaiYou should see something similar to this:

Deploying Applications
We now know how to create Namespaces and create configuration resources in it. Let the fun part begin by understanding how to actually deploy an application to a Kubernetes cluster. Similarly like with ConfigMaps and Secrets we will be deploying applications to a given namespace.
Pods
As defined in the beginning of the article - K8s is a container orchestrator. The system deploys applications that are already containerised and it manages the lifecycle of these applications according to the rules you define by creating Kubernetes Resources. The smallest unit of resource that you can define in K8s is not a container but a Pod.
A pod is a Kubernetes resource that encapsulates one or multiple containers and allows for their runtime configuration in a single context with shared network and storage space. Once the configuration of a pod is applied - Kubernetes cluster starts the requested containers and keeps them running.
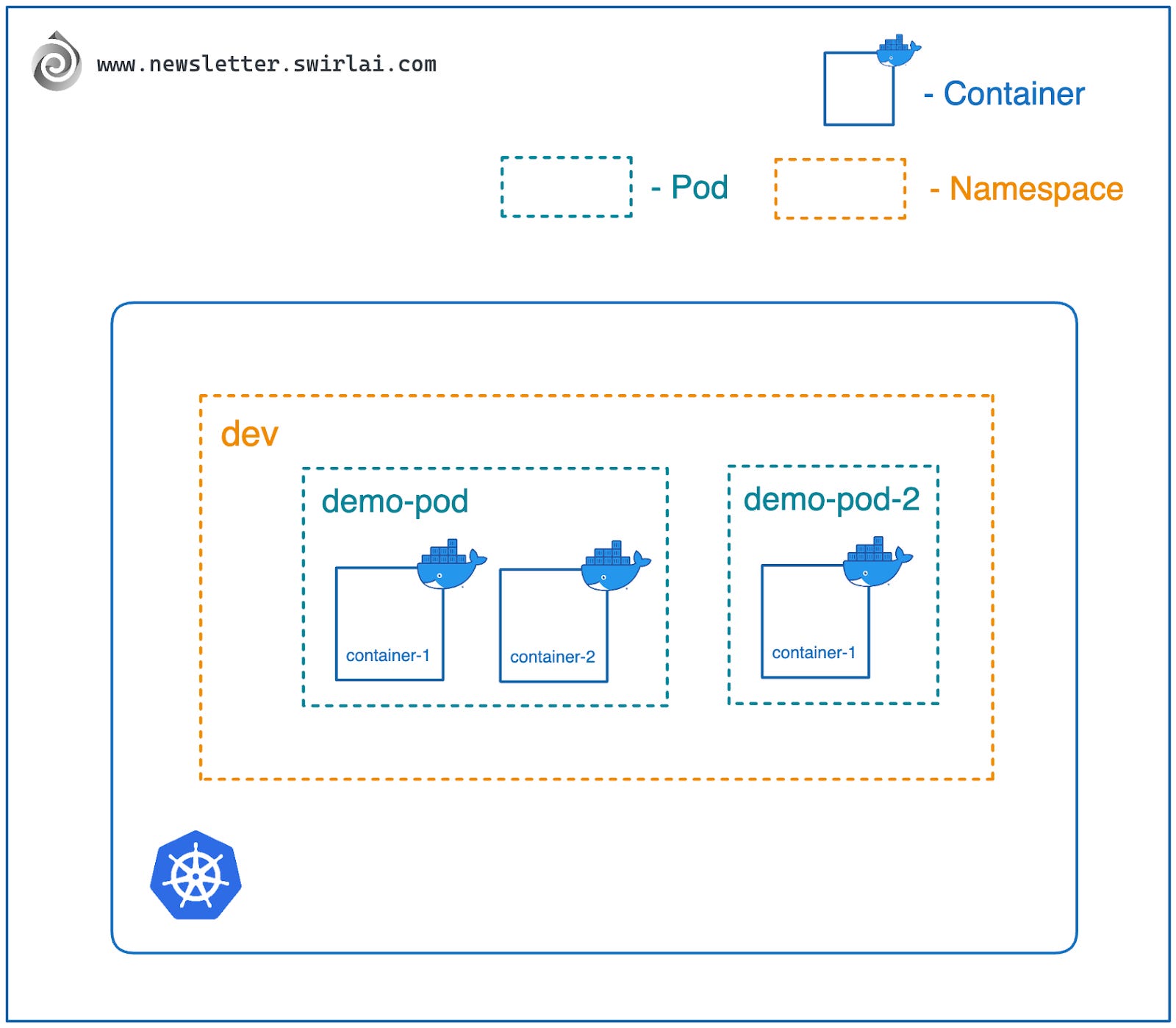
Take note that all resources in Kubernetes are named.
Let’s create a pod named swirlai-pod in the namespace swirlai that deploys and runs nginx container with the tag latest from Docker Hub, uses previously defined ConfigMap and Secret and exposes them as environmental variables in the container names swirlai-container inside of the pod. Create a file named pod.yaml with the following content:
apiVersion: v1
kind: Pod
metadata:
name: swirlai-pod
namespace: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80
env:
- name: DIRECT
value: Some String
- name: ENVIRONMENT
valueFrom:
configMapKeyRef:
name: config
key: environment
- name: SECRET_DATA
valueFrom:
secretKeyRef:
name: secret
key: secret-dataThen by executing the following command:
kubectl apply -f pod.yamlInspect the successful result by running:
kubectl get pods -n swirlai
You should see something similar to this:

Note the “Ready: 1/1” column, it shows how many containers are ready in the pod (we will be delving into what ready means in future episodes of Kubernetes related series). If you look closely at the Pod resource definition file, containers field is a list, we only defined one container but there could be multiple.
Deployments
Pods are almost never used by themselves. This is due to the fact that it would be hard to scale Pods almost in the same way as raw containers - you would need to define multiple Pods and make sure that they are always running. That is why K8s provides multiple special workload resources that take care of deploying and scaling sets of pods for you, you simply need to define the rules of how to do that. Deployment is one of the mentioned workload resources and is the most used one in the group because it is a natural way to scale microservice applications. Today we look only at Deployment and will cover other ways to manage workloads in future episodes of Kubernetes series.
So what is a deployment?
Deployment is a way to manage a set of multiple identical replicas of a Pod. We want this because in the world of microservices and horizontal scaling we usually do not need any statefulness for the application that is performing work and can simply scale the application by multiplying it in quantity and facing the deployed group with a Load Balancer or increasing the number of consumers in a consumer group in the case of a Streaming Application.

What is a good example of when we would use a Deployment in the data world?
Deployment is a natural choice of scaling Real Time Machine Learning APIs. Usually the applications are stateless, meaning that there is simply a ML model loaded into memory and applying inference results on demand, all of the data needed for inference is living outside of application context in e.g. a Feature Store or coming in together with the request.
What else does a Deployment Provide?
You define a number of Pod replicas you want to have running in the K8s cluster, deployment makes sure that this amount of Pod is always running.
Deployment makes sure that each of the pods gets a unique name assigned. The names will always start with the deployment name appended with “-<random value>”.
Deployments manage releases of new versions of your Pods, once you change the definition of a pod - the Deployment makes sure that a new version is released gracefully according to the rules you defined (more on this in the future Kubernetes related episodes).
Deployments enable you to gracefully roll back to previous versions of deployed applications.
This is usually not seen by developers in their day-to-day but deployments manage sets of pods by creating ReplicaSets under the hood that are actually defining the desired state of the Pods. For now let’s not think about this too much since you will almost never run into a need to look into ReplicaSets unless you run into issues that need to be debugged.
Let’s create a Deployment named swirlai-deployment that manages 3 replicas of the Pod that we defined previously and named swirlai-pod. Create a file named deployment.yaml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: swirlai-deployment
namespace: swirlai
spec:
replicas: 3
selector:
matchLabels:
app: swirlai
template:
metadata:
labels:
app: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80
env:
- name: DEFINED_DIRECTLY
value: Some String
- name: ENVIRONMENT
valueFrom:
configMapKeyRef:
name: config
key: environment
- name: SECRET_DATA
valueFrom:
secretKeyRef:
name: secret
key: secret-dataThe following is how you can reason about the contents of this file:
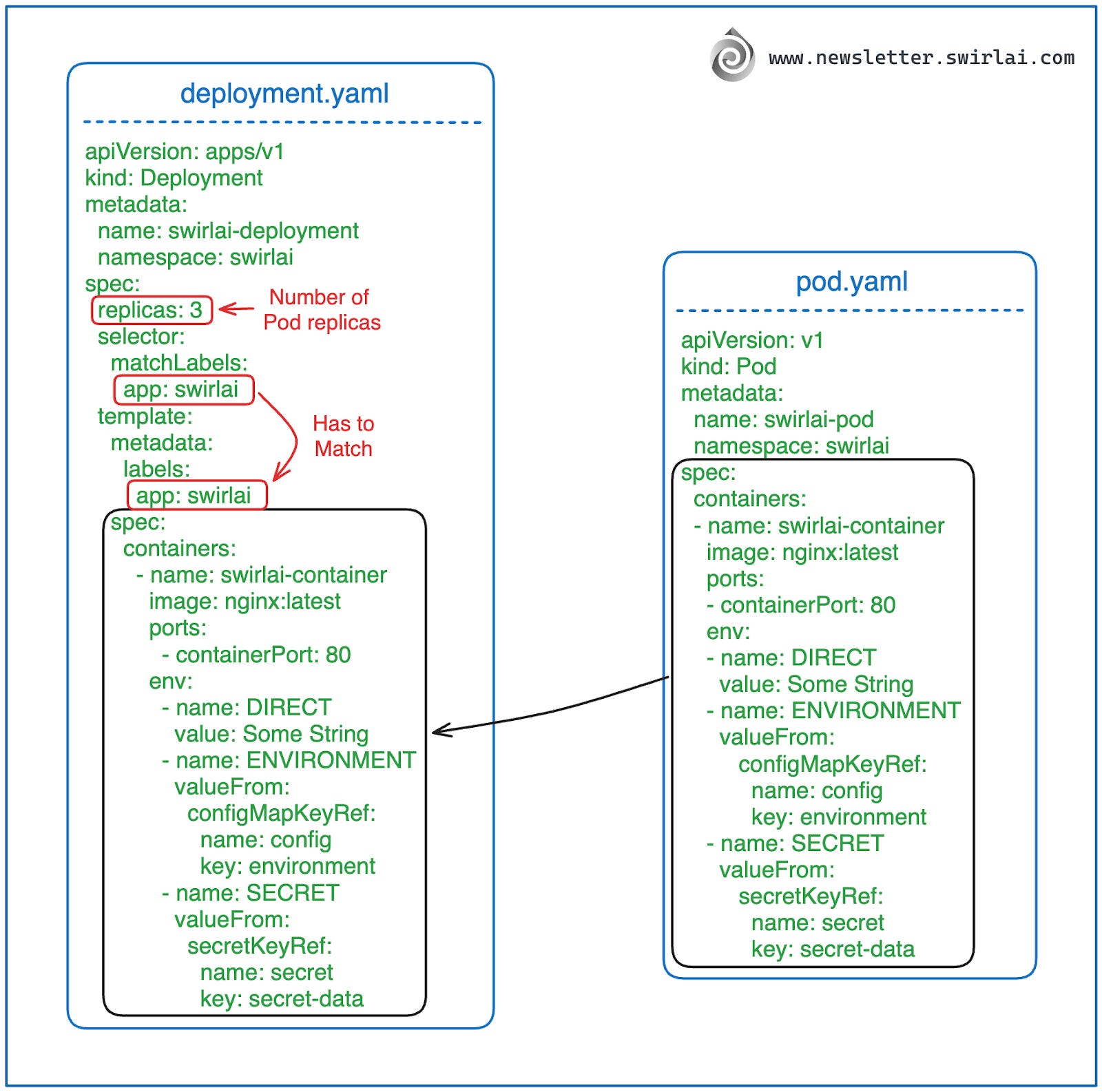
Create the Deployment by executing the following command:
kubectl apply -f deployment.yaml
Inspect the successful result by running:
kubectl get deployments -n swirlaiYou should see something similar to this:

You can also inspect the Pods that have been created by the Deployment by running:
kubectl get pods -n swirlaiYou should see something similar to this:

Services
Sometimes Deployments can live and serve the use case by themselves - this is usually a case for Streaming Applications. More commonly though Deployments are used to deploy a Real Time service of some sort, e.g. a Real Time ML Service. This is when other applications need to access these services via e.g. a REST API. In order to allow this access to the entire fleet of applications managed by a Deployment and to balance the traffic between them you would face the fleet of applications with a Load Balancer. In Kubernetes the role of a simple, internal to Kubernetes Load Balancer is performed by a Service resource.
Services are defined to be mounted on top of a group of pods sharing the same label set so be careful to not duplicate the same sets of labels for multiple deployments running in the same Namespace.
Let’s create a Service named swirlai-service in the swirlai namespace that will be balancing the traffic between the pods managed by the previously created deployment that we named swirlai-deployment. Create a file named service.yaml with the following content:
apiVersion: v1
kind: Service
metadata:
name: swirlai-service
namespace: swirlai
spec:
selector:
app: swirlai
ports:
- protocol: TCP
port: 80
targetPort: 80The following is how you can reason about the contents of this file:
Create the Service by executing the following command:
kubectl apply -f service.yaml
Inspect the successful result by running:
kubectl get services -n swirlaiYou should see something similar to this:

Note: this only creates a service that is accessible from inside of the Kubernetes cluster and is mostly useful for communication with other services deployed in the cluster. If you would want to ping it directly, you could create a jump pod inside of the cluster, ssh into it and use cli from there. You can also expose a Service outside of the cluster but ore on this in the future episodes in Kubernetes focused series.
Closing thoughts.
That’s it for this time. By knowing how to work with Kubernetes resources defined in the article we will be able to implement most of the application architectures in the hands-on series of SwirlAI projects. Next week we will do exactly this for the Collector element of the SwirlAI Data Engineering Project Master Template. Hope to see you there!
Hey Aurimas, in the last part where we are defining a service for load balancing function to be mounted on top of POD, so this needs to be defined in a service.yaml file, we have already defined a service.yaml file for namespace creation, does this mean we will have 2 service.yaml files?
Hi Aurimas, that for the write up it was very informative, can you also write an article about timeseries databases and when they are really needed as opposed to the traditional RDB? For example Postgres engine offers an extension for TS but I’m not quite sure about that would be a solution for actual TS db? Thanks