
Agent Skills: Progressive Disclosure as a System Design Pattern
A simple file format, powered by an architectural shift in how agents manage context.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in AI Engineering, Data Engineering, Machine Learning and overall Data space.
Everyone is talking about Agent Skills. On December 18, 2025, Anthropic released them as an open standard. Within weeks, OpenAI, Google, GitHub, and Cursor adopted it. Less than three months later, marketplaces like SkillsMP index over 400,000 skills across platforms.
If you look at a skill file, it’s very simple - a markdown file with some YAML at the top. That’s it.
So why did every major AI platform rush to support it?
The skill file is simple on purpose. It structures information into layers so that platforms like Claude Code, Codex CLI, and Gemini CLI can load context progressively: name and description first, full instructions when relevant, supporting materials only during execution. The file is the contract. The platform implements the interface. The design pattern driving both is progressive disclosure.
Let’s unpack how this works.
What Are Agent Skills?
Before we get to why they matter, let’s look at what they actually are.
An Agent Skill is a directory containing a SKILL.md file. That file has two parts: YAML frontmatter (metadata) and Markdown body (instructions).
Here’s a real example from Anthropic’s official skills repository. This is the pdf skill:
pdf/
├── SKILL.md
├── reference.md
├── forms.md
└── scripts/
├── check_bounding_boxes.py
├── check_fillable_fields.py
├── convert_pdf_to_images.py
├── create_validation_image.py
├── extract_form_field_info.py
├── extract_form_structure.py
├── fill_fillable_fields.py
└── fill_pdf_form_with_annotations.py
And the contents of SKILL.md file:
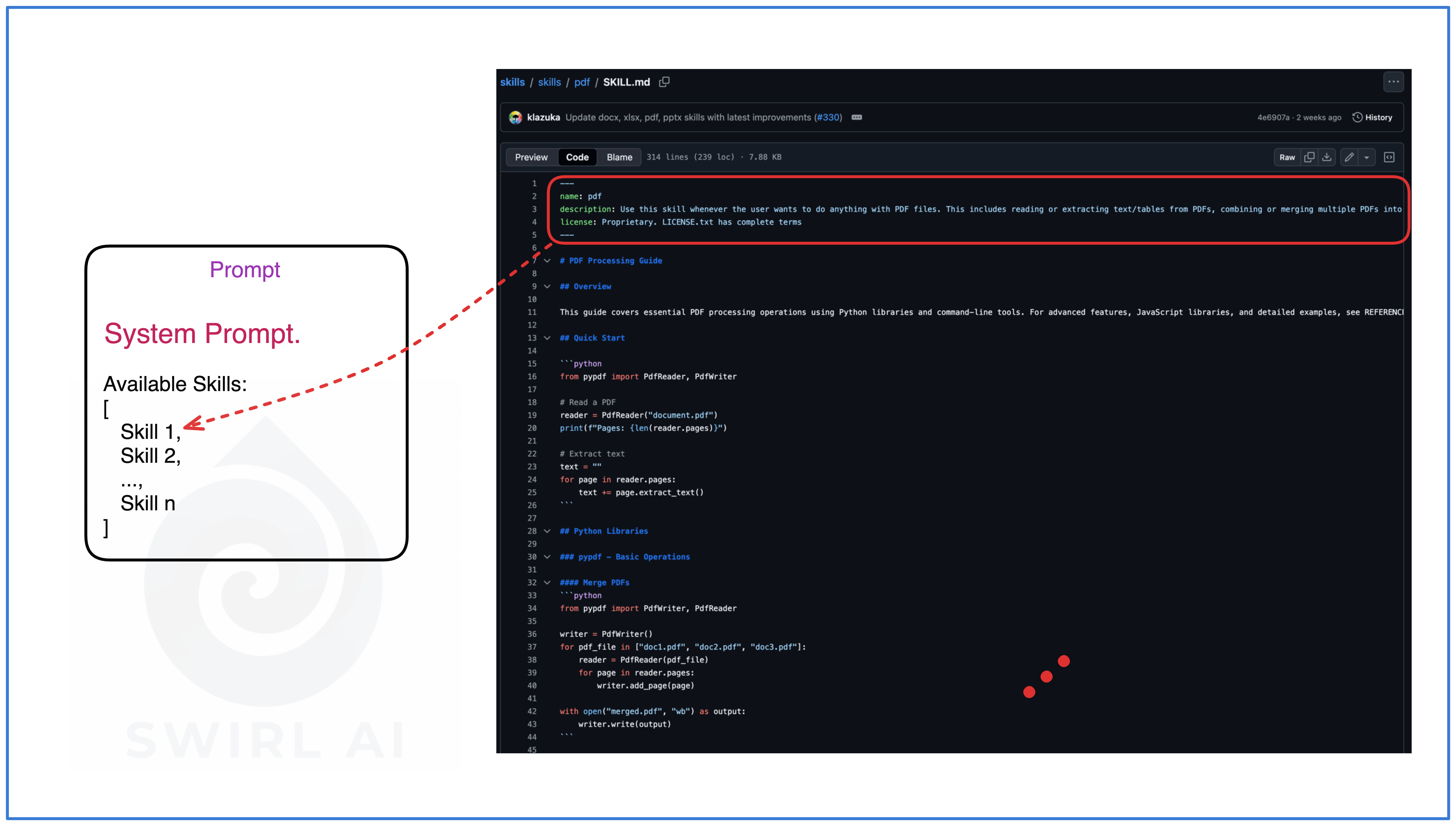
---
name: pdf
description: Use this skill whenever the user wants to do anything with PDF files. This includes reading or extracting text/tables from PDFs, combining or merging multiple PDFs into one, splitting PDFs apart, rotating pages, adding watermarks, creating new PDFs, filling PDF forms, encrypting/decrypting PDFs, extracting images, and OCR on scanned PDFs to make them searchable. If the user mentions a .pdf file or asks to produce one, use this skill.
license: Proprietary. LICENSE.txt has complete terms
---
# PDF Processing Guide
## Overview
This guide covers essential PDF processing operations using Python libraries and command-line tools. For advanced features, JavaScript libraries, and detailed examples, see REFERENCE.md. If you need to fill out a PDF form, read FORMS.md and follow its instructions.
## Quick Start
...
Notice the directory structure. The SKILL.md file contains the skill’s metadata and instructions. The reference docs (reference.md, forms.md) provide supporting documentation. The scripts/ folder holds 8 Python utilities the agent can call during execution.
Skills live in predictable locations. On Claude Code, that’s ~/.claude/skills/ for personal skills or .claude/skills/ inside a project. Codex CLI uses .agents/skills/. Gemini CLI uses .gemini/skills/. The paths differ, but the format is identical across all of them.
The key distinction from system prompts or custom instructions: skills are modular and selectively loaded. A system prompt is always on. A skill sits dormant until the platform decides it’s relevant to the current task. The file organizes information into layers. The platform decides when to load each layer.
The Problem: Context Windows Are Not Free
Best practice recommends fewer than 20 tools available to an agent at once, with accuracy degrading past 10. The same principle applies to instructions. An agent handling customer support, billing, refunds, and onboarding doesn’t need all four workflow guides loaded when the user asks about a refund. Connect a few MCP servers without managing what loads, and you quickly reach 90+ tool definitions, over 50,000 tokens of JSON schemas before the model even starts reasoning. Layer in system prompts, workflow instructions, conversation history, and retrieved documents on top.
As context grows, the model's attention degrades and important information gets buried. Models reliably miss information placed in the middle of long contexts, a well-documented phenomenon called "lost-in-the-middle." The more irrelevant context surrounds the relevant pieces, the worse retrieval accuracy gets.
Join the March Cohort of my End-to-End AI Engineering Bootcamp to learn how to solve the challenges of Context Engineering for production systems in the real world. (Use code KICKOFF15 at the checkout for 15% discount).
Progressive Disclosure and the Three-Tier Architecture
Progressive disclosure is a well-established design pattern, formalized by the Nielsen Norman Group for user interface design. The principle: show only what is needed for the immediate task and defer everything else. Advanced options live behind a click, rarely-used features hide in secondary menus. This reduces cognitive load, lowers error rates, and makes systems usable by a wider audience.
This is part of a broader trend: design patterns built for human cognition transfer well to agents. Agent memory systems already mirror human memory, separating short-term working memory from long-term storage. Progressive disclosure follows the same logic. The context window is the agent’s cognitive space. Overloading it degrades performance, while keeping it focused lets the agent reason sharply. Agent Skills apply this principle to how agents access knowledge.
I have written more about context engineering and memory management problems here:

The SKILL.md file organizes information into three layers. The platform implements the loading logic, deciding when to promote from one layer to the next.
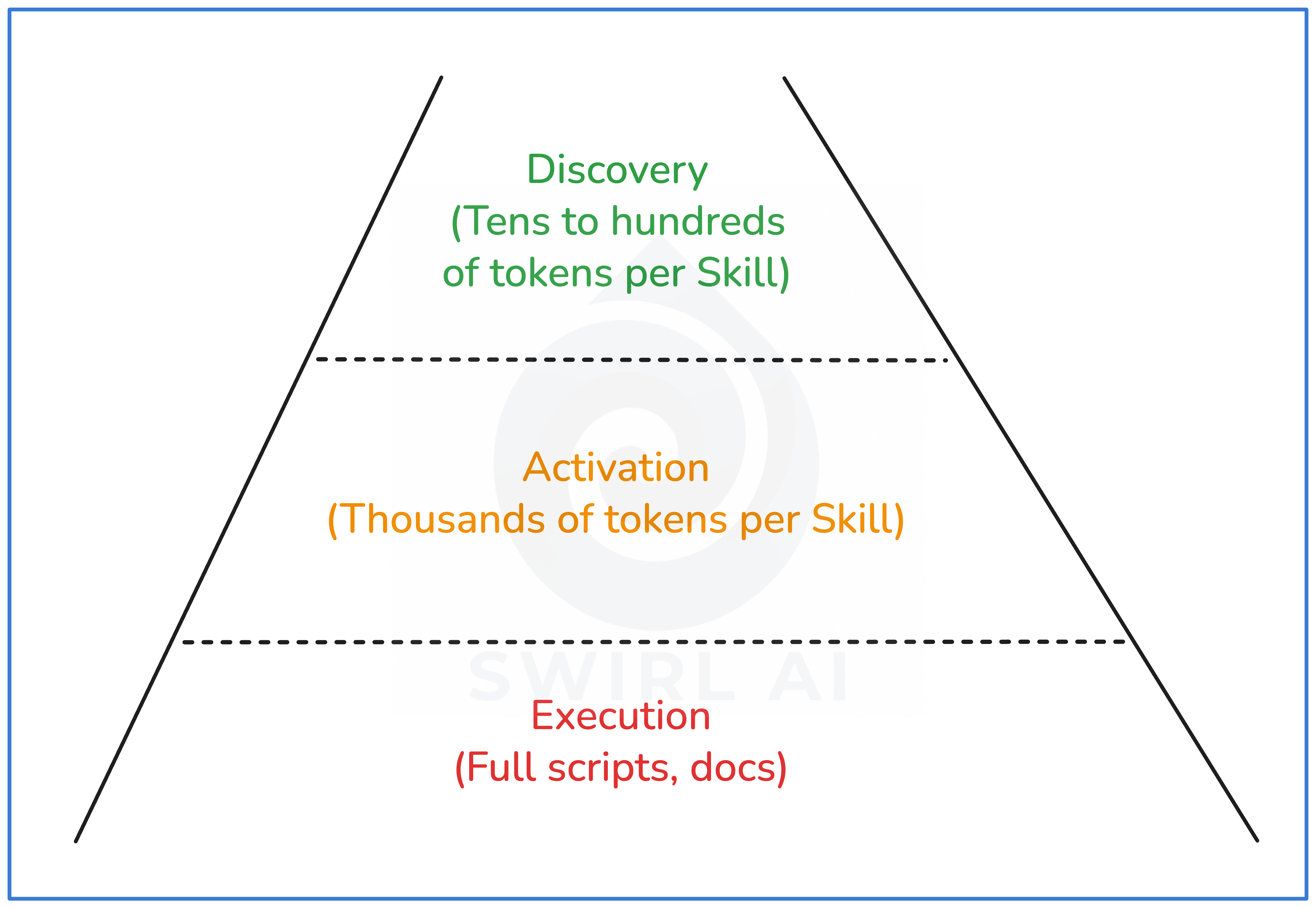
Layer 1: Discovery
At startup, the platform reads only the skill's name and one-line description from the YAML frontmatter. I measured this across Anthropic's 17 official skills: the median discovery cost is ~80 tokens per skill, ranging from ~55 (webapp-testing) to ~235 (xlsx). All 17 skills together cost ~1,700 tokens, meaning an agent can be aware of dozens of skills for less context than a single activated skill.
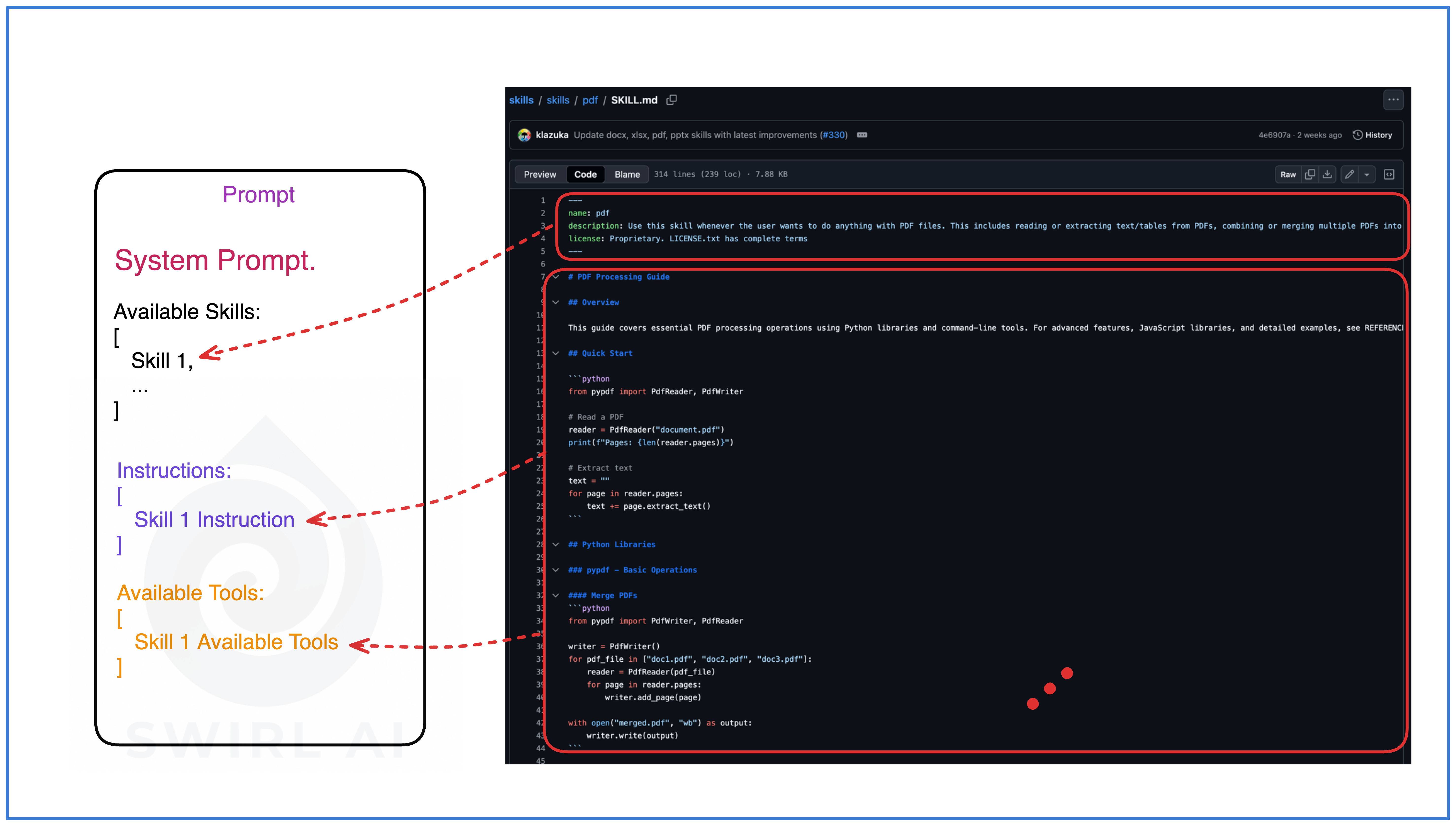
Layer 2: Activation
When the platform determines a skill is relevant to the current task, it loads the full SKILL.md markdown body into context. I counted tokens across all 17 skills in Anthropic’s official repository: body size ranges from ~275 tokens (internal-comms) to ~8,000 tokens (skill-creator), with a median around 2,000.
The platform makes this decision using LLM reasoning over the descriptions from the discovery layer. Research shows that Claude selects skills through pure reasoning, with description quality directly determining routing accuracy.
Layer 3: Execution
During execution, the platform pulls in supporting materials on demand: scripts, reference documentation, templates, configuration files. These only enter context when the agent reaches a step that requires them.
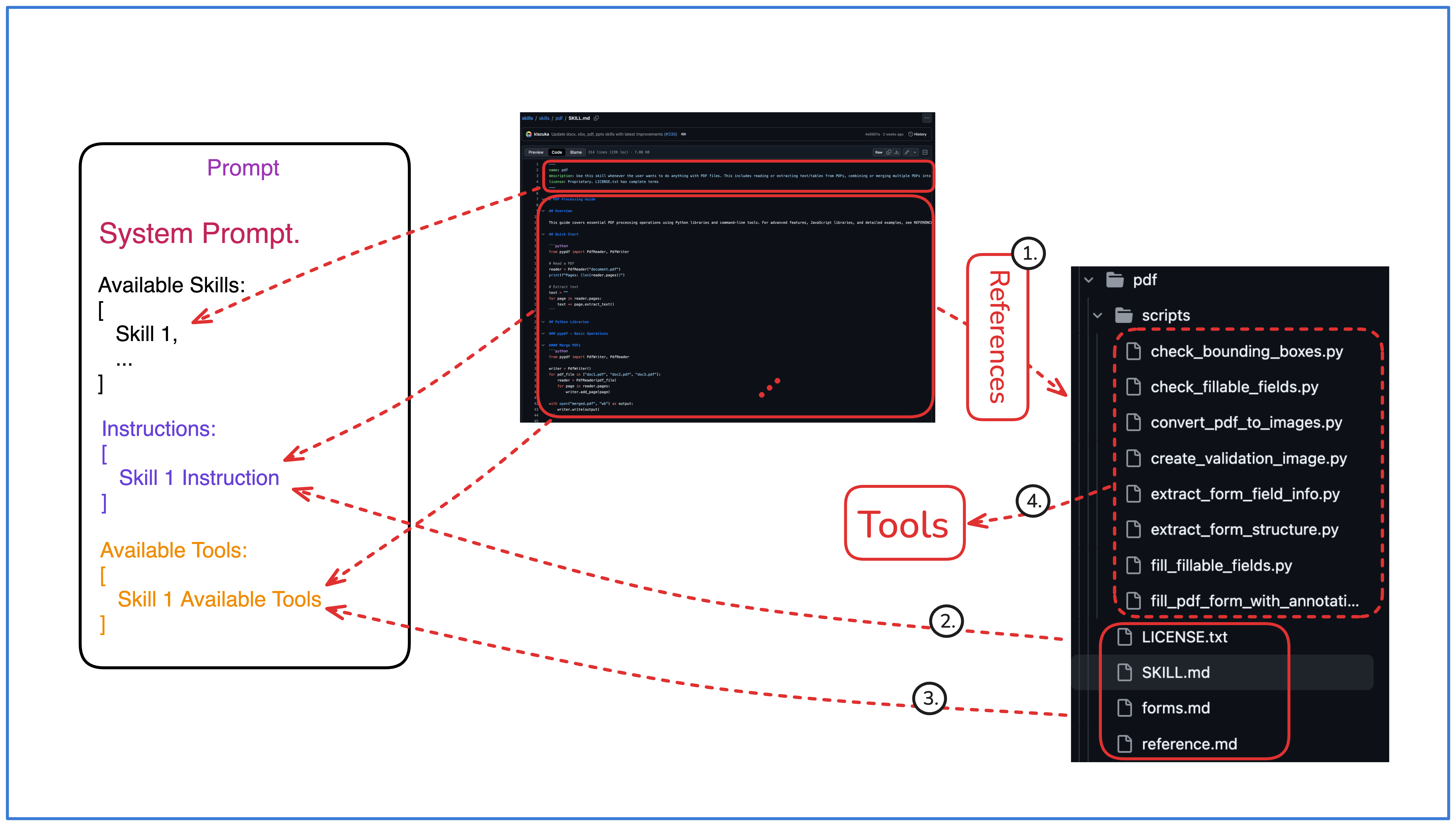
Here’s how this works in practice, using Anthropic’s PDF skill as an example.
The
SKILL.mdbody contains pointers to execution-layer files:
## Next Steps
- For advanced pypdfium2 usage, see REFERENCE.md
- For JavaScript libraries (pdf-lib), see REFERENCE.md
- If you need to fill out a PDF form, follow the instructions in FORMS.md
- For troubleshooting guides, see REFERENCE.md
When the agent hits a step that needs this context, it pulls in the referenced file. The content it finds falls into three categories:
Domain knowledge.
REFERENCE.mdcontains technical context the agent needs to make informed decisions:
### Overview
pypdfium2 is a Python binding for PDFium (Chromium's PDF library).
It's excellent for fast PDF rendering, image generation,
and serves as a PyMuPDF replacement.
Executable scripts. The same file also includes code the agent can run directly:
import pypdfium2 as pdfium
from PIL import Image
pdf = pdfium.PdfDocument("document.pdf")
page = pdf[0]
bitmap = page.render(scale=2.0, rotation=0)
img = bitmap.to_pil()
img.save("page_1.png", "PNG")
Tool pointers. Some files reference standalone scripts as tools. From
FORMS.md:
If you need to fill out a PDF form, first check to see if the PDF
has fillable form fields. Run this script from this file's directory:
`python scripts/check_fillable_fields <file.pdf>`, and depending on
the result go to either the "Fillable fields" or "Non-fillable fields"
and follow those instructions.Each layer adds context, and none of it loads until it's needed. The unloading side matters too. A naive implementation would discard a skill's context entirely after use, only to reload it minutes later when the next related task arrives. Smarter implementations cache recently used skills or keep frequently activated skills warm, balancing context efficiency with the cost of repeated loading.
This Is Not Just About Coding Agents
Most Agent Skills adoption today is in developer tools like Claude Code, Codex CLI, Cursor, and Gemini CLI. The pattern generalizes well beyond that.
OpenClaw is the clearest example. It’s an open-source autonomous agent that passed 175K GitHub stars in under two weeks, and while it can code, its adoption is driven by non-coding use cases: managing calendars, drafting emails, controlling smart home devices, meal planning in Notion, coordinating across WhatsApp and Telegram. Its community registry, ClawHub, hosts over 13,000 skills, most of them non-technical.
The three-tier pattern works anywhere you need broad capability with focused execution. Customer support agents that know about 200 product features but only discuss 2 per conversation. Internal operations agents managing dozens of workflows. Research agents navigating large knowledge bases. Progressive disclosure is a system design pattern.
This is where the responsibility falls on us as AI Engineers. Coding agent platforms like Claude Code and Cursor already implement the progressive disclosure interface. When we build non-coding agents, customer support bots, internal operations tools, domain-specific assistants, we need to build that same interface ourselves. The SKILL.md contract gives us the structure. Implementing the loading logic, the discovery-to-activation-to-execution pipeline, that’s our job.
Agent Behavior, Accessible to Non-Technical People
ChatGPT made conversing with AI accessible to everyone. Skills do the same for configuring how agents behave. A skill file is markdown with plain English instructions. A product manager can open one and understand what it does. A domain expert can edit one. A non-technical team lead can create one from scratch, or ask an AI to generate it using a skill-creator skill. Both Anthropic and Google ship built-in skill-creators that generate skill files from natural language descriptions.
On Claude.ai, non-developers can enable pre-built skills in settings, upload custom skill packages as ZIP files, and let Claude select relevant skills automatically. Configuring agent behavior used to require prompt engineering expertise or developer access. Now the people closest to the problem, domain experts, team leads, operators, can directly shape how agents behave.
Skill marketplaces like SkillsMP are already forming with a distribution model similar to browser extensions: discover, install, configure.
The Ecosystem Moved Fast for a Reason
Anthropic released the Agent Skills open standard on December 18, 2025.
Within weeks:
OpenAI adopted it for Codex CLI and ChatGPT.
Google added skills to Gemini CLI.
GitHub Copilot launched skills support the same day as the standard.
Cursor integrated skills alongside their existing Rules system.
This speed tells you something. Every one of these platforms faces the same two problems: how to give agents broad knowledge without destroying context quality, and how to let users configure agent behavior without requiring engineering expertise. The skills format solves both. Progressive disclosure keeps context lean, and the markdown-based contract makes skills accessible to anyone who can write plain English.
Wrapping Up
Agent Skills are the first mainstream implementation of progressive disclosure applied to agent context management. The pattern is simple: give agents a lightweight index of capabilities, pull in details when needed, and keep context lean.
Context efficiency is only half the value. Skills also make agent behavior configurable by anyone who can write plain English, the same way ChatGPT made conversing with AI accessible to everyone.
Coding agent platforms already implement the progressive disclosure interface. When we build non-coding agents, the responsibility falls on us as AI Engineers to implement the same three-tier loading pattern, with smart caching to avoid naive context churn.
The SKILL.md file defines the contract. The platforms implement the interface. Progressive disclosure as a system design principle is what ties them together. This pattern will outlast the specific file format and show up wherever agents need to choose from many options without drowning in information.