
Evaluation Driven Development for Agentic Systems.
My step-by-step approach for building and evolving Agentic Systems that work.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in GenAI, MLOps, Data Engineering, Machine Learning and overall Data space.
SwirlAI Newsletter is a reader-supported publication. To receive new posts and support my work, consider becoming a subscriber.
I have been developing Agentic Systems for around two years now. The same patterns keep emerging again and again, regardless of what kind of systems are being built.
I have learned them the hard way and many do so as well. The first project is not a great success, but you learn from the failures and apply the learnings in the next one. Then you iterate.
Today, I am sharing my system of how to approach development of LLM based applications from idea to production. Use it if you want to avoid painful lessons in your own projects.
In the Newsletter episode I will cover:
The Evaluation driven application development system.
Moving from Prototype to PoC to MVP.
Evolving your Agentic Systems.
Role of LLMOps in development of AI Agents.
Before we move forward, I wanted to give a shoutout to MLOps Community and my friend Demetrios for organising amazing events that help move the AI industry forward. A free event that will be happening in San Francisco and I am looking forward - AI Agent Builders Summit: World Tour Kickoff.
The event brings together builders, researchers, and doers working on AI Agents in Production in the most lo-fi way possible. Only engineers. No marketers. A great line-up including Anthropic, Boundary ML, Cleric and more.

Highly encourage to register if you are in San Francisco on May 28th.
AI Product Development Lifecycle.
Below is a high level diagram that represents the development lifecycle of a modern AI Product.
The goal of today is to go step by step and highlight the key considerations you should have in mind if you choose to implement the same path in your projects.

Let’s start!
Defining The Problem.
The first step of any Agentic System development is defining the problem you want to solve. Agentic System is one where Large Language Models or other GenAI models are used to solve complex, real-world problems, in many cases dealing with automation.

It's vital to ensure the problem is clearly defined, bounded and aligned with business goals. Some questions to consider:
Is the problem best solved by AI or traditional software?
Who is the end user?
What are the edge cases?
What are the boundaries of acceptable behaviour?
Roles to involve: AI Product Managers, Domain Experts, AI Engineers.
Important: Many AI projects fail not due to bad models, but due to solving the wrong problem.
Building a Prototype.
After you know the problem is a good fit to be solved using AI, start rapid prototyping. In different size organisations this stage can be handled by different people. I am a strong believer of full-stack AI Engineering where AI Engineers prototype and communicate with stakeholders directly, but in large enterprises this is also where AI Product Managers can have a big impact.

Some points to consider:
Use Notebooks or no-code tools, small datasets and off-the-shelf models.
This is where you learn rather than focus on performance.
Document everything so that you don’t repeat the mistakes in the future.
This is where you will do a lot of prompting and researching market for tools that could potentially help in solving the problem (e.g. Voice to Text platforms).
Roles to involve: AI Product Managers, AI Engineers.
Important: This phase can be treated as a de-risking practice. While your idea might look good on the paper, it might not be technically feasible long term.
Defining Performance Metrics.
You are never just building a cool application, you are solving a real business problem that needs to be grounded in specific metrics you are planning to optimise.

Key points to consider:
What is that you are trying to optimise for? E.g. reduce headcount, improve user satisfaction, increase development velocity.
The above is your north star output metric, now you need to split it into input metrics that can actually drive the output metric forward. E.g. reduce an average time to Customer Support ticket resolution.
Your application should be targeting the input metrics, but the output metric will be what really matters for the business.
Roles to involve: AI Product Managers, AI Engineers, Business Stakeholders.
Important: Without setting this stage up properly you risk the project being deprioritised for not showing enough business value. Remember to align with business before you start implementing, it is not enough to simply have it written down on paper.
Defining Evaluation Rules.
Metrics for LLMs are notoriously tricky. E.g. human alignment, coherence and factuality. However there are also exact rules that are extremely useful in evaluating your applications.

Some points to consider:
Very likely your system will be composed of multiple LLM calls chained together within an Agentic System topology.
For any node in your Agentic System topology you should have an evaluation dataset prepared: Inputs → Expected Outputs.
Define unacceptable responses. E.g. toxicity, hallucinations, unsafe suggestions.
Roles to involve: AI Product Managers, AI Engineers.
I will be teaching how to apply the system described in this blog hands-on and in detail as part of End-to-End AI Engineering Bootcamp (𝟭𝟬% 𝗱𝗶𝘀𝗰𝗼𝘂𝗻𝘁 𝗰𝗼𝗱𝗲: Kickoff10 )
Building a PoC.
This is a stage that is often misunderstood. You might be driven to transition from prompts to a functioning interface (CLI, chat UI, API, etc.). However, the goal here is pushing out the system to the users as soon as possible.

Points to consider:
Use LLM APIs from OpenAI, Google, Anthropic, X etc. to quickly build out the first user facing application.
Your application could be an Excel Spreadsheet with Input Output pairs rather than a full fledged functioning interface. As long as it helps moving metrics forward, it is good to be exposed.
The feedback you get from users is key to understand unknown unknowns. In my experience it almost always shifts your perspective of how to improve the application.
Roles to involve: AI Engineers.
Important: A successful LLM PoC may look like an Excel Spreadsheet. If you can’t push it out quick, there is something wrong with the process.
Instrumenting the Application.
This is where we implement best practices of Observability in LLM based systems. We do this by instrumenting the application and logging extensive set of metadata about everything that is happening underneath the surface.
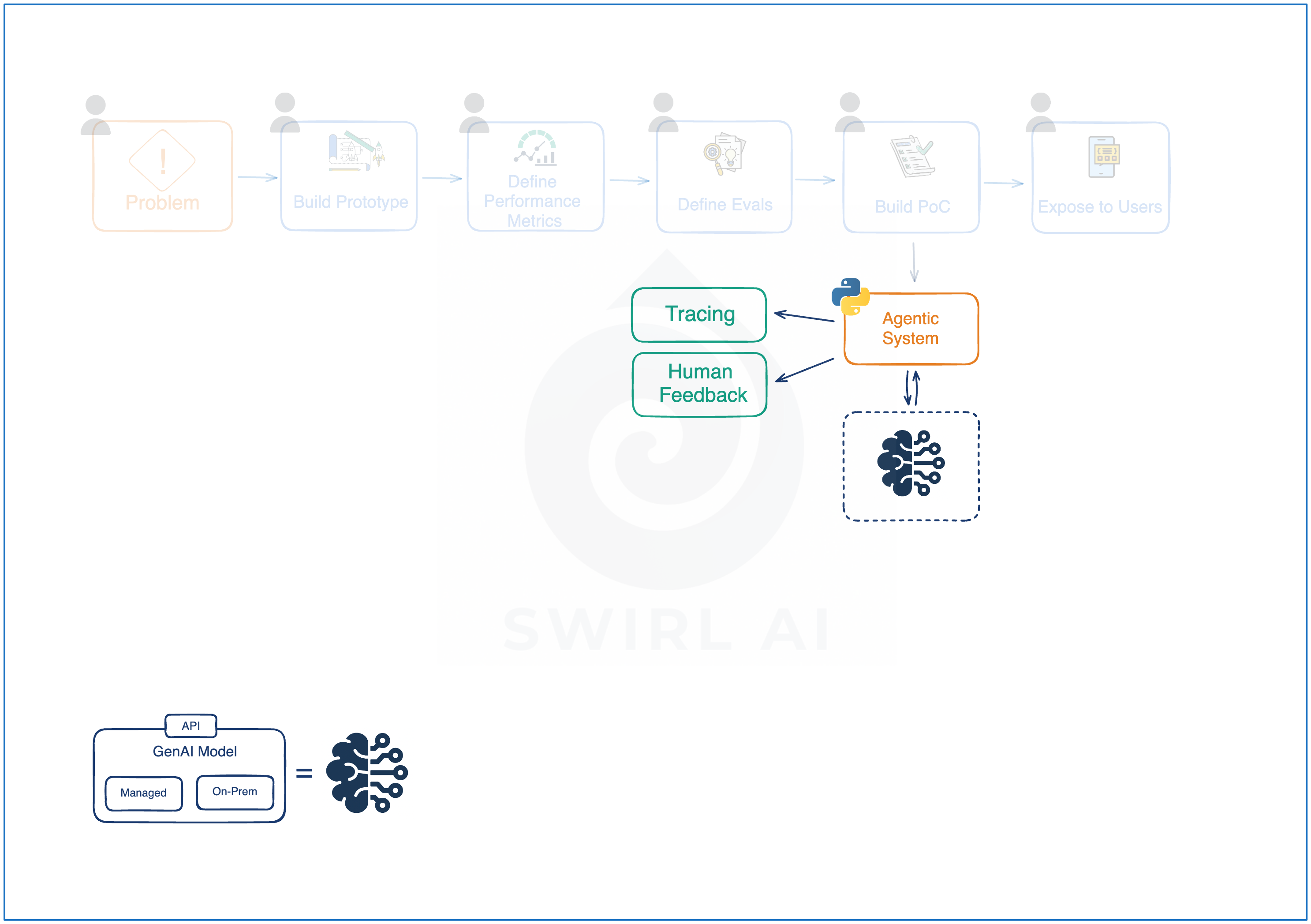
Key considerations:
Log everything: prompts, completions, embeddings, latency, token counts, and user feedback.
Add additional metadata like: prompt versions, user inputs, model versions used.
Make sure that the chains are properly connected and you know the ordering of operations.
When working with multimodal data log different kinds of data like PDFs, Image, Audio, Video.
Remember that outputs of one LLM call will often become inputs to the next one.
Don’t forget the user feedback! Always attach it to the traces that represent the run users were interacting with when the feedback was provided.
Roles to involve: AI Engineers.
Important: This stage is one of the key elements in implementing Evaluation Driven Development.
Integrating with an Observability Platform.
It is not enough to just track the data, you need to be able to efficiently visualise and analyse it. This is where Observability platform come into play they help with efficient search and visualisation as well as prompt versioning and adding automated evaluation capabilities.

Key considerations:
Store your Evaluation rules as part of the platform as you will later apply them on the traces.
Use these platforms as Prompt Registries as your application is a chain of prompts, you will want to analyse and group the evaluation results by Prompt Groups.
Most successful applications reach scale and it becomes too expensive to store all of the traces produced. Observability Platforms have smart sampling algorithms that allow you to store subset of incoming traces.
Most of the Observability Platforms come with their own tracing SDKs, use them for seamless Instrumentation.
Roles to involve: AI Engineers.
Important: Set this up early as it will bring the visibility to the black box.
Evaluating Traced Data.
If you have successfully implemented the previous stages, you will have all of the required pieces to successfully measure your application that has been exposed to the users. Here is where you run Evals on top of the trace data.

Key considerations:
Assumption: You have your Evaluation rules stored in the Observability platform together with the incoming traces via your instrumented application and human feedback attached to corresponding traces.
Run the Evals automatically on the traces that hit the Observability Platform.
Filter out all of the traces that have failing evals or negative human feedback. It is up to you to decide what a failing eval or negative feedback is.
We will focus mostly on this “failing” data moving on.
Roles to involve: AI Engineers.
Important: Running Evals can often be expensive, especially if you are using LLM as a judge tactic in some places. You might want to sample the traces you would be running evals on.
Evolving the Application.
You are now ready to improve your application if you have the above figured out.
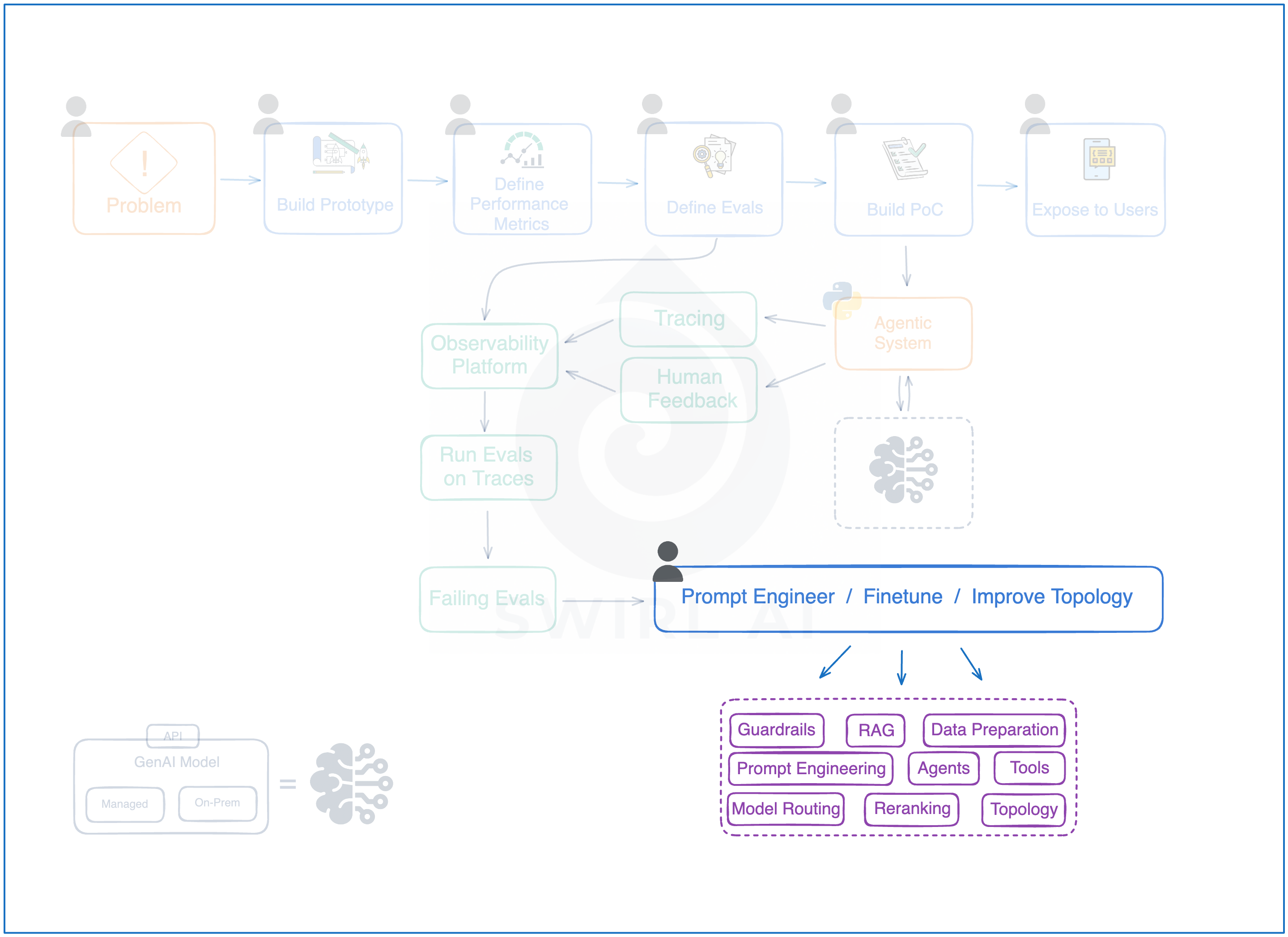
Key considerations:
Focus on Failing Evaluations and human feedback to pinpoint where the improvement is needed.
If your current topology is not up to the task, make it more complex: Simple Prompts → RAG → Agentic RAG → Agents → Multi-agent systems.
Make the system more complex only if there is a hard requirement, focus on better prompt engineering, data preprocessing, tool integration.
You can read more about the evolution of Modern RAG Systems in one of my previous blogs here:

A powerful concept in Evaluation Driven Development is having a failing eval dataset that you would never solve for 100%. Your goal is to achieve that but by adding more and more failing samples you never get to that 100%.
Roles to involve: AI Engineers, Domain Experts.
Important: Always involve Domain Experts in this stage, they have the insider knowledge about tasks you want to automate, they can even suggest better prompts to solve the problem.
Exposing new version of the Application.
This one is quick - expose new versions of the application as fast as possible. The feedback you will be getting on the updates is invaluable.

Key considerations:
Deploying new versions fast is important for few reasons:
It improves UX as the present problems get fixed.
Some fixes will generalise to unknown problems and you will be solving multiple bugs with one shot.
Be sure to have strict release tests. You should always have evaluation datasets ready so that you know that what is being released is not worse compared to previous version. Integrate these checks into your CI/CD pipelines.
Roles to involve: AI Engineers, Domain Experts.
Continuous Development and Evolution of the Application.
The highlighted loop in the image is the key part of the process when it comes to continuous evolution of your application

Key considerations:
Remember: Build → Trace, collect feedback → Evaluate → Focus on Failing Evals and Negative Feedback → Improve the application → Iterate.
As your business requirements become more complex, you might add additional functionality to the application. Very often this would be added as a new route in your Agentic System Topology. E.g. a simple chatbot evolving into a system that can manage your shopping cart automatically on your instruction.
In order to add additional functionalities you should follow the process of building a prototype, defining performance metrics and new evals.
This is where multiple AI Engineers can start more easily work on a single project as new independent routes can be developed as a separate functionality.
Roles to involve: AI Engineers, Domain Experts, AI Product Managers.
Monitoring and Alerting.
After you have implemented all of the tracing end evaluation for development purposes, monitoring almost comes out of the box - you have implemented evaluations and traces for development purposes, they can be reused for monitoring. Configure specific alerting thresholds and enjoy the peace of mind.

Key considerations:
You already have most of the data that is relevant for LLM specific production monitoring if you have properly implemented application instrumentation.
If you haven’t yet, consider tracing and logging additional advanced metric like TTFT (Time To First Token), inter-token latency etc.
You will need to figure out the threshold for alerting.
Roles to involve: AI Engineers.
Important: Try to avoid Alert Fatigue by carefully configuring thresholds that would kick off alerts. Avoid False Positives as much as possible.
Wrapping up.
Development of LLM based Agentic Systems is different from traditional software and techniques like Evaluation Driven Development are key for success.
Observability and Evaluation is key and should be implemented early in the project lifecycle.
Having well defined business success metrics up front will help you avoid reprioritisation of your projects long term and keep the business buy in.
Figure out if what you are about to build is feasible early on and drop the idea if it is not. There are too many low hanging fruits with high impact, use your time wisely.
Hope you enjoyed the writeup and hope to see you in the next one!
I will be teaching how to apply the system described in this blog hands-on and in detail as part of End-to-End AI Engineering Bootcamp (𝟭𝟬% 𝗱𝗶𝘀𝗰𝗼𝘂𝗻𝘁 𝗰𝗼𝗱𝗲: Kickoff10 )
RAISE Summit is approaching and I am proud to be an official ambassador for the event.

Want to Join?
You can win a ticket by filling out this form:
Or secure your place with discount code: amEV73 for 20% off.
Brilliant article Aurimas! Thank you 🔥