
The evolution of Modern RAG Architectures.
Learn how to choose the best RAG architecture for your business case.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in GenAI, MLOps, Data Engineering, Machine Learning and overall Data space.
RAG (Retrieval Augmented Generation) based systems have been, and continue to be, one of the the most useful applications utilising LLMs in enterprises. I remember writing the first post about RAG almost 2 years ago when the term itself was not yet widely adopted.

What I described back then was a RAG system implemented in the most naive way possible. The industry has evolved far since then by introducing different kinds of advanced techniques to the process.
In this Newsletter episode we will go through the evolution of RAG, from Naive to Agentic. After reading through you will understand what challenges have been tackled by each step in evolution.
The emergence of Naive RAG.
Naive RAG has emerged almost at the same time as the LLMs have become mainstream with introduction of ChatGPT at the end of 2022. The Retrieval Augmented Generation technique was brought to life in order to solve for issues that native LLMs faced. In short:
Hallucinations.
Limited Context window size.
Lack of access to non-public data.
Parametric knowledge limited to the latest data the model was trained on.
The simplest implementation of RAG can be defined in the following steps:
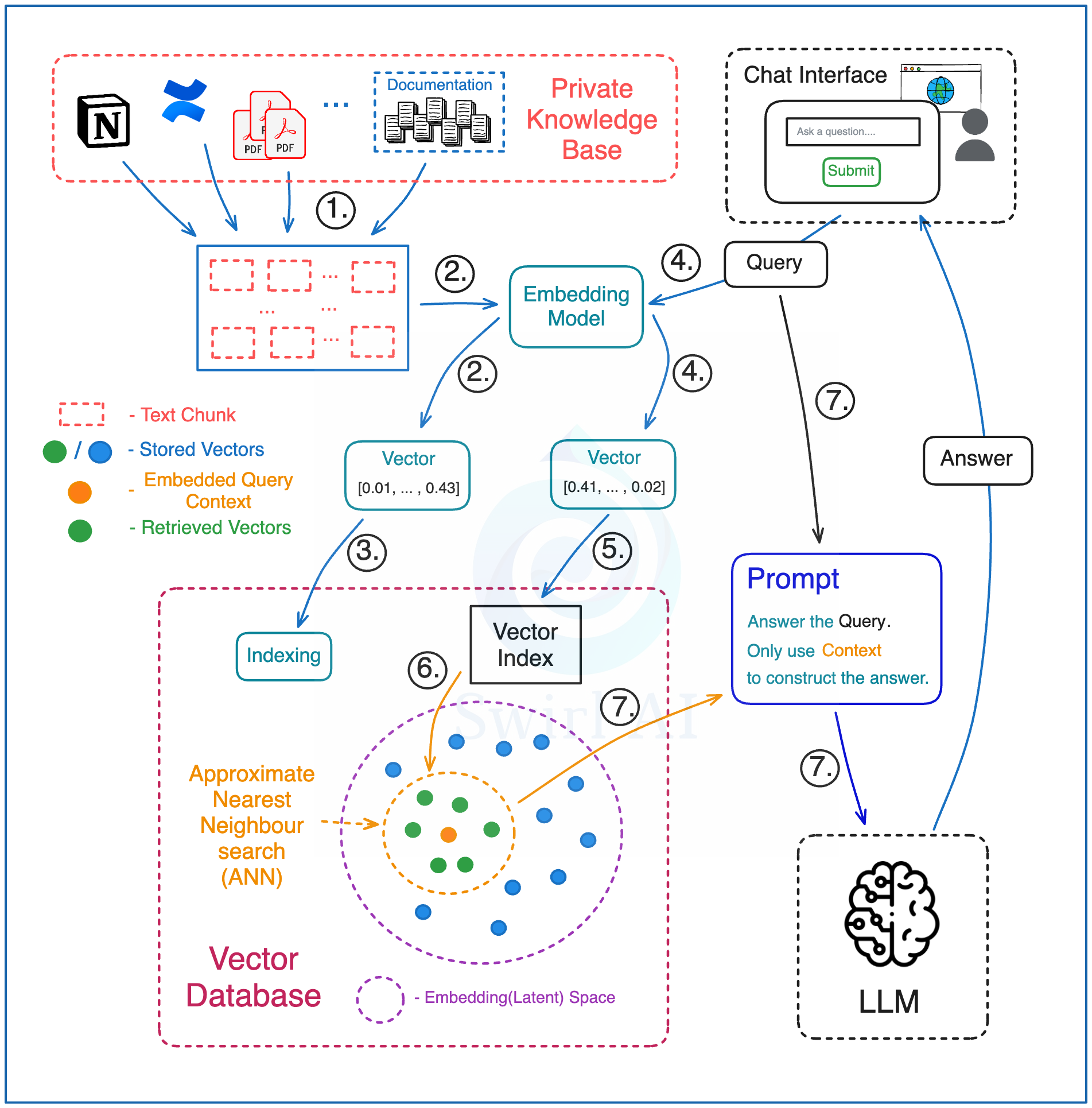
Preprocessing:
Split text corpus of the entire knowledge base into chunks - a chunk will represent a single piece of context available to be queried. Data of interest can be from multiple sources, e.g. Documentation in Confluence supplemented by PDF reports.
Use the Embedding Model to transform each of the chunks into a vector embedding.
Store all vector embeddings in a Vector Database. Save text that represents each of the embeddings separately together with the pointer to the embedding.
Retrieval:
Embed a question/query you want to ask using the same Embedding Model that was used to embed the knowledge base itself.
Use the resulting Vector Embedding to run a query against the index in the Vector Database. Choose how many vectors you want to retrieve from the Vector Database - it will equal the amount of context you will be retrieving and eventually using for answering the query question.
Vector DB performs an Approximate Nearest Neighbour (ANN) search for the provided vector embedding against the index and returns previously chosen amount of context vectors. The procedure returns vectors that are most similar in a given Embedding/Latent space. Map the returned Vector Embeddings to the text chunks that represent them.
Pass a question together with the retrieved context text chunks to the LLM via prompt. Instruct the LLM to only use the provided context to answer the given question. This does not mean that no Prompt Engineering will be needed - you will want to ensure that the answers returned by LLM fall into expected boundaries, e.g. if there is no data in the retrieved context that could be used make sure that no made up answer is provided.
Moving pieces in the Naive RAG system.
Even without any advanced techniques, there are many moving pieces to consider when building a production Grade RAG system.

Retrieval:
F) Chunking - how do you chunk the data that you will use for external context.
Small, Large chunks.
Sliding or tumbling window for chunking.
Retrieve parent or linked chunks when searching or just use originally retrieved data.
C) Choosing the embedding model to embed and query and external context to/from the latent space. Considering Contextual embeddings.
D) Vector Database.
Which Database to choose.
Where to host.
What metadata to store together with embeddings. The data to be used for pre-filtering and post-filtering.
Indexing strategy.
E) Vector Search.
Choice of similarity measure.
Choosing the query path - metadata first vs. ANN first.
Hybrid search.
G) Heuristics - business rules applied to your retrieval procedure.
Time importance.
Duplicate context (diversity ranking).
Source retrieval.
Conditional document preprocessing.
Generation:
A) LLM - Choosing the right Large Language Model to power your application.
B) Prompt Engineering - having context available for usage in your prompts does not free you from the hard work of engineering the prompts. You will still need to align the system to produce outputs that you desire and prevent jailbreak scenarios.
After all of this work we have ourselves a working RAG system.
The harsh truth - this is rarely good enough to solve real business problems. The accuracy of this kind of system might be low for various reasons.
Advanced techniques to improve Naive RAG.
Some of the more successfully adopted techniques to continuously improve accuracy of Naive RAG systems are the following:
Query Alteration - there are few techniques that can be employed:
Query rewriting - ask LLM to rewrite original query to better fit the retrieval process. It can be rewritten in multiple ways. E.g. fixing grammar, simplifying the query to keep short succinct statements.
Query Expansion - ask LLM to rewrite the query multiple times to create multiple variations of it. Then, run retrieval process multiple times to retrieve more, potentially relevant, context.
Reranking - rerank the originally retrieved documents using heavier process compared to regular contextual search. Usually, this involves using a larger model and retrieving considerably more documents than needed during the retrieval phase. Reranking also works well with Query Expansion pattern from previous point as it return more data than usual. The overall process is similar to what we are used to seeing in Recommendation Engines. I wrote about such architectures a while ago here (second paragraph):
Fine-Tuning of the embedding model - retrieval of data in some domains (e.g. medical data) works poorly with base embedding models. This is where you might need to fine-tune your own embedding model.

Let’s move on to some other advanced RAG techniques and architectures.
Contextual Retrieval.
The idea of Contextual Retrieval was suggested by the Anthropic team late last year. It aims to improve accuracy and relevance of data that is retrieved in Retrieval Augmented Generation based AI systems.
I love the intuitiveness and simplicity of Contextual Retrieval. And it does provide good results.
Here are the steps of implementation:

Preprocessing:
Split each of your documents into chunks via chosen chunking strategy.
For each chunk separately, add it to a prompt together with the whole document.
Include instructions to situate the chunk in the document and generate short context for it. Pass the prompt to a chosen LLM.
Combine the context that was generated in the previous step and the chunk that the context was generated for.
Pass the data through a TF-IDF embedder.
Pass the data through a LLM based embedding model.
Store the data generated in steps 5. and 6. in databases that support efficient search.
Retrieval:
Use user query for relevant context retrieval. ANN search for semantic and TF-IDF index for exact search.
Use Rank Fusion techniques to combine and deduplicate the retrieved results and produce top N elements.
Rerank the previous results and narrow down to top K elements.
Pass the result of step 10. to a LLM together with the user query to produce the final answer.
Some thoughts:
Step 3. might sound extremely costly and it is, but with Prompt Caching, the costs can be significantly reduced.
Prompt caching can be implemented in both proprietary and open source model cases (refer to the next paragraph).
The brief emergence of Cache Augmented Generation.
At the end of 2024 a white paper briefly shook the social media. An introduction of a technique that would change RAG forever (or would it?) - Cache Augmented Generation. We already know how regular RAG works, here is a brief description of CAG:

Pre-compute all of the external context into a KV Cache of the LLM. Cache it in memory. This only needs to be done once, the following steps can be run multiple times without recomputing the initial cache.
Pass the system prompt including user query and the system prompt with instructions on how cached context should be used by the LLM.
Return the generated answer to the user. After this, clear any generations from the cache and keep only the initially cached context. This makes the LLM ready for next generations.
CAG promised a more accurate retrieval by storing all of the context in the KV cache instead of retrieving just a portion of data each time the answer needs to be computed. The reality?
CAG does not solve the inaccuracies given extremely long context.
CAG has many limitations when it comes to data security.
Loading the entire internal knowledge base is close to impossible in large organisations.
Cache becomes static and adding fresh data is problematic.
Actually, we were using a variant of CAG for some time already after introduction of prompt caching by most of the LLM providers. What we did can be described as a fusion of CAG and RAG and implemented in the following procedure:

Data Preprocessing:
We use only rarely changing data sources for Cache Augmented Generation. On top of the requirement of data changing rarely we should also think about which of the sources are often hit by relevant queries. Once we have this information, only then we pre-compute all of this selected data into a KV Cache of the LLM. Cache it in memory. This only needs to be done once, the following steps can be run multiple times without recomputing the initial cache.
For RAG, if necessary, precompute and store vector embeddings in a compatible database to be searched later in step 4. Sometimes simpler data types are enough for RAG, a regular database might suffice.
Query Path:
Compose a prompt including user query and the system prompt with instructions on how cached context and retrieved external context should be used by the LLM.
Embed a user query to be used for semantic search via vector DBs and query the context store to retrieve relevant data. If semantic search is not required, query other sources, like real time databases or web.
Enrich the final prompt with external context retrieved in step 4.
Return the final answer to the user.
Let’s move to the latest evolution - Agentic RAG.
Agentic RAG.
Agentic RAG has added two additional components that attempted to reduce inconsistencies when answering complex user queries.
Data Source Routing.
Reflection.
Let’s explore how it works end-to-end.
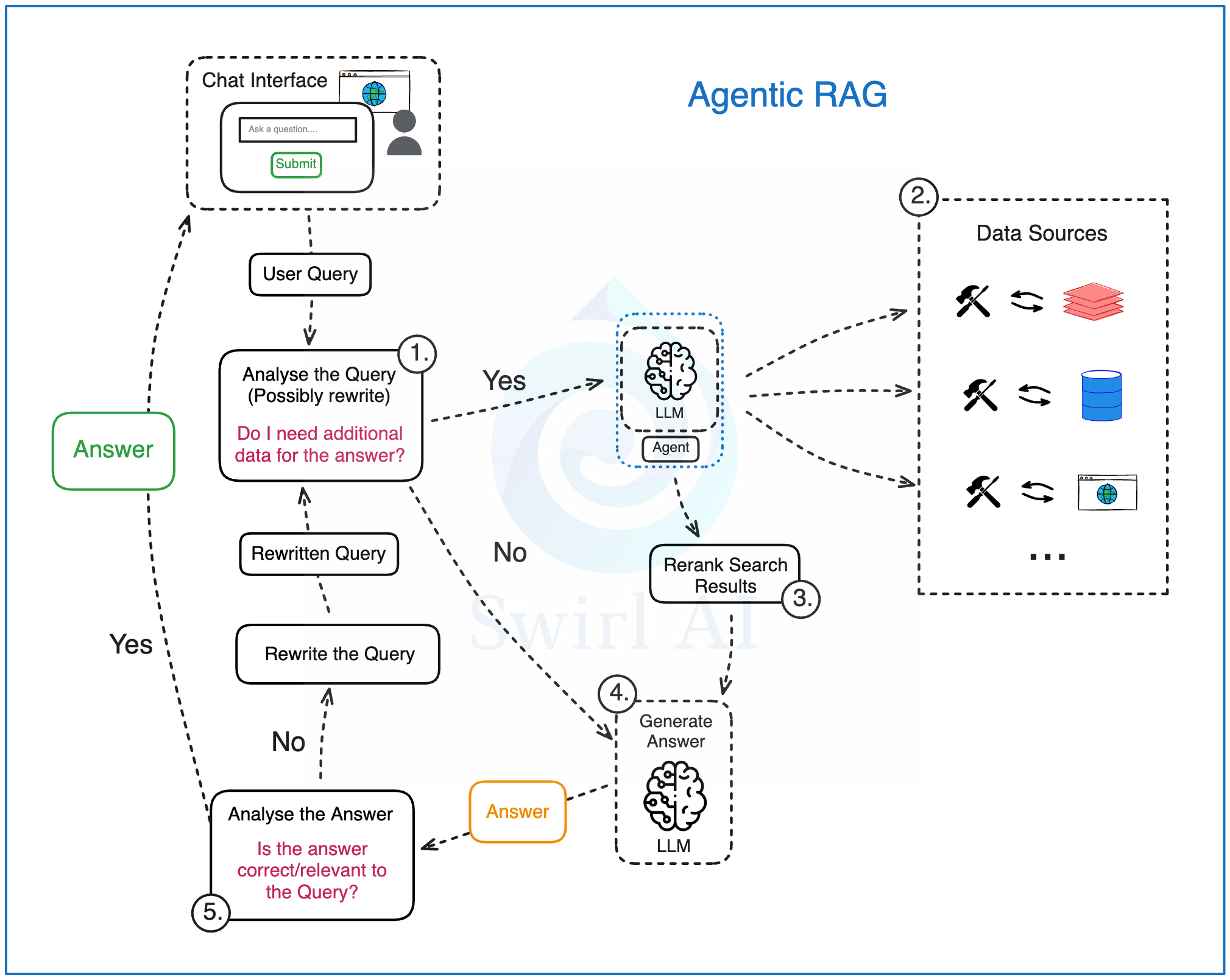
Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where:
The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline.
The agent decides if additional data sources are required to answer the query. This is where the first step of agency kicks in.
If additional data is required, the Retrieval step is triggered. This is where Data Source Routing happens, you could have one or multiple data sets available for the Agentic RAG system and the Agent is given agency to choose which ones should be tapped into to answer this specific query. Few examples:
Real time user data. This is a pretty cool concept as we might have some real time information like current location available for the user.
Internal documents that a user might be interested in.
Data available on the web.
…
Once the data is retrieved from potentially multiple data sources, we rerank it similarly like in regular RAG. This is also and important step as multiple different data sources utilising different storage technologies can be integrated into the RAG system here. Complexities of the retrieval process can be hidden behind tools given to the agent.
We try to compose the answer (or multiple answers or a set of actions) straight via LLM. It can happen in the first round or after the Reflection happens.
The answer gets analysed, summarised and evaluated for correctness and relevance:
If the Agent decides that the answer is good enough, it gets returned to the user.
If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop. This is where the second difference of Regular vs. Agentic RAG is implemented.
Recently open-sourced MCP project by Anthropic can supercharge the development of Agentic RAG applications. Learn how in one of my previous Newsletter episodes:

Wrapping up.
We have reviewed the evolution of Modern RAG architectures. RAG is not dead and is not going anywhere anytime soon. I believe the architectures will continue evolving for some time to come and it is a good investment to learn them, and understand when to use what.
In general, the simpler the better as you will face new challenges while making the system more complex. Some of the emerging challenges include:
Difficulties in evaluating the end-to-end system.
Increase in end-to-end latency due to multiple LLM calls.
Increase in the price of operation.
…
This is it! Hope to see you in the next issue.
The 9-to-do-list trap is too real. Good breakdown of the whole setup process. If anyone reading this wants to keep learning after they've got it running, Anthropic actually put out 13 free courses covering Claude Code, MCP, agent skills and the rest of the dev stack. Certificates too. I wrote up the full catalogue here: https://reading.sh/anthropic-is-giving-away-13-free-ai-courses-with-certificates-94e2c08623e2The evolution might be heading toward no RAG at all in some contexts. Anthropic's Claude Code team evolved through RAG architectures and ended up at grep. The model searching for its own context outperformed every retrieval approach they tried. Covered the full evolution here: https://reading.sh/anthropic-revealed-how-they-build-claude-codes-brain-11e48e75fd01?sk=6662727c70ed637cd1692a81f33139e2
RAG evolution is game-changing for LLM systems. Great breakdown of the architecture flow! This is exactly what scaling AI apps needs. 💯