SAI #10: Airflow - Architecture, Model Deployment - AutoScaling and more...
Model Deployment - AutoScaling, Recommender/Search System Design, Airflow - Architecture, Kafka - Reliability, NEDEPT - Enricher/Validator.

👋 This is Aurimas. I write the weekly SAI Newsletter where my goal is to present complicated Data related concepts in a simple and easy to digest way. The goal is to help You UpSkill in Data Engineering, MLOps, Machine Learning and Data Science areas.
In this episode we cover:
Airflow - Architecture.
Search/Recommender System Design.
Model Deployment - AutoScaling.
Kafka - Reliability.
No Excuses Data Engineering Template: Enricher/Validator.
Airflow - Architecture.
Airflow has become almost fundamental when it comes to orchestration and scheduling of tasks in the Data Engineering Field.
If you are running self hosted Airflow in your company it helps tremendously to understand what the system is made of so that when it breaks you can fix it fast. Today we look into its Architecture.
Airflow is composed of several microservices that work together to perform work. Here are the components:
Scheduler.
➡️ Central piece of Airflow architecture.
➡️ Performs triggering of scheduled workflows.
➡️ Submits tasks to the executor.
Executor.
➡️ Part of the scheduler process.
➡️ Handles task execution.
➡️ In production workloads pushes tasks to be performed to workers.
➡️ Can be configured to execute against different Systems (Celery, Kubernetes etc.)
Worker.
➡️ The unit that actually performs work.
➡️ In production setups it usually takes work in the form of tasks from a queue placed between workers and the executor.
Metadata Database.
➡️ Database used to store the state by Scheduler, Executor and Webserver.
DAG Directories.
➡️ Airflow DAGs are defined in Python code.
➡️ This is where you store the DAG code and configure Airflow to look for DAGs.
Webserver.
➡️ This is a Flask Application that allows the user to explore, debug and partially manipulate Airflow DAGs, users and configuration.
❗️ Two most important parts are the Scheduler and the Metadata DB.
❗️ Even if Webserver is down - tasks will be executed as long as the Scheduler is healthy.
❗️ Metadata DB transaction locks can cause problems for other services.

Search/Recommender System Design
Recommender and Search Systems are one of the biggest money makers for most companies when it comes to Machine Learning.
Both Systems are inherently similar. Their goal is to return a list of recommended items given a certain context - it could be a search query in the e-commerce website or a list of recommended songs given that you are currently listening to a certain song on Spotify.
The procedure in real world setups usually consists of two steps:
Candidate Retrieval.
Offline(training) part:
➡️ We train embedding model that will be used to transform inventory items into vector representations.
➡️ Deploy the model as a service to be later used for real time embedding.
➡️ We apply previously trained embedding model on all owned inventory items.
➡️ Build an Approximate Nearest Neighbours search index from the embeddings.
➡️ Define additional filtering rules for retrieved candidates (e.g. don’t allow heavy metal songs for children under 7 years old).
Online(deployment) part:
➡️ Once an item comes, we embed it into a vector representation using the model from the offline part.
➡️ Use Approximate NN index to find n most similar vectors.
➡️ Apply additional filtering rules defined in the offline part
Candidate Ranking.
Offline(training) part:
➡️ We build a Feature Store for item level features and expose it for real time feature retrieval.
➡️ Train a Ranking Model using the Features.
➡️ Deploy the model as a service to be later used for real time Scoring.
➡️ Define additional Business rules that would overlay additional scores (e.g. downscore certain brands).
Online(deployment) part:
➡️ Chaining from the previous online step we enrich retrieved candidates with features from the Feature Store.
➡️ Apply Ranking model for candidates to receive item scores.
➡️ Order by scores and apply additional business rules on top.
✅ By chaining both Online parts of Candidate Retrieval and Candidate Ranking end-to-end we get a recommendation list that is shown to the user.
✅ Results and user actions against them are piped back to the Feature Store to improve future Ranking Models.
❗️ Both Candidate Retrieval and Ranking Systems could be different to what is presented here as this is just a general example.

Model Deployment - AutoScaling.
We already know the main types of Machine Learning Model Deploymehat you will run into in real life situations: Batch, Embedded into a Stream Application and Request-Response. We also know how the scaling works in each situation.
Today we look into how autoscaling for these types of deployments could be implemented.
In the Core of each case sits the Scaling Controller Application that makes decisions on how to scale the ML Application.
Batch.
➡️ Controller extracts metadata about the Data on which you would apply the Inference.
➡️ Calculate the number of rows that Inference would be applied to.
➡️ Controller estimates the size of a cluster needed to perform inference on a given size of Data in a Specific amount of time.
➡️ Cluster of calculated size is launched.
➡️ The Cluster performs Inference as usual.
✅ Inference should be performed close to the Estimated amount of time.
Stream.
➡️ You Perform Inference in Real Time using a cluster of your choice (e.g. Flink).
➡️ Operational Metrics about the application's health and performance are outputted to a Prometheus server.
➡️ Scaling Controller listens to a predefined metric, e.g.
👉 Average CPU Load of all applications in a Stream Processing cluster.
👉 Lag in processed messages of the Input Kafka Topic.
➡️ Controller reacts to a predefined Threshold of the metric deteriorating to a certain level.
➡️ Controller informs the cluster to scale up.
✅ This results in the operational metric improvement.
Request - Response.
➡️ You Perform Inference in Real Time by exposing REST or gRPC endpoints used by Product Applications.
➡️ Operational Metrics about the application's health and performance are outputted to a Prometheus server.
➡️ Scaling Controller listens to a predefined metric, e.g.
👉 Average CPU Load of applications in a Fleet of backend Servers.
👉 Average Response Latency.
➡️ Controller reacts to a predefined Threshold of the metric deteriorating.
➡️ Controller informs the Fleet to scale.
✅ This results in the operational metric improvement.
General Notes:
❗️For Stream and Request-Response deployment model a similar procedure should be implemented for scaling the cluster down as well.
❗️It is dangerous to rely on Response Latency only because it might not be solved by scaling the cluster up.
This is The Way.

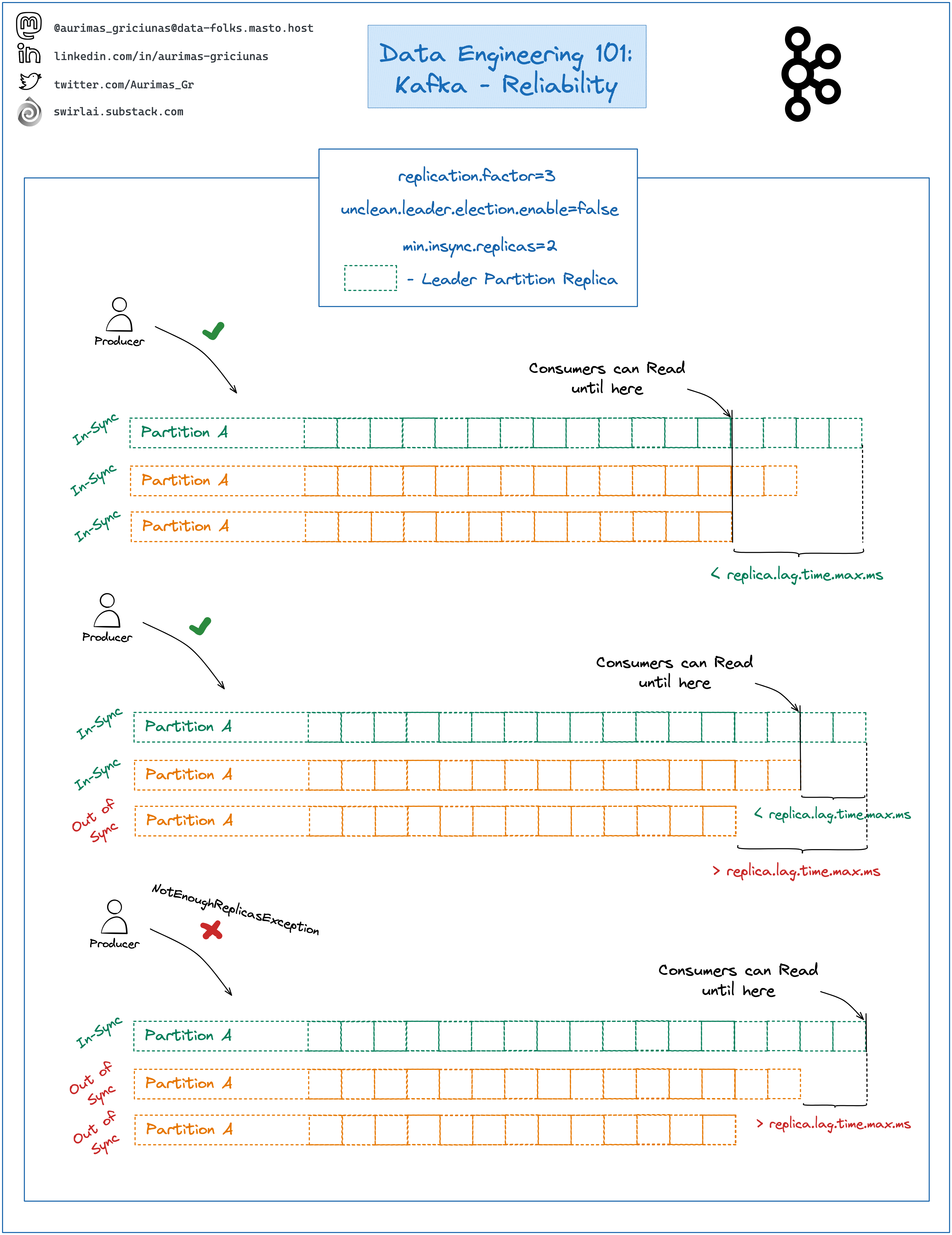
Kafka - Reliability.
Number of things can go wrong if you don’t configure your Kafka Topics correctly for Reliability Guarantees. You must understand these concepts if you want to build Robust Streaming Applications and avoid unexpected behavior.
Some Refreshers:
➡️ Kafka Cluster is composed of Brokers.
➡️ Data is stored in Topics that can be compared to tables in Databases.
➡️ Topics are composed of Partitions.
Ensuring Reliability:
➡️ Partitions of Topics will be replicated to different brokers a number of times for reliability purposes controlled by replication.factor or default.replication.factor configuration.
➡️ One of the partition replicas is labeled Leader Partition.
➡️ Data is written to the Leader Partition and replicated to remaining replicas.
➡️ Partition replicas can be in-sync or out of sync with the Leader Partition.
➡️ replica.lag.time.max.ms controls how much time the last replicated message can be lagging behind Leaders latest message for a follower partitions to be labeled in-sync.
➡️ Message is marked as committed when it is replicated to each in-sync partition replica.
➡️ Consumers only read committed messages.
➡️ If the Producer is configured to wait for acknowledgment of a full commit - it will wait for full in-sync replication.
❗️This might and will slow down the producer if there are lagging Partition replicas that are still in-sync.
➡️ You can ensure Reliability from Kafka Broker side by configuring combination of: replication.factor, unclean.leader.election.enable and min.insync.replicas.
➡️ unclean.leader.election.enable is set to false by default. When the Broker hosting Leader Partition goes down this configuration does not allow for election of new Leader Partition given that there are no more in-sync replicas apart from the leader that went down.
❗️Keep unclean.leader.election.enable set to false if your system should not allow data loss.
❗️If unclean.leader.election.enable is set to false and there are no in-sync replicas to be elected as Leaders the Partition becomes unreadable/writable until The Leader Partition is brought back to life.
➡️ min.insync.replicas configuration enforces minimal number of Partition Replicas that have to be in-sync for writes to be allowed.
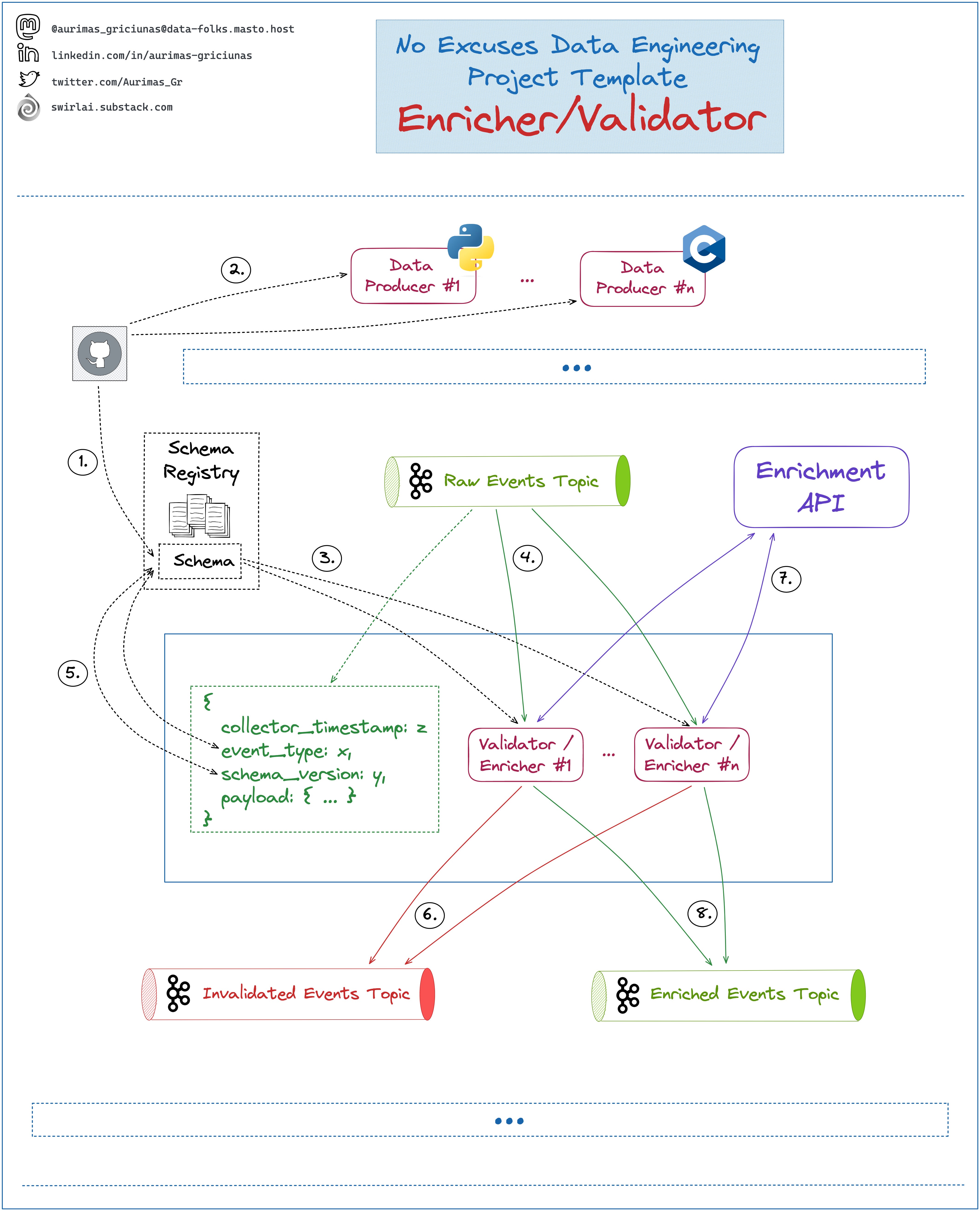
No Excuses Data Engineering Template: Enricher/Validator.
We already discussed the Collector in previous episodes, let’s go down the stream.
We build on the following:
➡️ Initial Data reaching the Data System is validated for top level fields, these include at least:
👉 Event Type.
👉 Schema Version.
👉 Payload.
➡️ Collected Data has been pushed to a Raw Events Kafka Topic.
There are multiple parts that make up ecosystem of the Enricher/Validator, let’s take a closer look:
1: Schema of the events to be emitted by Data Producers are synced with a Schema Registry.
2: Once it is Synched, a new version of Data Producer can be deployed.
3: Enricher/Validator is continuously caching schemas of all events in memory. It is always in sync with the Schema Registry.
4: Enricher/Validator reads Data from Raw Events Kafka Topic in real time as they come.
5: Combination of Event Type and Schema Version defines what schema the Payload should be validated against.
6: If Payload does not conform to the Schema - the Event is emitted to Invalidated Events Kafka Topic for further processing and recovery.
7: Validated Events are further enriched with additional Data, it could be:
👉 An in memory Lookup Table.
👉 Enrichment API Service (Could be a ML Inference API).
👉 …
8: Validated and Enriched Data is pushed into Enriched Events Kafka Topic for downstream processing.
General notes:
❗️ Schemas must be synced with Enricher/Validator before they are deployed to the Data Producers. If not - the produced event will be invalidated.
❗️ Enrichment could also fail - it is a good idea to have a separate Kafka Dead Letter Topic to send these failed events for further processing.
❗️ You don’t want to have too much retry logic in Enrichers/Validators as it would slow down and potentially stop the pipeline.