
The SwirlAI Data Engineering Project Master Template.
And why you should consider implementing it as a Data Engineer looking to up-skill in the field.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
Some time ago I started putting together a comprehensive template for a Data Engineering project. Today I want to introduce a high-level overview of it and why you should consider implementing it (or just follow future articles around it in order to learn Data Engineering).
I wanted to create a single template that would allow you to learn technical nuances of everything that you might run into as a Data Engineer in a single end-to-end project. I also want this to be a map which would allow me to explain some of the fundamental concepts I talk about in the Newsletter and map them to a specific use case that would be implemented in the Template.
In this Newsletter episode I will lay out the high-level structure of the template. Every few weeks as part of premium Newsletter tier I will be releasing a hands-on tutorial on implementing a piece of the template until it becomes an end-to-end infrastructure project that generalises to any type of data you might want to push through the data pipeline - from data creation till being able to serve it. We will also learn the most crucial components of Kubernetes as we will be deploying the project on a K8s cluster.
Today on a high level we cover:
Introduction to the template.
Why this template might be a good idea to implement if you want to up-skill as a Data Engineer.
Scaling Infrastructure of the template and making it production ready.
Real Time Pipeline:
The Collector.
Enricher/Validator.
Enrichment/Machine Learning API.
Real Time Loader.
Batch Loader.
Batch Pipeline.
Introduction to the template.
As mentioned before, the template is meant to cover a lot of different data manipulation patterns, hence it is relatively extensive. Here are the pieces:
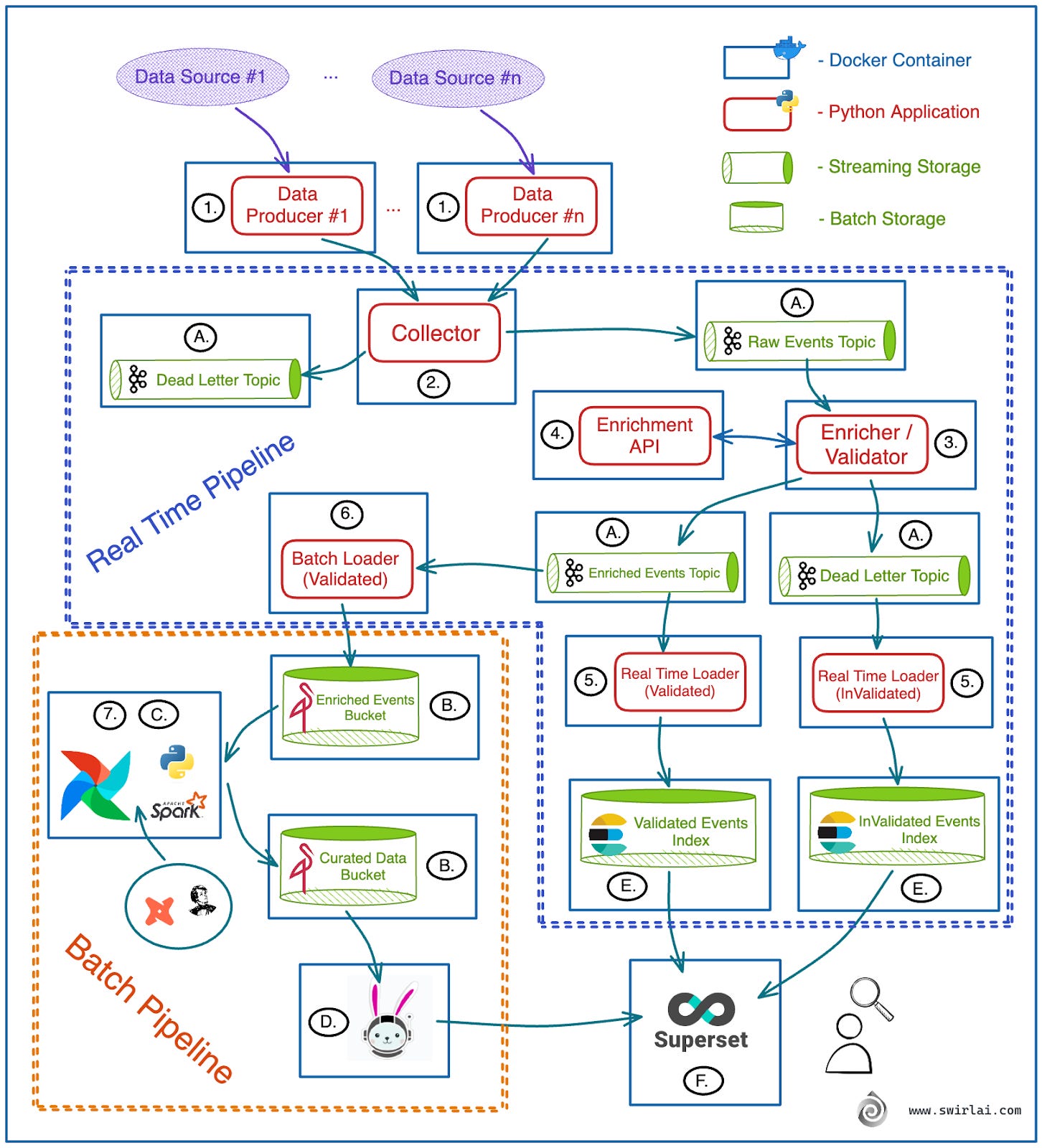
Real Time Pipeline:
Data Producers - these are independent applications that extract data from chosen Data Sources and push it in real time to the Collector application via REST or possibly gRPC API calls.
Collector - REST or gRPC API (it is important to note here that you will be able to use gRPC only in Private Network. If it is Public, you would have to go with REST) that takes a payload (json or protobuf in case of gRPC), validates top level field existence and correctness, adds additional metadata and pushes the data into either Raw Events Topic if the validation passes or a Dead Letter Queue if top level fields are invalid.
Enricher/Validator - Stream Processing Application that validates schema of events in Raw Events Topic, performs some (optional) data enrichment and pushes results into either Enriched Events Topic if the validation passes and enrichment was successful or a Dead Letter Queue if any of previous have failed.
Enrichment API - API of any flavour that will be called for enrichment purposes by Enricher/Validator. This could be a Machine Learning Model deployed as an API as well.
Real Time Loader - Stream Processing Application that reads data from Enriched Events and Enriched Events Dead Letter Topics and writes them in real time to ElasticSearch Indexes for Real Time Analysis and alerting.
Batch Loader - Stream Processing Application that reads data from Enriched Events Topic, batches it in memory and writes to MinIO or other kind of Object Storage.
Batch Pipeline:
This is where scripts Scheduled via Airflow or any other pipeline orchestrator read data from Enriched Events MinIO bucket, validate data quality, perform deduplication and any additional Enrichments. Here you also construct your Data Model to be later used for reporting purposes.
Some of the Infrastructure elements that will be needed.
A. A single Kafka instance that will hold all of the Topics for the Project.
B. A single MinIO instance that will hold all of the Buckets for the Project.
C. Airflow instance that will allow you to schedule Python or Spark Batch jobs against data stored in MinIO.
D. Presto/Trino cluster that you mount on top of Curated Data in MinIO so that you can query it using Superset.
E. ElasticSearch instance to hold Real Time Data.
F. Superset Instance that you mount on top of Trino Querying Engine for Batch Analytics and Elasticsearch for Real Time Analytics.
Why might this Template be a good idea to implement if you want to up-skill as a Data Engineer?

I have constructed the Template referring to my experience, I tried to make a single template that would allow you to learn most Data manipulation patterns out there.
You are most likely to find similar setups in real life situations. Seeing something like this implemented signals a relatively high level of maturity in Organizations Data Architecture.
You can choose to go extremely deep or light on any of the architecture elements when learning and studying The Template. It can be implemented while starting from different pieces of it as a starting point.
We will cover most of the possible Data Transportation/Manipulation Patterns:
Data Producers - Data extraction from external systems. You can use different technologies for each of the Applications.
Collector - API to Collect Events. Here you will acquire skills in building REST/gRPC Servers and learn the differences.
Enrichment API - API to expose data Transformation/Enrichment capability. This is where we will learn how to expose a Machine Learning Model as a REST or gRPC API.
Enricher/Validator - Stream to Stream Processor. Extremely important, as here we will enrich Data with ML Inference results in real time and more importantly ensure that Data Contract is respected between Producers and Consumer of the Data.
Batch Loader - Stream to Batch Storage Sink. Here we will learn object storage and how to effectively serialize data so that downstream Batch Processing jobs would be most efficient and performant.
Real Time Loader - Stream to Real Time Storage Sink. We will learn how to use Kafka Consumers to write data to Real Time Storage and observe Data coming in Real time through Superset Dashboards.
Batch Pipeline - We will look into concepts such as: difference between Data Warehouse, Data Lake and Data Lakehouse, what are Bronze, Silver and Golden layers in Data Lakehouse Architecture, what are SLAs, how can you leverage DBT, internals and best practices of Airflow and much more.
Everything will be containerised and deployed on a local Kubernetes cluster, you will be able to redeploy it to any Cloud without much needed change.
The Template is Dynamic - in the process we will add the entire MLOps Stack to The Template. As we build the template out, we might decide to add some additional elements that have not been mentioned in this Newsletter episode.
How do we scale the infrastructure of the Template and make it ready for production?
Here are some critical aspects that should be implemented in any real life production system and that we will also implement in the Template:
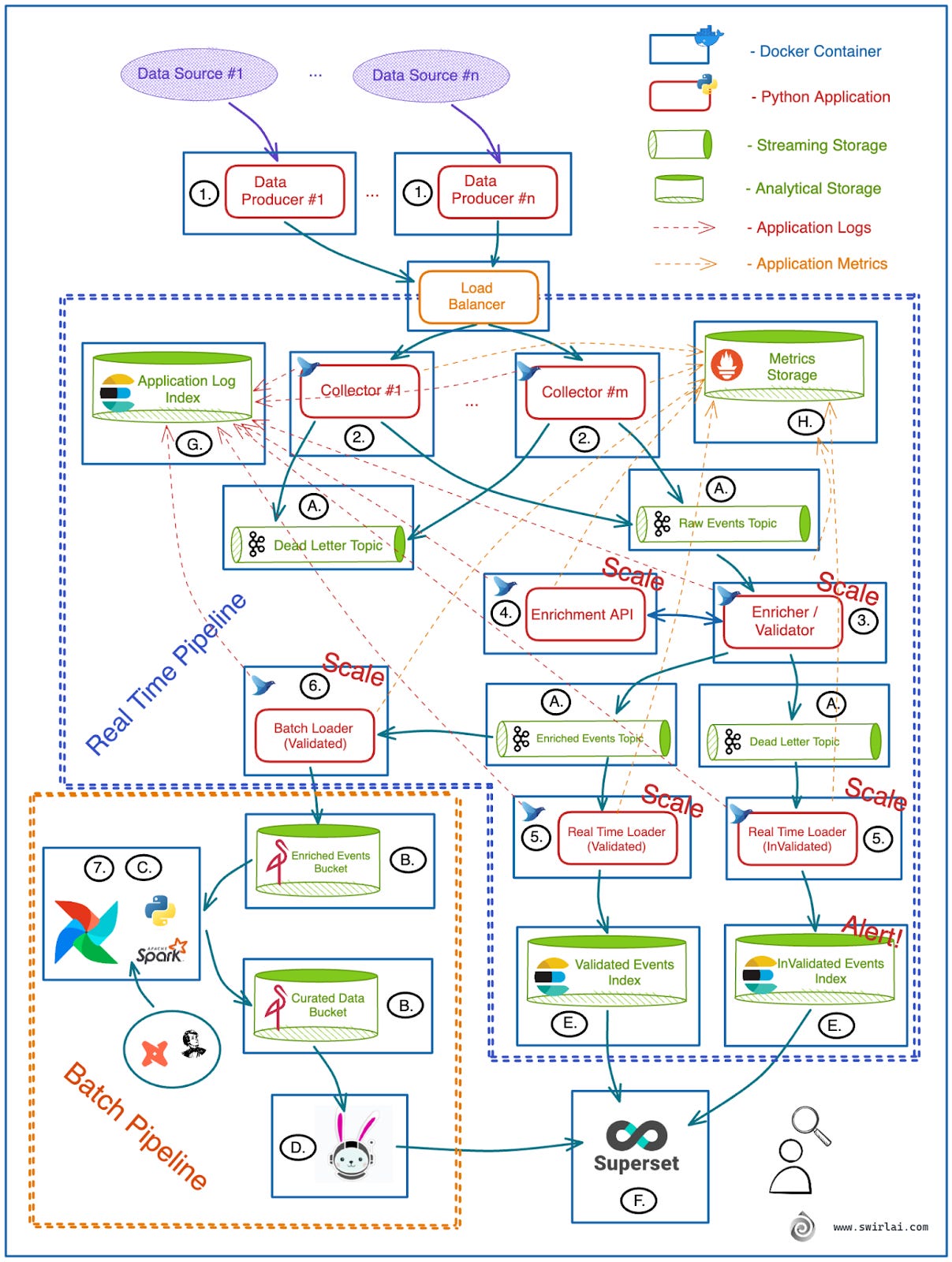
Make Collector application (2.) Highly Available by introducing horizontal scaling and facing the resulting services with a Load Balancer.
Bonus points for introducing autoscaling.
Ensure that each Application that reads from Kafka (3., 5., 6.) are deployed via means of Consumer groups for horizontal scalability.
Implement centralised logging for your Real Time Applications (2.- 6.).
Use FluentD sidecar containers that would pass application logs to a separate index in ElasticSearch (G.).
Mount Kibana on top of Elasticsearch for easy Log Access.
Implement centralised Application Metric collection for any Python application (2.- 6.).
Use Prometheus Server (H.) to collect metrics from the applications.
Mount Grafana on top of Prometheus for convenient Metrics exploration.
We will also use these metrics to implement autoscaling.
Implement Alerting for data in Dead Letter Topics.
Use either a separate Stream Processing Application or pipe data to Elasticsearch for Real Time Access and calculate alerting metrics on an interval.
This is probably unnecessary to say, but test your code and run CI/CD for all of your applications.
All of the above are a minimum must haves for a robust and stable system.
In the remainder of the Newsletter I will define most of the elements separately in more detail.
Technologies that we will be learning at this step.
Kubernetes and Docker.
GitHub Actions.
Prometheus.
Grafana.
The Collector.
Why and when does it even make sense to have a separate Collector microservice in your Data Engineering Pipeline? First, let’s describe the function of the collector.

Data Collectors act as a Gateway to validate the correctness of Data entering your System. E.g. we could check for top level field existence that would allow us to validate Data Contracts later on in the Downstream Processes.
Collectors add additional metadata to the events. E.g. collector timestamp, collector process id etc.
By making The Collector a separate service we decouple Data Producers from Collectors. By doing this we allow implementation of the Producers using different Technologies enabling wider collaboration. At the same time we can implement Collector logic once instead of replicating it each time on Producer level.
Consequently, Data Producers can be deployed in different parts of the Network Topology. E.g. They can be a JS app running in a browser or a fleet of IOT devices emitting events to a public Load Balancer. Or it could be a Python backend server delivering ML Predictions in a private network.
Collectors are the most sensitive part of your pipeline - you want to do as little processing and data manipulation here as possible. Usually, any errors here would result in permanent Data Loss (naturally less processing on the Data Producer side is also desirable). Once the data is already in the System you can always retry additional computation.
Hence, we decouple Collectors from any additional Schema Validation or Enrichment of the Payload and move that down the stream.
You can scale collectors independently so they are able to take any Incoming Data Amount.
Collectors should also implement a buffer. If Kafka or other downstream Streaming System starts misbehaving - Data would be buffered in memory for some time until the Cluster recovers.
Data Output by the Collectors is your Raw Source of Truth Data. You will not be able to acquire this Data again - you want Raw data to be treated differently, i.e. have a longer lifecycle and most likely archive it in a low cost object storage. This Data should not be manipulated in any way, that is a task for Downstream Systems.
When does it make sense to have a Collector microservice?
Your Data is in event/log form.
Your Data is composed of many different event types.
Your Data is not saved in backend databases. If it is - use Change Data Capture instead.
[Important]: You will only be able to use gRPC for events delivered from your Private Network. For Public Network you would use REST.
Technologies that we will be learning at this step.
Kubernetes and Docker.
Python.
Kafka.
REST, gRPC.
Enricher/Validator.
Let’s go down the stream.
We build on the following:
Data reaching the Data System created by Data Producers is validated for top level fields, these include at least:
Event Type.
Schema Version.
Payload - the actual data of interest for analysis purposes.
Collected Data has been pushed to a Raw Events Kafka Topic.
There are multiple parts that make up ecosystem of the Enricher/Validator, let’s take a closer look:

Schema of the events to be emitted by Data Producers are synced with a Schema Registry. This is very important to do before the new event type is started to be produced as if we would not do that first, all of the events would be invalidated and outputted to Dead Letter Topic.
Once it is Synched, a new version of Data Producer can be deployed and new event types produced.
Enricher/Validator is continuously caching all of the schemas. It has to be always in sync with the Schema Registry.
Enricher/Validator reads Data from Raw Events Kafka Topic in real time as the data is written.
Combination of an Event Type and Schema Version defines what schema the Payload should be validated against.
If the Payload does not conform to the expected Schema - the Event is emitted to Invalidated Events Kafka Topic for further processing and recovery.
Validated Events are further enriched with additional Data, it could be:
An in memory Lookup Table.
Enrichment API Service (Could be a ML Inference API).
…
Validated and Enriched Data is pushed to Enriched Events Kafka Topic for downstream processing.
General notes:
Schemas must be synced with Enricher/Validator before they are deployed to the Data Producers. If not - the produced event will be invalidated.
Enrichment could also fail - it is a good idea to have a separate Kafka Dead Letter Topic to send these failed events for further processing.
You don’t want to have too much retry logic in Enrichers/Validators as it would slow down and potentially bottleneck the pipeline. A good idea is to have a separate stream for retry purposes if few retries fail.
Technologies that we will be learning at this step.
Kubernetes and Docker.
Python.
Flink.
Enrichment/Machine Learning API.
While this piece of the infrastructure can perform any type of enrichment let’s focus on enrichment of the events with Machine Learning Inference results.
What are the two ways you will find Machine Learning Inference Implemented in Streaming Applications in the real world?
Embedded Pattern where ML Model is embedded into the Streaming Application itself.
While Data is continuously piped through your Streaming Data Pipelines, an application (e.g. implemented in Flink) with a loaded model continuously applies inference.
Additional features are retrieved from a Real Time Feature Store Serving API.
Inference results are passed to Inference Results Stream.
Optionally, Inference Results are piped to a low latency storage like ElasticSearch in our case and are retrieved for serving from there.
Pros:
Extremely fast - data does not leave the Streaming application when Inference is applied.
Easy to manage security - data only traverses a single application.
Cons:
Hard to Test multiple versions of ML Models. The Streaming app is a consumer group so to have multiple versions of ML Model you will have multiple consumer groups reading the entire stream or have multiple ML models loaded into memory and implement intelligent routing inside of the application.
Complicated collaboration patterns when it comes to multiple people working on the same ML project.

Enricher Pattern where Streaming Application uses a decoupled ML Service to enrich the Streamed data.
Data from Streaming Storage is consumed by an Enricher Application.
Enricher Application calls the ML Service exposed via gRPC or REST and enriches the Streaming Payload with Inference Results.
Additional features are retrieved by the ML Service from a Real Time Feature Store Serving API.
Enricher passes the payload enriched with Inference Results to the Inference Results Stream.
Optionally, Inference Results are piped to a low latency storage like ElasticSearch in our case and are retrieved for serving from there.
Pros:
Flexible when it comes to deployment of multiple versions of ML Model. (e.g. implement routing per partition in keyed Kafka Topic - events with a certain key will always go to a specific version of ML Service).
Easy to release new versions of the model - Streaming Application does not need to be restarted.
The service can be consumed by other applications.
Cons:
Network jumps will increase latency.
Microservices are complicated to trace.
In the Template we will focus on the second - Enricher Pattern.
Technologies that we will be learning at this step.
Kubernetes and Docker.
Python.
REST and gRPC.
ML Service Deployment.
Real Time and Batch Loaders.
These applications do nothing more than transport data from Streaming Storage to either a Real Time or Batch storage. All three applications are separate consumer groups (find more about consumer groups here) consuming from a specific Stream/Topic.
Real Time (Invalidated) Loader loads data from Invalidated Events Topic to a dedicated Elasticsearch index in real time. Why do we need this data? This is the place where we will be able to easily aggregate and group data that is faulty (e.g. does not meet Data Contract) and alert on it as soon as faults are detected.
Real Time (Validated) Loader loads data from Enriched Events Topic to a dedicated Elasticsearch index in real time. This data will be used for real time analytics either via Kibana or Superset.
Batch Loader loads data from Enriched Events Topic to Enriched Events Bucket for downstream data processing in the Batch Pipeline. The loading procedure here works in non real time fashion. Each consumer in a consumer group reads data and buffers it in memory. When a specific size or time threshold for a given buffer is reached, the data is then serialised (usually and in the case of this template into a parquet format) and compressed before writing it to the object storage.

Technologies that we will be learning at this step.
Kubernetes and Docker.
Python.
Spark and Flink.
MinIO.
Elasticsearch.
Batch Pipeline.
Batch Pipeline is the natural step in Data Engineering following the upstream data preparation. Data is in the object storage ready to be cleaned and modeled. The following steps compose the process:
Deduplicate the data. Why is this needed? When performing batch data loading from Streaming Systems, some event duplication is bound to happen due to streaming application failures.
Checking for Data Quality and profiling the data with frameworks like Great Expectations.
Transforming the data to a specific data model for easier consumption in downstream systems.

Data processing jobs will be scheduled via Airflow, this will also be a good place to test other pipeline orchestrators and evaluate them against each other.
Technologies that we will be learning at this step.
Kubernetes and Docker.
Python.
Spark.
MinIO.
Airflow and other orchestrators.
Great Expectations.
DBT.
Trino (Presto).
Closing Thoughts.
After implementing the template:
You will learn most of the Data Manipulation and Transportation patterns.
You will learn Kubernetes and how to leverage it as a Data Engineer.
You will learn the intricacies of frameworks like Spark, Flink, DBT, Airflow etc.
You will learn how to deploy Machine Learning Models as a Real Time API.
Any type of data can be ingested via this template as the producer can transform both batch and real time data to an event stream to be pushed to the collector. Having said that, it is completely fine to skip the Collector application and push the data directly to Kafka.
That is it for today's Newsletter. Hope to see you in the next one!