
Evolving Maturity of MLOps Stack in your Organisation.
And why less is sometimes better.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
MLOps brings to Machine Learning what DevOps did to Software Engineering. Today I will lay down my thoughts around the process of evolving MLOps maturity in organisations. This time the focus will be on the technical and process rather than organisational side (you can find more of my thoughts around effective organisational structures for MLOps implementation here).
There have been many articles written about the maturity levels of MLOps, the most popular ones have been by GCP and Azure. While the articles bring a lot of clarity to the processes, they do leave the reader with the belief that extremely complicated final levels of maturity in MLOps is necessary to succeed at Machine Learning (this is to be expected as the platforms provide consultancy and end-to-end platforms to achieve the said maturity hence benefiting from it).
I have been involved in the evolution of Machine Learning processes in companies of different sizes, starting from a startup with a team of 5 people, moving on to a scale-up with hundreds of engineers and eventually corporations with thousands of employees. Today, I want to take a more simple approach and look into the evolution of maturity in MLOps from my own point of view and experience.
Let’s move on.
The Beginning of Machine Learning Journey.
I have been part of multiple initiatives of trying to bring Machine Learning into a product from the very early stages. The story is simple and will usually take one of two directions: you are hired into an organisation as a Data Scientist or Machine Learning Engineer and tasked with finding problems that could be solved leveraging ML or to solve a specific business problem the management decided to be of importance to be solved.
The System is very simple and lacks any kind of automation. This is what you would see in most organisations that are just starting with running ML in Production.
No MLOps processes are in place and for a good reason: while MLOps practices bring a lot of benefits, they also slow down progression of small projects that do not have need for them.

In this article I assume that Data Engineering pipelines are already in place. What does that mean?
Raw data from external sources is ingested into either Data Warehouse or Data Lake.
The Data has been curated and the quality of it ensured in a curated data layer. Data exposed via data marts in case of a Data Warehouse or golden datasets in case of Data Lake. Both, Raw Data and Curated Data is available for a Data Scientist to explore.
Before even thinking about MLOps, Data Scientist works in the Experimentation environment analysing (4.) Raw and Curated data and running basic Machine Learning Training pipelines (5.) ad-hoc. In this article, for visual simplicity, in the diagrams I use a very basic ML Training pipeline: Preprocessing -> Model Training -> Model Validation. In the real world scenarios these pipelines can and will become a lot more complicated, there would most likely be branching, additional quality gates and training of multiple models at once conditionally on some variables.
At this stage no model handover happens yet as the viability of ML to solve a business problem has to be proven offline first. Once that has been done, we move to the next stage.
Some thoughts:
It is good to start like this as the prototyping velocity is huge.
Don’t overthink the experimentation environment, use tools you are comfortable with.
Don’t do big data yet, use samples of data for the first prototypes.
Don’t focus on moving Raw Data to the Curated layer if you find useful features in Raw Data - it will take time and slow down the process.
Ready for Deployment.
Once we have proven that ML model can have meaningful impact when benchmarked against some heuristics offline, we are ready to hand it over for deployment.

Model handover step follows the evaluation and validation of model results offline.
At this stage of MLOps maturity a handover is usually what we call “throwing the model over the wall”. It can be done in the form of writing the model binary to a s3 bucket and leaving the remaining deployment work to a Software engineer.
The said SE takes care of model deployment, different deployment types will require different procedures.
The model gets deployed using one of the deployment types: Batch, Stream, Real Time or Embedded.
Model inference results are exposed to Product Applications that are also handled by the SE.
At this stage we are usually using an already existing non ML focused Software Platform for deployment purposes.
Some thoughts:
Try leveraging an already existing Software deployment stack for as long as it makes sense.
Introducing a new ML specific stack will require dedicated resources, the burden usually falling on the ML team itself reducing the development velocity significantly.
Usually at this stage feature processing logic on the inference side will be implemented inside of the deployed ML Model application - make sure to over communicate with the SE to make sure of the calculation correctness.
Make sure that you have a version of Software running on heuristics instead of being powered by ML Model - it will act as a baseline for Online testing for business metrics.
Let’s start breaking the wall down.
Enter ML Metadata Store.
The next step that I would suggest and have seen introduced with little effort is the Machine Learning Metadata Store.

ML Metadata store sits in between experimentation environment and Model Deployment stages and is comprised of two integrated pieces:
Experiment Tracker - you store metadata about the Model training process, it would include:
Datasets used for Training, Train/Test splits, important metrics that relate to Datasets - Feature Distribution etc.
Model Parameters (e.g. model type, hyperparameters) together with Model Performance Metrics.
Model Artifact location.
Machine Learning Pipeline is an Artifact itself - track information about who and when triggered it. Pipeline ID etc.
Code - you should version and track it.
…
Model Registry - you store your model binaries here and expose them to the downstream systems. Model Registry should allow for lifecycle management of your models (e.g. staging and production tagging capability).
Once it is time for deployment, Software Engineer sources model binaries to be deployed directly from the Model Registry part of ML Metadata Store.
Some thoughts:
You will often see ML Metadata Store only appear in later stages of MLOps maturity, I would suggest to start with it sooner rather than later as the solutions are usually very lightweight and non-intrusive when it comes to additional codebase.
Being able to track experiments early is important if you want to understand and get back to successful experiments in the future as the system evolves.
ML Metadata Store continues to become more important as the company and ML function grows as it is the place where you will be collaborating on different experiments with your colleagues. This is also where you will be enabled to perform effective experiment debugging.
Automating Model Delivery.
The next step in evolving MLOps maturity I’ve seen work naturally is minimising involvement of Software Engineers in the deployment process by automating model deployment via a trigger.

CI/CD Pipeline for model deployment is triggered either by a step in ML Training pipeline after the artifact handover or by a web-hook fired by the Model Registry after a Model Lifecycle State change.
After regular CI/CD steps the model is deployed to serve Product Applications. Usually, there will be no tests specific to ML yet, this prevents full automation and keeps the need for SE to keep being involved in deployment processes.
Some thoughts:
It might be scary to automate this step, but we are only doing Continuous Delivery here, not Deployment. This means that there would need to be an additional approval after the CI/CD process succeeds.
By introducing this automation we also move one step forward to removing unnecessary handovers between teams and functions inside of an organisation.
Automated ML Training Pipelines and Continuous Training.
Only at this stage I would bring in the automated training pipelines and orchestrators. Popular Pipeline orchestrators include Airflow, Kubeflow, Metaflow and similar.

With most of the modern ML Pipeline orchestrators you will be able to define the Pipelines in code, most likely Python. This allows for Pipeline versioning via Code Repositories.
Sync code repository holding Pipeline code with an environment in which automated pipelines will be running.
Orchestrator triggers pipeline either ad-hoc or on a schedule. It is very likely that every time there is a change to pipeline definition you would want to re-trigger it as well.
Data for both the Experimentation environment and the Automated Pipeline should be sourced from the same data store.
Models are handed over only from the automated pipelines.
Some thoughts:

It is easier to achieve continuous training than it could initially look, the above setup already enables it. Having said this, there are additional requirements for the pipeline to be safe to use in continuous training. These include things like:
Data is validated before training the Model. If inconsistencies are found - the Pipeline is aborted.
Short circuits of the Pipeline allow for safe CT in production.
CI/CD for ML Training Pipelines.
Next step is starting to treat ML Training pipelines as a first class citizen of the Software world.
ML Training pipeline is an artifact produced by Machine Learning project and should be treated in the CI/CD pipelines as such.

Regular CI/CD pipelines will usually be composed of at-least three main steps. These are:
Step 1: Unit Tests - you test your code so that the functions and methods produce desired results for a set of predefined inputs.
Step 2: Integration Tests - you test specific pieces of the code for ability to integrate with systems outside the boundaries of your code (e.g. databases) and between the pieces of the code itself.
Step 3: Delivery - you deliver the produced artifact to a pre-prod or prod environment depending on which stage of GitFlow you are in.
What does it look like when ML Training pipelines are involved?
Let’s zoom in:
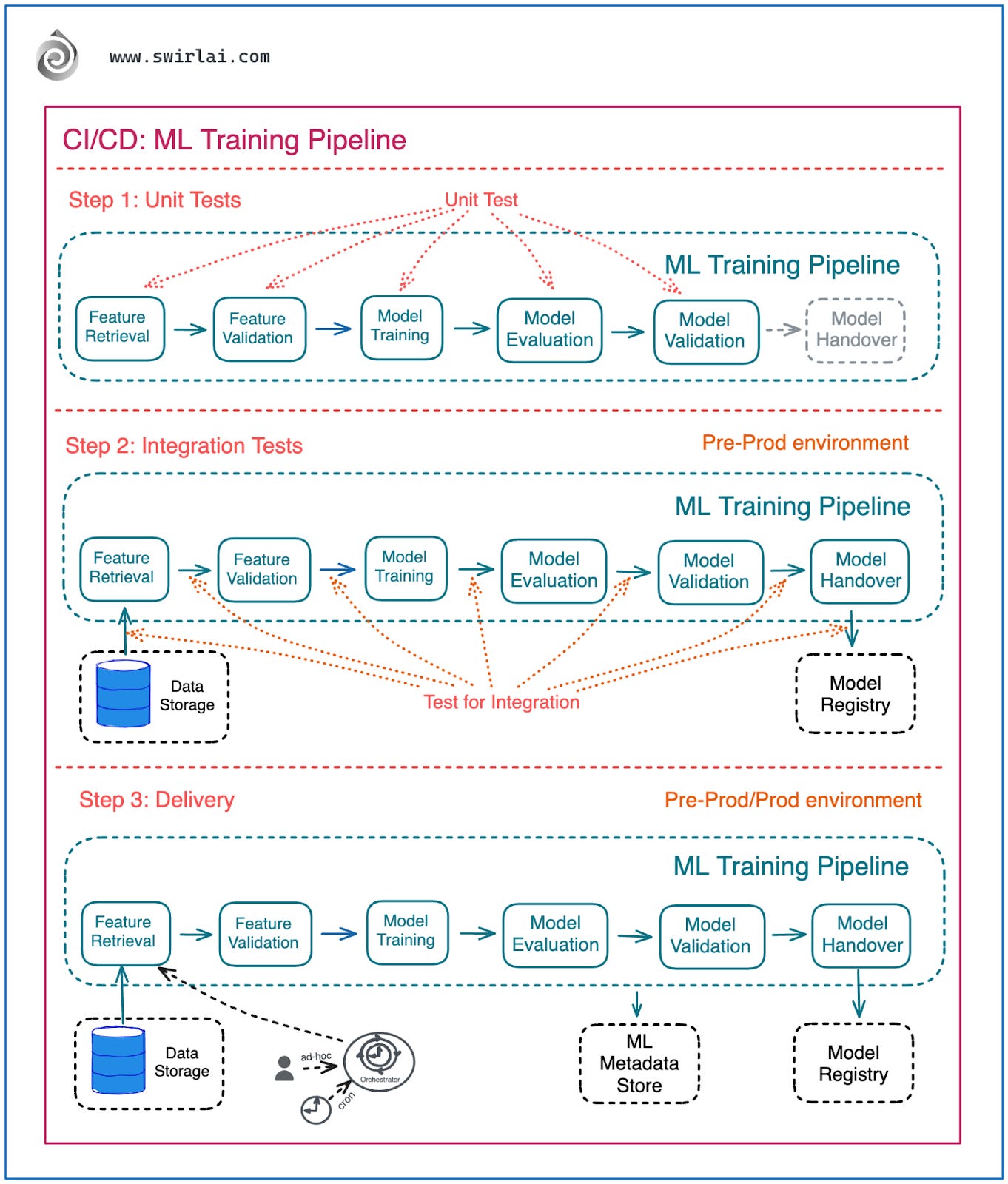
Step 1: Unit Tests - in mature MLOps setup the steps in ML Training pipeline should be contained in their own environments and Unit Testable separately as these are just pieces of code composed of methods and functions.
Step 2: Integration Tests - you test if ML Training pipeline can successfully integrate with outside systems, this includes connecting to a Feature Store and extracting data from it, ability to hand over the ML Model artifact to the Model Registry, ability to log metadata to ML Metadata Store etc. This CI/CD step also includes testing the integration between each of the Machine Learning Training pipeline steps, e.g. does it succeed in passing validation data from training step to evaluation step.
Step 3: Delivery - the pipeline is delivered to a pre-prod or prod environment depending on which stage of GitFlow you are in. If it is a production environment, the pipeline is ready to be used for Continuous Training. You can trigger the training or retraining of your ML Model ad-hoc, periodically or if the deployed model starts showing signs of Feature/Concept Drift.
Some thoughts:
This is one of the most complicated steps to achieve efficiently.
Introduction of CI/CD for ML Pipelines increases the time to deploy any change to the Model significantly.
I would suggest to introduce this step only when you have started to normalise how multiple teams are delivering ML Products to production.
You will definitely need ML Platform team to support the efforts from here on.
Breaking the remainder of The Wall: CD for Model Deployment.
In order to achieve full ownership of ML System inside of a ML Team we introduce:
Continuous Delivery for Machine Learning Model. This is when we add to the already existing Model Deployment Pipeline specific tests that only make sense for Machine Learning applications to ensure that we are releasing securely.

Some thoughts:
This is also where we are very likely to start deploying ML models via a specialised framework like Seldon Core, KFServe or TFServing.
Machine Learning Real Time Monitoring.
I put ML Monitoring to almost the very end of the MLOps maturity journey. I do so based on my own experience and what I hear from industry professionals that are actually doing ML in production and not selling services that help with monitoring.
It is important to note, that by ML Monitoring I mean ML specific metrics and these mostly include Feature and Model Drifts. Regular system metrics (e.g. latency, error rates etc.) and Online Business metric tests (via A/B testing, interleaving experiments etc.) will already be provided by the regular Software deployment systems.
Why so far in the list?
I have seen time and time again that it is unreasonably expensive to implement a robust monitoring system. Usually what is enough to prevent data drifts is regular retraining of your models, which can be achieved with Continuous Training capabilities. Also, it is possible to detect and predict future drifts by analysing Feature distributions while performing model training.
Having said this, you achieve this stage by:

Introducing a Monitoring System that collects data from Machine Learning Services in real time. Data collected would include features being fed to ML Models and Inference results being produced. This data would be batched and analysed in real time to detect any possible Data Drifts. Such capability would also allow the system to react in real time and trigger Model retraining given any detected anomalies.
Some thoughts:
Don’t rush with automated retraining. I have never seen this implemented in action, ad-hoc or on schedule will almost always do the trick.
Feature Store (Optional).
Final and optional piece of the MLOps stack is a Feature Store. You can read more about Feature stores and when you need one here.
Here is a short summary:
Feature Stores sit between Data Engineering and Machine Learning Pipelines and it solves the following issues:
Eliminates Training/Serving skew by syncing Batch and Online Serving Storages.
Enables Feature Sharing and Discoverability through the Metadata Layer - you define the Feature Transformations once, enable discoverability through the Feature Catalog and then serve Feature Sets for training and inference purposes through unified interface.

Some thoughts:
While I mentioned Feature Stores at the very end of the article, I have seen them solve numerous problems that were caused by delaying introduction of it.
Not all use cases require a Feature Store. E.g. Some cases benefit from feature calculation on the fly when performing inference.
Feature Stores are a complicated and heavy infrastructure element to be introduced to your MLOps stack so the decision to do it should be treated with care.
Closing Thoughts.
Cloud Providers and Consultancies will push you to achieve the highest Level of MLOps maturity because it will make them money. Know when it makes sense to stop for your organisation and use case.
You can achieve Continuous Training relatively early in MLOps maturity journey.
If you are yet to prove Machine Learning worth in your organisation, forget about MLOps and rather move quickly with the first prototype.
That is it for today's Newsletter, if you found it useful - share it with your friends. Hope to see you in the next one!
A brilliant overview over the evolution of the MLOps