
Levels of Data Freshness in Machine Learning Systems
And what is needed to move between levels.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
Most of the online sources will advocate for trying to achieve the highest level of data freshness possible, which means minimising the time from data generation to serving it to the end user. And this is no surprise, the articles are usually written by the companies that help with Data Freshness. While there is no doubt of the value of fresh data, it does not come without cost. In my career I had been a victim of my own geekiness and ambition multiple times, while leading projects I would choose to advocate for over engineered solutions resulting in less optimal ROI. In this article I will outline observations that I made over the years on Data Freshness in Machine Learning Systems and hopefully it will help some of the readers make better decisions when architecting their own ML Systems.
I will cover the following topics:
What is Data Freshness and why is it important?
Data Freshness in Machine Learning Systems (Feature Freshness).
Levels of Feature Freshness in Machine Learning Systems.
Moving between the levels.
Complexities introduced with each new level.
Data Freshness.
In most general terms, Data Freshness is the amount of time needed for a data point after being generated by Data Producers to be available for consumption in analytical systems by Data Consumers. A relative term to Data Freshness is Data Latency.
Data Latency refers to the time difference between when the data was generated until it was made available in core data stores like Data Warehouses or Data Lakes.
Once the data is available in the core data store it is not necessarily automatically exposed to the data consumers. You might still need to expose it to BI Reporting tools or Reverse ETL systems. Our focus today is on Machine Learning Systems that are by themselves a Data Consumer of the Data Engineering System.

Why is Data Freshness important?
Value of data reduces over time.
Stale data applied in production might damage your business.
Near to Real Time data unlocks new use cases.
Ability to react quickly on recent data gives you a competitive advantage.
Fresh data builds trust.
Having said this, there are multiple cases where certain levels of data staleness is fully acceptable:
Weekly/daily management reports can be delivered with delays of several hours after the day closes with no severe impact.
Sending a promotional email to the user with high probability of churn estimated on yesterday's next day afternoon via a daily batch is usually good enough.
…
Data Freshness in Machine Learning Systems.
When it comes to Machine Learning Systems, we usually plug in on top of Data Engineering Systems where data is already collected, transformed and curated for efficient usage in downstream systems - ML System is just one of them. This does not mean however that no additional data transformations need to happen after data is handed over. We refer to Data Freshness in Machine Learning Systems as Feature Freshness.
When thinking about composition of how data is served to the end user in ML Systems there are two mostly independent pieces, hence also two perspectives on Feature Freshness:

Feature Freshness at Model Training time: how much time does it take for a generated data point to be included when training a Machine Learning Model which is then deployed to serve the end user. Remember that Machine Learning models are nothing more than Statistical models trained to predict certain outcomes on a given feature distribution. We can’t avoid ML Models becoming stale if not retrained. This phenomenon of ML models becoming stale is called Feature and Concept Drift (you can read more about them here).
Feature Freshness at inference time: how much time does it take for a generated data point to be available when performing Inference with the previously trained and deployed model. Features used for inference are usually decoupled in terms of freshness from the ones that are used while training the model and are less stale.
Both types of Feature freshness add on top of Data Freshness introduced by the Data Engineering system.
Levels of Feature Freshness in Machine Learning Systems.
In this article I want to outline different levels of feature freshness you could achieve in your ML Systems that I have observed in the industry. I will also discuss investments you would need to make and complexities in the system that would be introduced.
To make arguments grounded, the ROI (return on investment) of moving between two levels (i - 1) and i of feature freshness can be calculated as:
ROI(i-1) -> i = [ Additional revenue generated by moving level (i - 1) to level i ] - [ Cost of moving from level (i - 1) to level i ]
Additional revenue generated can be estimated using Online Testing techniques like A/B testing (you can find out more about it here), infrastructure costs can be calculated relatively precisely before you start the project.
Level 1 - Offline Training and Batch Inference.
Machine Learning is only generating value once it is deployed to production. If your organization has no models deployed yet, you should start with as little infrastructure investment as possible. This kind of thinking has at least three benefits:
You will be able to test if Machine Learning actually adds additional business value to the baseline, and you will be able to do it fast.
You will not spend substantial amounts of cash on setting up infrastructure. If there is no added value from Machine Learning, there would also be less losses when scraping the project.
If you prove any added value of Machine Learning, you will be able to iterate on both - new versions of Machine Learning Models and infrastructure improvements (Feature Freshness) - at the same time.
Let's look at the simplest setup possible - the first level of Feature Freshness.

For model training we use Offline Features from a Data Warehouse.
Machine Learning Models are trained manually or on a schedule.
Batch Inference is applied on the new incoming Features on a schedule.
Inference results are uploaded to an Online Prediction Store. E.g. Redis could be used here.
Product Applications source predictions from the Prediction Store.
New Features generated by the Product Applications are piped back to the DWH. Important: Data has to traverse the entire Data Engineering Pipeline before it reaches ML System.
Feature Freshness.
Feature Freshness at Model Training time
If we retrain our models every time the data in DWH is refreshed, Feature Freshness would be equal to Data Freshness of Data Engineering system with addition of the Batch Inference schedule as a new model would be used for each Inference Batch. Usually, the flow would be: Train a model -> Use the model to predict.
If we retrain only once in a while and do not tie the schedule to when refresh of data in the DWH happens, the Feature Freshness at Model Training Time would deteriorate continuously until we do eventually retrain.
Feature Freshness at inference time
Usually, inference would be performed each time the data is refreshed in the DWH which would mean that Feature Freshness at inference time would be equal to the freshness of the Data Engineering system with an addition of the time it takes to perform inference on new data.
Additional Investment
Investment in deploying ML Models in such a way is minimal for several reasons.
Production applications serving the end user would already be developed and most likely sourcing some data for the business logic from some sort of Online Database. The only switch from this perspective is pointing to the Prediction Store.
Training and Inference Pipelines can be easily owned by Data Scientists as applying inference on a schedule and uploading results to a prediction store does not require substantial effort.
The Pipelines for moving Feature data from Product Applications to ML System for further retraining will most likely be already in place as you had to gather initial data to train your models in the first place (given that you are trying to introduce Machine Learning in an attempt to improve an already existing process).
Level 2 - Offline Training and Real-Time Inference with Static Features.
Level 2 of the Feature Freshness is achieved by the following.

Data Warehouse is replaced by a Feature Store which is used for retrieving offline features for Model Training and Feature Serving in Real Time.
Machine Learning Models are trained manually or on a schedule.
Instead of applying inference in Batch on a schedule we deploy Machine Learning model as part of a Real-Time service.
Inference results are requested from Product Application in real time. ML service uses a real time feature serving API exposed by the Feature Store.
New Features generated by the Product Applications are piped back to the Feature Store for future Model Training.
Important: in this setup we can only utilize static features that do not change frequently. E.g. dimensional properties of an item like item colour or similar. We will not be able to use aggregated features derived from e.g. user session attributes like number of views in the last minute (we could introduce Real Time feature computation as part of the Product Application but it would act only on single data points like extracting a piece of information from a useragent).
Feature Freshness.
Feature Freshness at Model Training time
We do not gain any improvements on Feature Freshness compared to level 1 as the process of model training is almost the same.
Feature Freshness at inference time
We improve Feature Freshness at inference time compared to level 1 by removing the need to calculate inference results in batch.
Investment
Investment in such an architecture compared to level 1 is twofold:
Since models are now deployed as a Real-Time Services, you will need to take care of the entire CI/CD suite for robust releases. This includes the ability to monitor predictions made by the service - compared to level 1 where we could perform most of the needed tests after the predictions were made in batch.
Introduction of a Feature Store (it could be of different forms) is almost mandatory at this stage as it will prevent any avoidable Training Serving Skews. Worth to note that at this point in time it could be a Feature Logic Store that only stores processing logic that could be applied on the server side and not necessarily a physical Feature Store.
Required Feature Store capabilities at this stage:
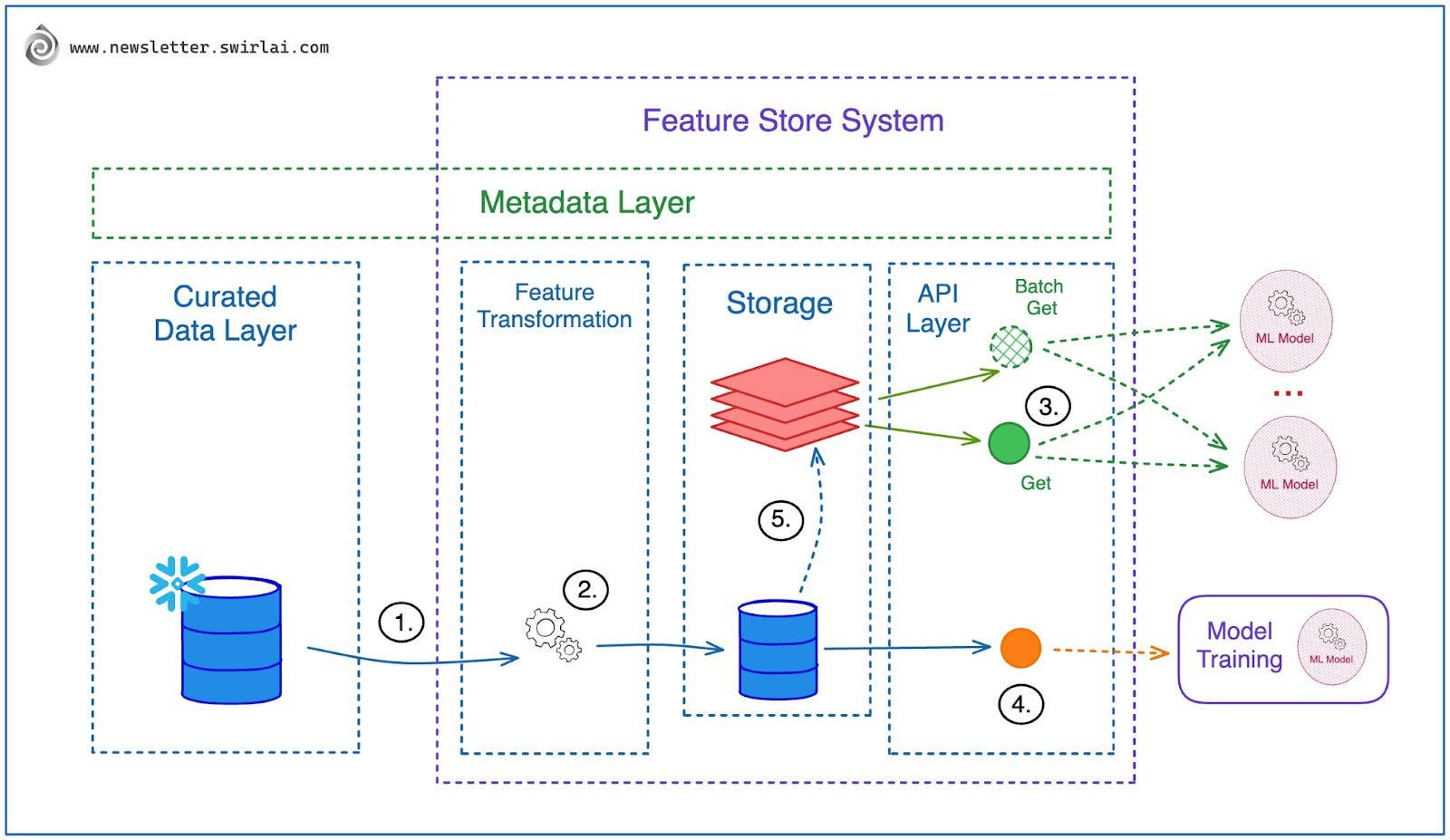
It should be mounted on top of the Curated Data Layer in your Data Warehouse or Data Lake.
Feature Transformation Layer where Data Scientists could work on additional logic. It can be part of the Feature Store offering or managed in house.
Real Time Feature Serving API - this is where you will be retrieving Features for low latency inference. The System should provide two types of APIs:
Get - you fetch a single Feature Vector.
Batch Get - you fetch multiple Feature Vectors at the same time with Low Latency.
Batch Feature Serving API - this is where you fetch Features for Batch inference and Model Training. The API should provide:
Point in time Feature Retrieval - you need to be able to time travel. A Feature view fetched for a certain timestamp should always return its state at that point in time.
Point in time Joins - you should be able to combine several feature sets in a specific point in time easily.
Feature Sync - after ingesting the data into offline storage, the Data being Served for Real Time inference should always be synced. Implementation can vary.
Additional observations on Level 2.
In my opinion and observations from the industry, the largest investment at this stage is in the Feature Store as it is not an easy system to craft in house (at least in a UX friendly way when the user is a Data Scientist). There are multiple commercial offerings like Tecton and FeatureForm. However, you should expect the cost to be calculated into the price you will be paying for it.
With the current state of the industry companies will very rarely move beyond level 2 unless the use case has a hard requirement on it.
Level 3 - Offline Training and Real-Time Inference with Dynamic Near to Real-Time Features.
This is a Feature Freshness level I’ve seen tried to be implemented too soon on numerous occasions. The selling point is usually the access to dynamic features in Near to Real Time. A good example would be a recommender system for an online store. You start off by using Features like properties of an item - it’s color, price, location etc. - combined with features of the user browsing your site - device type, location, how long is the user registered on the platform etc. As time goes Data Scientists start exploring more complex, dynamic features that are available in the Data Warehouse, things like distinct items viewed in the last 1 minute and similar. The problem is that these kinds of features are not available to be used in online Real Time Inference services while the user is browsing the website.
Having said that, there are some industries and use cases where having anything below level 2 would not be enough. These include cases like Fraud Detection, Hardware Fault Prevention and similar where having access to Near Real Time aggregated Features is a must.
Level 3 of the Feature Freshness is achieved by architecture similar to the following.

Steps 1 - 5 are no different from level 2.
A new Real Time data curation and preprocessing step is introduced. Instead of loading the data into the Feature store from a Data Warehouse, a real time Streaming Storage is used.
Feature Freshness.
Feature Freshness at Model Training time
We do not gain any improvements on Feature Freshness compared to level 1 or 2 as the process of model training is almost the same - we train on demand or on a schedule. The important difference is that if out Feature Set is entirely made of Dynamic Real Time Features, we are no longer bound to when data is refreshed in the Data Warehouse or a Feature Store and the Retraining an happen at any point in time.
Feature Freshness at inference time
The changes needed to achieve level 3 are mostly on Data Engineering System Level as the data has to be curated and transformed in Real Time before it reaches the Feature Store. Hence, we gain both on Data Freshness and combined Feature Freshness fronts.
Investment
There are two large investments that need to be made to move to level 3:
Data generated by Product Applications that is needed for training models and inference has to be curated and transformed in Real Time via a Stream Processing framework (e.g. Flink). While it might sound like an easy feat (just a simple Stream Processing application mounted on top of a streaming storage) the real issues start when either Streaming Pipeline breaks or you need to do a change in the application logic and then need to backfill the historical results.
Additional required Feature Store capabilities.
Additional Feature Store capabilities required for this level:

It should be mounted on top of the Curated Data Layer in your Stream Processing System.
Feature Transformation Layer where Data Scientists could work on additional logic. It can be part of the Feature Store offering or managed in house. If you plan to manage it in house - be sure that your ML Engineers are capable of writing Stream Processing applications. If you plan to buy the capability in a SaaS offering, be prepared to pay large amounts for it.
Feature Sync - after ingesting the features in Real Time, the Data being Served for offline Model Training should be CDCd to offline storage. The Store should provide a join in time capability, which should allow querying feature states that have been observed in online storage at any point in time.
Level 4 - Online Training and Real-Time Inference with Dynamic Near to Real-Time Features.
The final level is a new kid on the block. People are only starting to talk about Online Model Training and it is an extremely hard problem to solve. It is worth mentioning that it makes no sense talking about level 4 if level 3 is not yet achieved as we need Near to Real Time features continuously available. The high level architecture is as follows:
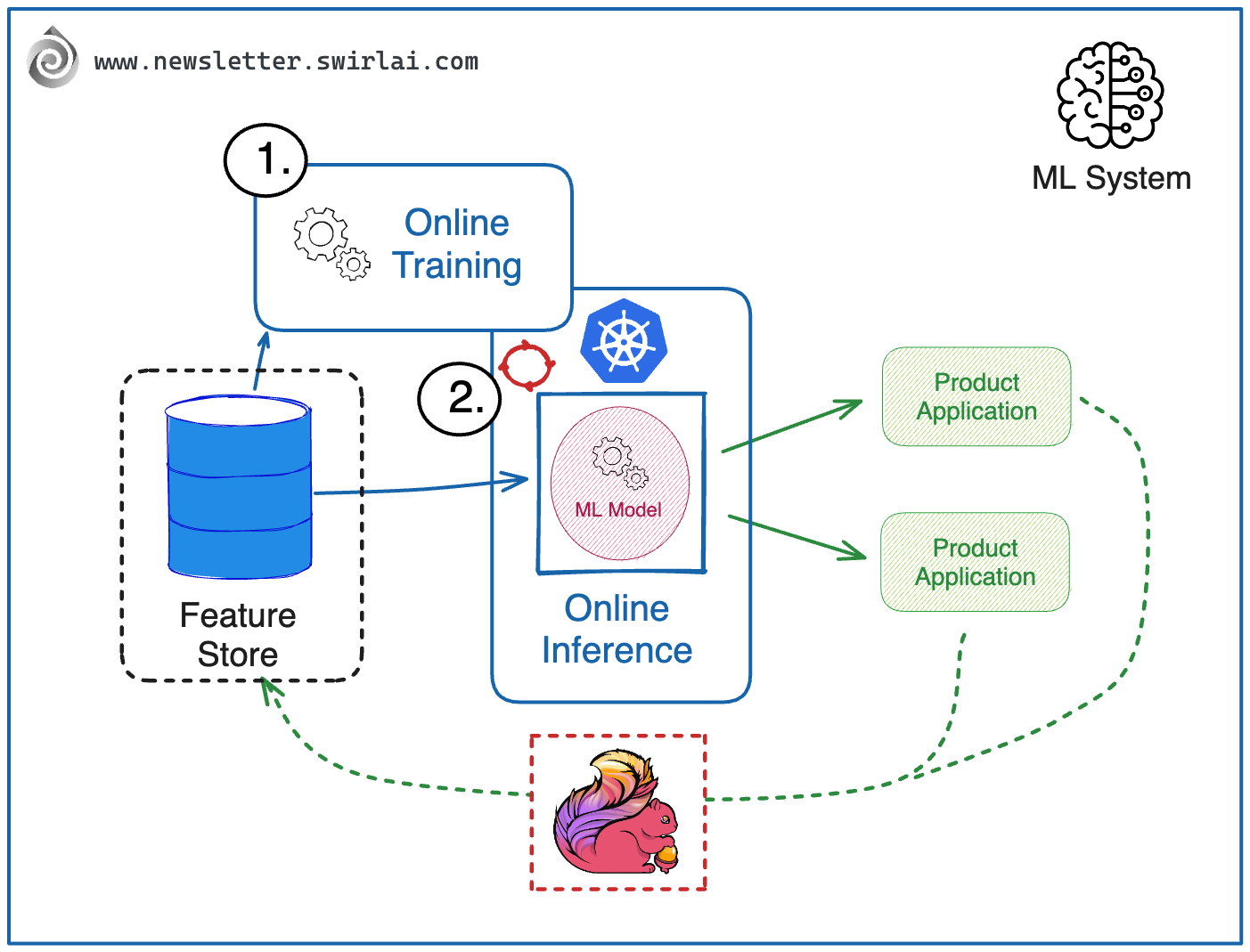
All of the moving parts from level 3 are present, the difference is in model training and deployment.
Online Model Training is introduced. Models are continuously trained on Data coming in Near to Real Time. A good example would be a Deep Learning model whose weights are continuously fine-tuned with new incoming data.
After ML Models are trained on a small batch of data, new versions are continuously deployed to production after ensuring stability and correctness.
Feature Freshness.
Feature Freshness at Model Training time
Models are continuously trained and deployed on new incoming data. Near to Real Time Feature Freshness is achieved.
Feature Freshness at inference time
Features that are used for inference purposes are all coming in Near to Real Time.
Investment
For now it is unclear, there are not many publicly known systems that have achieved Online Training. But given the complexities involved, the system would be extremely expensive if we tried to make it robust.
Closing Thoughts.
Always start with as little complexity in your ML System as possible.
Stick with Level 2 for as long as you can unless data shows otherwise.
If you are buying Feature Freshness capability, be prepared to pay for it accordingly.
If the end user of your ML System is internal to the company, always make sure that the current Feature Freshness level is not enough before trying to level up.