
SAI Notes #09: Database Sharding.
And implementation architectures.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in Data Engineering, MLOps, Machine Learning and overall Data space.
Today in the Newsletter.
Episodes you might have missed this month.
Spark Optimisation guide (Part 2) coming out next Wednesday.
Database Sharding Explained.
Vertical vs. Horizontal scaling.
Database Sharding.
Different ways of implementing Sharding.
Referrals for the Newsletter are now available (get complimentary paid subscription for free).
Episodes you might have missed this month.
I will be releasing Part 2 of the Guide to Optimising your Spark Application Performance next week, so stay tuned in! In the guide I plan to cover the following topics:
spark.default.parallelism vs. spark.sql.shuffle.partitions.
Choosing the right File Format.
Column-Based vs. Row-Based storage
Splittable vs. non-splittable files
Encoding in Parquet.
RLE (Run Length Encoding)
Dictionary Encoding
Combining RLE and Dictionary Encoding
Considering upstream data preparation for Spark Job input files.
What happens when you Sort in Spark?
Understanding and tuning Spark Executor Memory.
Maximising the number of executors for a given cluster.
Database Sharding Explained.
What is Database Sharding and when do we need it? Is it even important in ages of big data technologies that boast unparalleled horizontal scalability?
Usually, we run into the need of scaling our databases when the business we are operating succeeds and the number of customers grows resulting in more data being stored and consequently making both writes and reads from the database slower.
Database Sharding is one of horizontal database scaling techniques. Before digging into the ways of implementing it, let’s remind ourselves of horizontal and vertical scaling and what it means in terms of databases.
Database Management System (DBMS) is a suite of software elements that helps us manage data in more efficient ways on disk or in memory. In most simplest forms this software is confined in the boundaries of a single server where it is installed - compute, memory and storage resources are limited by the size of this single machine.
Vertical Scaling.
The easiest way to scale a DBMS is to add additional resources to the server it is running on, such a procedure is referred to as scaling the databases Vertically or Scaling Up. A simplified example would be the following: if you have your Database running on a m5.large EC2 instance on AWS, scale the server to e.g. m5.4xlarge size (it is rarely realistic that you would be running a database on such a small server though).

If you can get away with scaling your database vertically - do it, it is a lot simpler procedure than anything I will be describing next.
Database Sharding.
Compared to Vertical Scaling, Database Sharding is a Horizontal Scaling technique. The idea is very simple - instead of increasing the size of the server that hosts the DBMS, split the database into smaller chunks of data and spread them between multiple smaller machines. Some important terminology and implications:

Data is assigned to chunks using a specific rule derived from a user defined key.
These chunks are called Logical Shards.
Multiple Logical Shards can be assigned to a single server hosting a separate DBMS.
These Servers or Nodes are called Physical Shards.
Database schema is always the same between the Logical Shards.
In most of the cases the assignments of shards for written or queried data is implemented on the application layer.
Operations against Logical Shards are performed inside of the isolated decoupled servers, resulting in a shared-nothing architecture.
So what are the positives and negatives of such an architecture?
Positives:
The performance of each shard is increased, limited only by the Physical Shard resource amount.
You can scale almost limitlessly.
Negatives:
Introduced complexity on the application level.
Some operations might be hard to achieve, e.g. unless sharded according to a use case, aggregations on certain columns can be near to impossible or would also need to be done on application level by additionally aggregating partial results.
Keeping Shard schemas in sync when performing schema updates is complicated.
It is very easy to introduce data skew and hot.overloaded partitions if partition strategy is not well thought through.
Ways to Split Data Between Shards (partitioning strategies).
There are generally three main ways of how you could split the data between partitions discussed in the industry. Let’s look into all of them.
To reduce confusion, I want to emphasise that we are now talking about assigning data to Logical Partitions so we will not mention servers any more and focus on the rules generally used to chunk the data. Additionally, for simplicity reasons, I will use a single table for visualisation purposes, but there could be multiple tables in a database being partitioned at the same time.
For the examples I will use the following table.

Key Based Sharding.
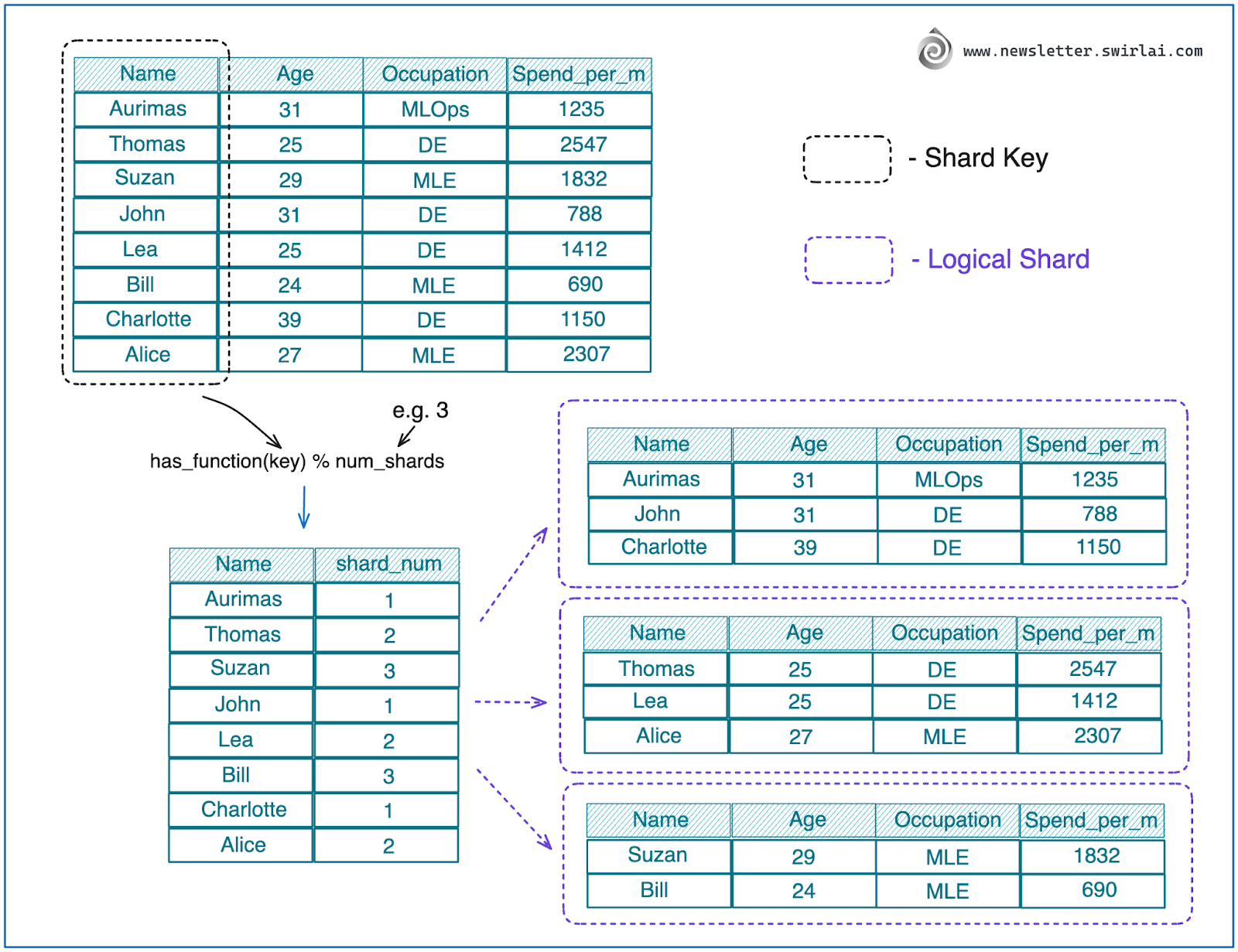
A technique used if you want to achieve balanced distribution of data between shards with least effort:
Choose a key from your table to be used as a shard key.
Hash the values using a chosen hash function.
Choose how many shards you want to have.
Apply modulo of the chosen number of shards on the resulting hash.
The resulting number is equal to the identifier of the shard either for write purposes or to know in which shard to look for the data.
Range Based Sharding.
A technique that uses value ranges to shard:
Choose a key from your table to be used as a shard key.
Create multiple ranges of values that you will be sharding by.
Number of ranges will be equal to the number of resulting shards.
Assign a row to a shard according to which range the shard key falls into.
There is a risk for data skew and hot shards since values rarely have an even distribution.

Directory Based Sharding.
A technique that uses predefined shards for specific partition key values:
Choose a key from your table to be used as a shard key.
Create a mapping table that maps specific values contained in shard key to a pre-specified shard.
Number of shards can’t be more than unique values in the shard key.
When writing or querying, map the key to a specific shard using the previously created mapping table.
There is the same as in Range Based Sharding - data skew and hot shards since values rarely have an even distribution.

Referrals for the Newsletter are now available.
You can now refer the SwirlAI Newsletter to your friends and by doing so earn complimentary paid subscriptions. Find out more here.