
State of Context Engineering in 2026
Five patterns for managing what goes into the context window, and when.

👋 I am Aurimas. I write the SwirlAI Newsletter with the goal of presenting complicated Data related concepts in a simple and easy-to-digest way. My mission is to help You UpSkill and keep You updated on the latest news in AI Engineering, Data Engineering, Machine Learning and overall Data space.
Context engineering has gone from a niche concern to the core discipline of AI engineering in under a year. In mid-2025, two posts laid much of the groundwork. Manus shared lessons from rebuilding their agent framework four times (July 2025). Anthropic followed with their guide on effective context engineering for agents (September 2025). That was eight months ago. The patterns they described have since matured and were adopted across platforms.
I previously wrote about the foundations of context engineering in one of my previous articles:

This piece focuses on what has changed since then, the patterns that have matured, and the tradeoffs you need to understand as an AI engineer.
Why Context Engineering Matters More Than Model Capability
The core insight is simple. LLMs have a finite attention budget. Every token in the context window competes for that attention. As context grows, precision drops, reasoning weakens, and the model starts missing information it should catch. Research calls this “lost-in-the-middle” and “needle in the haystack“ problems.
Anthropic frames it well: context engineering means finding the smallest possible set of high-signal tokens that maximise the likelihood of desired outcomes. The discipline covers everything that lands in the context window: system instructions, tool definitions, MCP resources, retrieved documents, conversation history, and accumulated action history.
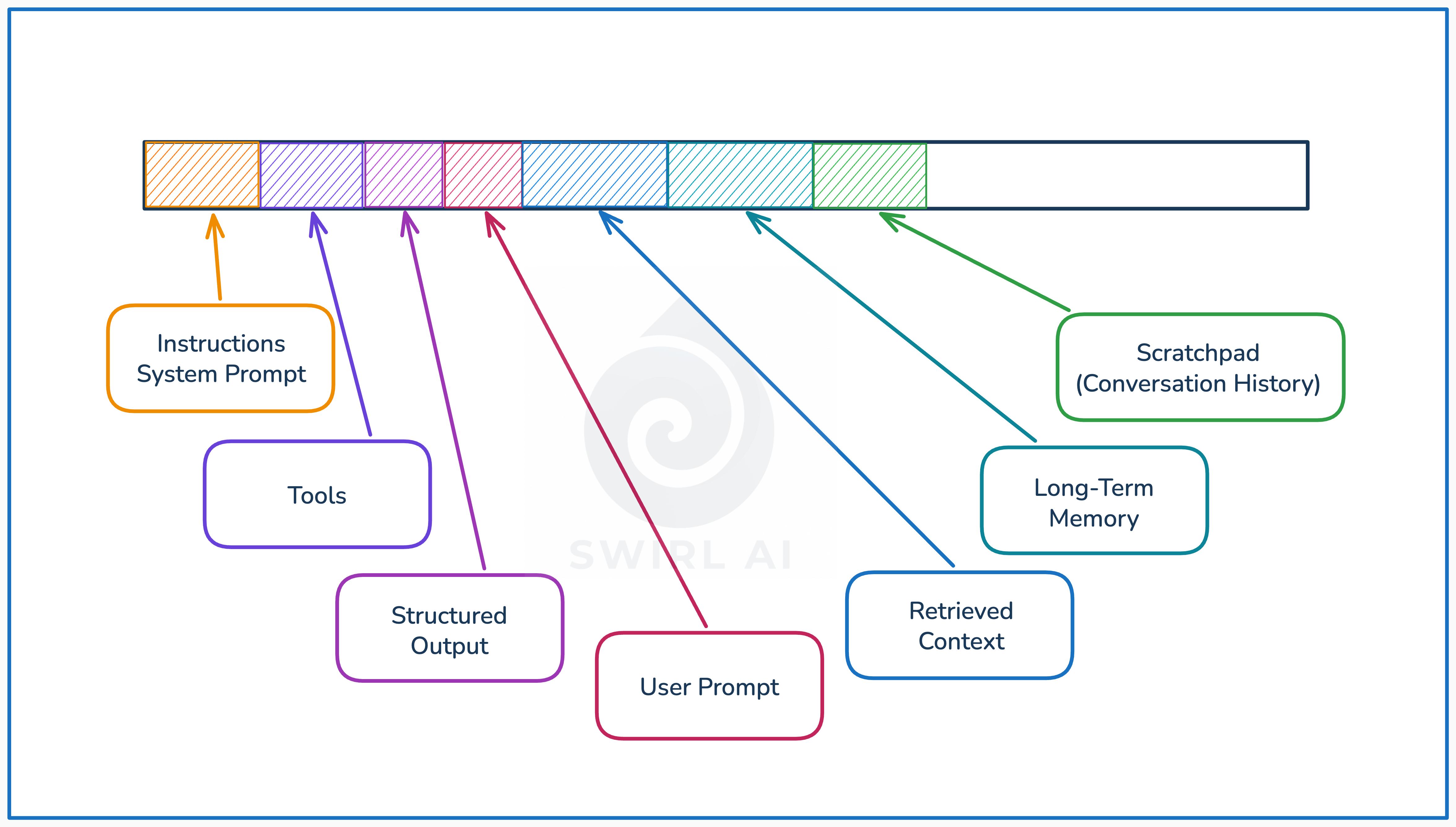
Several patterns have emerged for managing context effectively: progressive disclosure for controlling what loads and when, compression for shrinking accumulated history, routing for directing queries to the right source, evolved retrieval strategies for getting external knowledge on demand, and tool management for controlling the capability surface.
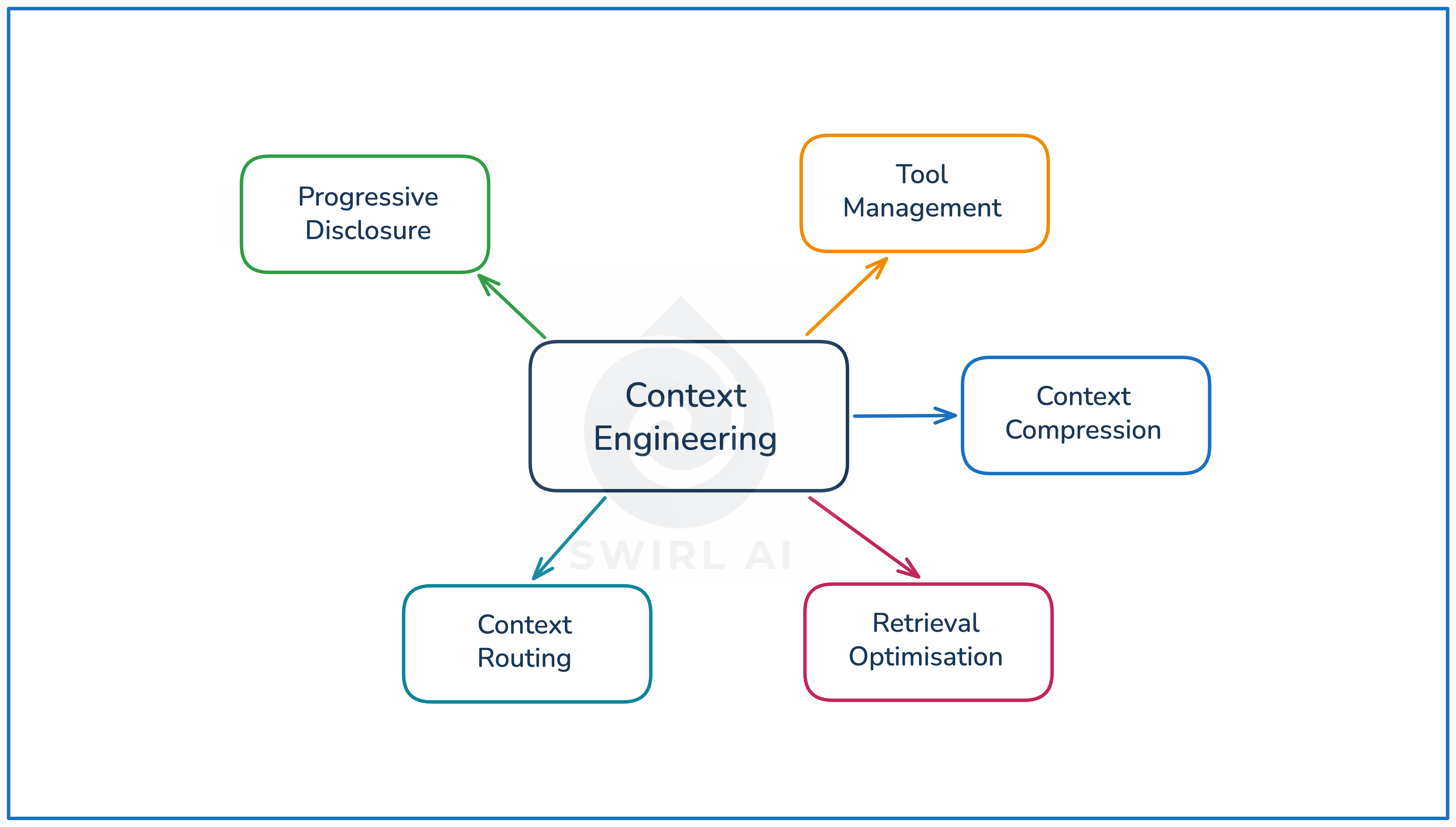
Each addresses a different dimension of the problem. The rest of this piece breaks them down.
I ran a live workshop on this topic where I walked through these patterns.
Pattern 1: Progressive Disclosure and Agent Skills
The problem
An agent that handles customer support, billing, refunds, and onboarding needs instructions for all four domains. Loading all instructions upfront wastes most of the context window on irrelevant guidance. The traditional alternative, spinning up separate specialised sub-agents, adds orchestration complexity, duplicates shared logic, and introduces latency from inter-agent communication. Neither scales well as the number of domains grows.
What the pattern does
Progressive disclosure loads information in tiers based on relevance. Discovery first (just names and descriptions), activation when relevant (full instructions), execution only during the task (scripts and reference materials).
Agent Skills are the standard implementation. I covered them in depth in my previous piece:

The short version: a skill is a markdown file with YAML frontmatter. The platform reads only the name and description at startup (~80 tokens median per skill). When the model determines a skill is relevant, the full instruction body loads (275 to 8,000 tokens). Supporting scripts and reference materials load only during execution. The format was released by Anthropic in December 2025 and adopted by OpenAI, Google, GitHub, and Cursor within weeks.
The most interesting application is agent identity management. Rather than routing queries to separate specialised sub-agents, a single agent assumes different identities on demand. At rest, it has a base identity. When a task activates a skill, the agent adopts that skill’s instructions, constraints, tone, and behavioral patterns. When the task completes, it returns to base. This is what Claude Code already does. It does not spin up a separate “PDF agent” and a “spreadsheet agent.” It is one agent that activates the relevant skill, shifting its identity to match.
Agent Skills are not only for coding agents. The pattern generalises to customer support, internal operations, research agents, and any system where agents need broad capability with focused execution. Because skills are plain English markdown, domain experts and team leads can configure agent behavior directly, without engineering expertise.
An interesting extension: agents that write their own skills. When an agent encounters a task it handles repeatedly, it can extract the pattern into a new skill file. Claude Code supports this through its skill-creator skill. The agent observes its own successful behavior, generalises it, and makes it available for future sessions. The quality of self-authored skills varies, but the direction closes the loop: humans write the initial skills, agents extend the library from experience.
Tradeoffs.
Accuracy: High with a small skill set, but degrades with 100+ as overlapping descriptions cause misactivation.
Latency: Low. Discovery data is pre-loaded, activation adds a file read, not an LLM call.
Token cost: Low at rest (all 17 Anthropic skills cost ~1,700 tokens at discovery), but accumulates during a session. The key unsolved question: when does an activated skill get deactivated? Without explicit pruning logic, multiple activated skills destroy the token advantage over time.
Maintainability: Easy per skill, harder at scale. 50+ skills with non-overlapping descriptions requires governance.
Reliability: Moderate. Skill selection errors compound downstream, and the entire approach depends on selection accuracy at the discovery layer.
Pattern 2: Context Compression
The problem
Every tool call, every observation, every reasoning step adds to the context. Each tool result can be hundreds or thousands of tokens: API responses, file contents, search results, error traces. Without intervention, the accumulated action history fills the context window and pushes out the system instructions, tool definitions, and early task context that the model actually needs to reason well.
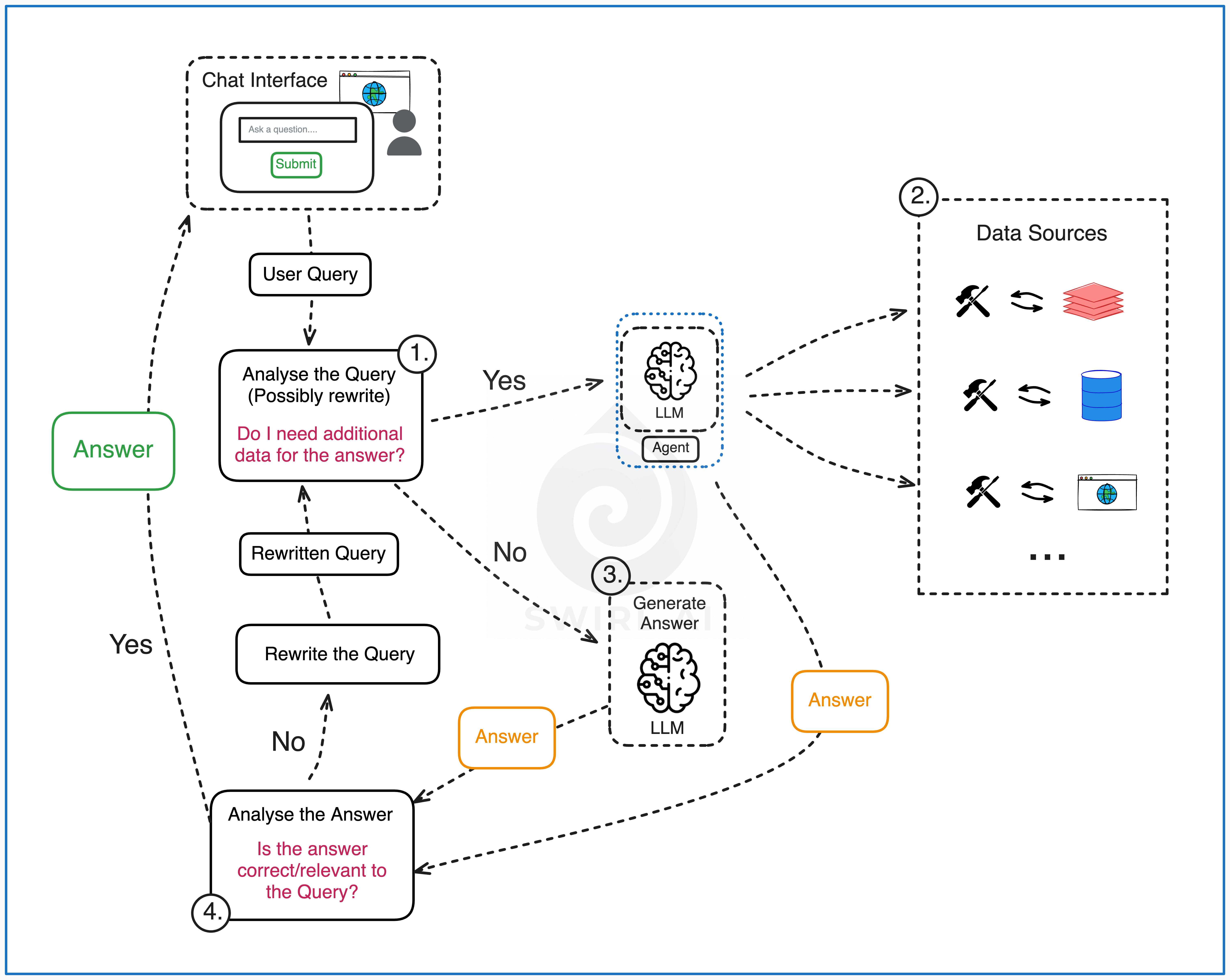
A good example to showcase this is a simple ReAct agent as displayed in the image below:
Construct a prompt from system instructions and available tools.
User query added to the initial prompt and passed to a LLM triggers the LLM to output either the final answer to the users query or plan additional actions via tool use in the environment.
If tool use is chosen, the tools get executed.
The results piped back to the initial prompt by appending them to the reasoning and action history.
Then we repeat the loop for N times or until the users query can be answered.
Each of the turns adds to the context as conversation history expands. This is extremely troublesome when the tools are retrieving large amounts of context.
What the pattern does
Context compression shrinks accumulated history while preserving the information the model needs. There are few approaches of how the compressions could be handled:
Keep only top N turns of interaction, discard the remaining.
Sliding window compression: keep top N turns unchanged, compress the remaining using LLMs.
Long-term Memory approach: keep top N turns unchanged, move the remaining history to a durable storage and retrieve only relevant actions on-demand.
The field has converged on sliding window plus summarisation hybrids as the dominant approach: keep recent turns in full detail, compress older context through LLM-based summarisation.
Manus adds two practical details. First, keep the most recent tool calls in raw format so the model maintains its "rhythm" and formatting style. Losing that rhythm leads to subtle degradation. Second, do not compress away error traces. When a tool call fails, leaving the error and stack trace in context helps the model avoid repeating the same mistake. This technique is well-established (libraries like Instructor use it for structured output retries), and it applies broadly to any agent that calls tools.
Tradeoffs.
Accuracy: Moderate. Summarisation preserves the gist but loses details, and any compression is lossy.
Latency: Moderate. Each compression step requires an LLM call. You can amortise this by compressing periodically instead of each new turn.
Token cost: Low in many cases when long running agents are involved.
Maintainability: Requires experimentation: what to keep raw, how many turns before compacting, what detail level in summaries.
Reliability: Moderate. Works well for long-horizon tasks, but poorly when critical early details get summarised away.
Learn these patterns hands-on in my End-to-end AI Engineering Bootcamp (3 days left to register before next cohort starts). Apply code LASTCHANCE15 for 15% off.
Pattern 3: Context Routing
The problem
A multi-domain agent has access to multiple knowledge bases, tool sets, and instruction sets. Loading all of them for every query wastes context and degrades accuracy. A billing question does not need the onboarding knowledge base. A technical support query does not need the refund policy.
What the pattern does
Context routing classifies the query and directs it to the right context source before anything enters the context window. Several approaches have emerged:
LLM-powered routing uses the model itself to classify the query and select the appropriate context source. More accurate than rule-based approaches, but adds latency and cost.
Hierarchical routing uses a lead agent to triage queries to specialised sub-agents, each with its own focused context window.
Rule-based routing uses keyword matching or pattern detection. Fast and predictable, but rigid and unreliable when queries don’t match expected patterns.
Hybrid routing combines multiple methods.
Tradeoffs.
Accuracy: High for LLM-based routing, moderate for rule-based. LLM routing understands nuance, rule-based misses anything outside expected patterns.
Latency: Varied. LLM routing adds an inference call before the main task. Rule-based is near-instant. Most production systems combine both.
Token cost: Savings come downstream: by loading only relevant context, you reduce tokens for the main inference.
Maintainability: Rule-based routing requires manual updates for new domains. LLM routing adapts automatically but is harder to debug when it misroutes.
Reliability: LLM routing can hallucinate routing decisions. Fallback to a human or default agent is necessary.
Pattern 4: Retrieval Evolution
The problem
Agents need knowledge that is not in their training data: company documents, product catalogs, policy updates, real-time data. The naive approach (retrieve similar text, stuff it into the prompt, generate) fails on complex queries. A question like “what themes emerge across this quarter’s customer feedback?” requires connecting information across multiple documents, something vector similarity search cannot do. A question where the first retrieval returns insufficient results needs a second attempt with a reformulated query, something a fixed pipeline cannot do.
What the pattern does
RAG has matured from fixed pipelines to agent-controlled retrieval loops. Three evolutions stand out.
I wrote about evolution of RAG architectures in one of my previous articles:

Agentic RAG puts retrieval under agent control. Instead of a fixed pipeline (query → vector search → inject → generate), the agent decides its own search strategy, can reformulate queries when results are insufficient, and iterates until confident. The retrieval loop replaces the retrieval pipeline.
Graph RAG adds relational reasoning. Standard vector search finds similar text but cannot connect entities across documents. Graph-based approaches build entity-relationship graphs over the corpus, enabling thematic and relational questions that require connecting information across multiple sources.
Self-RAG trains models to decide when to retrieve and to critique their own outputs. The model assesses whether it has enough information before answering, triggers retrieval only when needed, and evaluates the quality of retrieved results before using them.
The most advanced work combines all three:
Tradeoffs.
Accuracy: The strongest dimension. Agent-controlled retrieval can reformulate queries, try multiple strategies, and iterate until confident.
Latency: High. A single question might trigger three to five retrieval cycles.
Token cost: High. Each cycle adds retrieved chunks to context plus the agent’s reasoning about strategy. Cost scales with question complexity.
Maintainability: Moderate. Debugging “why did the agent choose this retrieval strategy?” is harder than debugging a fixed pipeline.
Reliability: Needs guardrails. Agentic RAG can over-retrieve on simple questions, so maximum retrieval rounds, confidence thresholds, and fallback to direct generation are essential.
Pattern 5: Tool and Capability Management
The problem
Agents need tools to interact with the world: APIs, databases, file systems, search engines. Each tool requires a JSON schema definition that the model reads to understand what the tool does and how to call it. A single complex schema (nested objects, enums, parameter descriptions) can consume 500+ tokens. Connect a few MCP servers and you might reach 90+ tool definitions, over 50,000 tokens of schemas before the model starts reasoning. This is not a theoretical concern. OpenAI recommends fewer than 20 tools per agent, with accuracy degrading past 10.
What the pattern does
MCP (Model Context Protocol) has become the standard for connecting agents to external tools. Originally released by Anthropic in November 2024, it is now governed by the Agentic AI Foundation under the Linux Foundation.
MCP solves the connection problem. The context cost problem remains unsolved.
You can read more about the protocol in one of my articles here:

Manus found a practical constraint: avoid dynamically adding or removing tools mid-iteration, because tool definitions sit near the front of the context, and any change invalidates the KV-cache for all subsequent actions.
Beyond raw context cost, tool management introduces several open problems:
Description quality. The model selects tools based on descriptions, but most MCP server authors write descriptions for humans, not models. Too vague and the model picks the wrong tool. Too verbose and you waste context on a single schema.
Tool overlap across MCP servers. Two different servers might offer similar capabilities (two search tools, two file readers). Without deduplication or preference logic, the model picks arbitrarily.
No versioning for tool contracts. When an MCP server updates its tool schemas, the agent has no way to know. Stale descriptions in cache cause silent failures.
Security surface scales with tool count. Each connected MCP server is an attack surface. Tool outputs can contain prompt injection attempts, and the more tools available, the larger the exposure.
Tradeoffs.
Accuracy: Depends entirely on description quality, which is unsolved.
Latency: Low for discovery, but changing tools mid-iteration invalidates the KV-cache, adding significant latency.
Token cost: The biggest hidden cost in many agent systems. A single complex JSON schema can consume 500+ tokens. 90 tools means 50K+ tokens before any user interaction.
Maintainability: MCP standardises the interface, but not description quality, schema conventions, or versioning.
Reliability: Moderate. Again, MCP standardises the interface but not the quality of the underlying tool. Each connected server expands the attack surface.
Putting It Together
These patterns are not alternatives. In a production agent system, you layer them: progressive disclosure and tool management define what can enter the context window, routing and compression manage what stays during execution, retrieval brings in external knowledge on demand, and evaluation measures whether any of it is working. Each layer addresses a different failure mode.
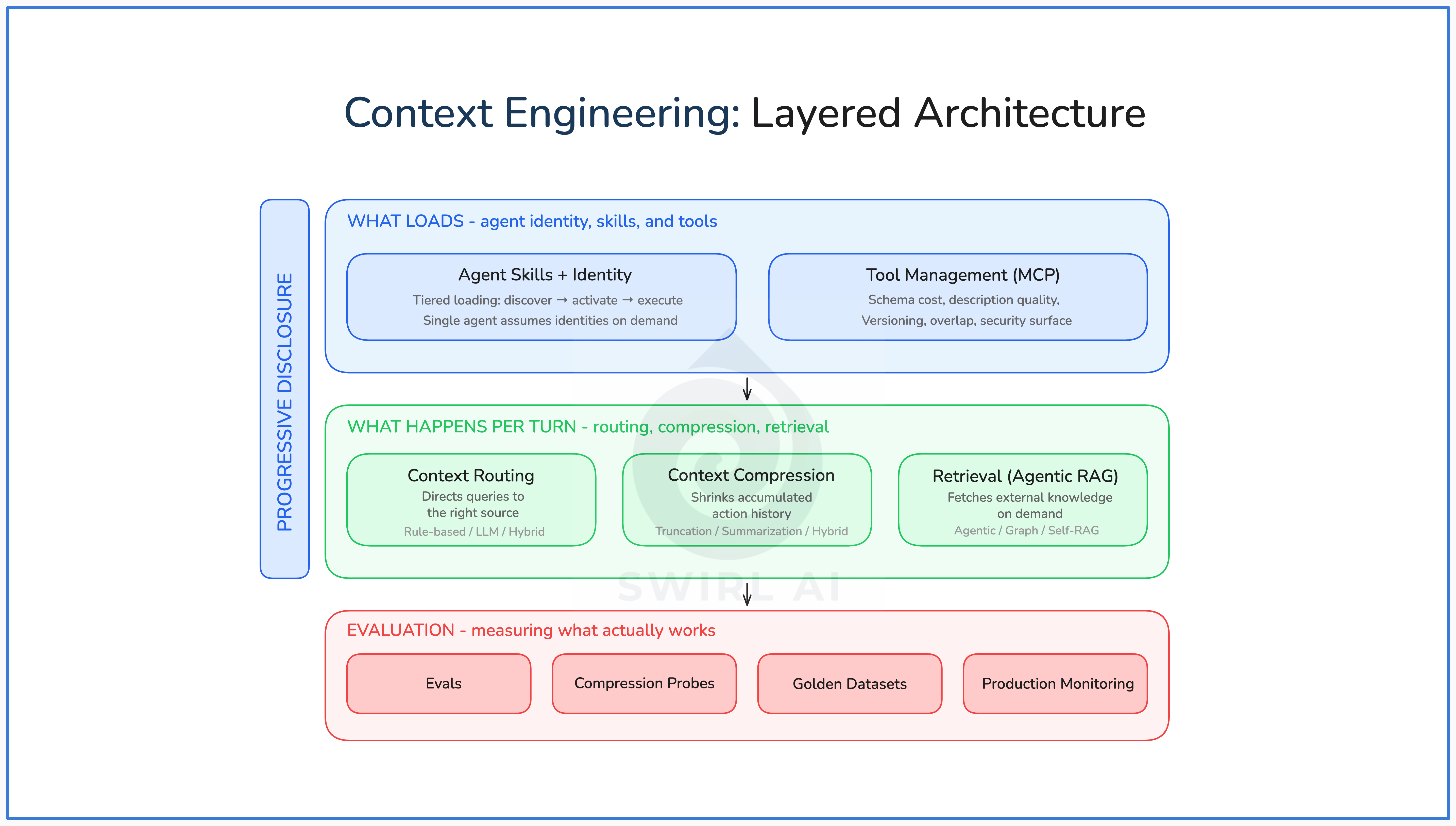
Where to Start
If your agents run long tasks, add compression first. Hybrid sliding window (keep the latest N turns raw, summarise older ones) is the most practical starting point, and probe-based evaluation will tell you whether your summaries are preserving what matters.
If your agents serve multiple domains, add routing. Even keyword-based rules cut context bloat before you invest in LLM-based classification.
If your agents connect to multiple MCP servers, audit the token cost. Count how many tokens your tool schemas consume before any user interaction. That number is usually higher than expected.
Hope you enjoyed this piece and hope to see you in the next one, cheers!
The layered separation here is exactly the right mental model. Most teams collapse context management into a single prompt engineering step and then wonder why agent behavior degrades under load or across long sessions. Breaking it into identity/persona, per-turn routing and compression, and a dedicated evaluation layer makes the whole system debuggable. Context engineering is becoming as critical as prompt engineering - maybe more so.
Progressive disclosure is the pattern I landed on too but I took longer to get there than I should have. The instinct is to load everything upfront.
Turns out that degrades performance on focused tasks because the model has to do more work to filter signal from noise before it even starts. The skill file approach from the first pattern maps to what I have been calling 'on-demand context loading' - the agent discovers what it needs, activates the relevant context, runs the task. The compression pattern in step two is where most implementations I have seen break down. Summarizing older context with the same model that generated it introduces bias. What model are you using for the compression step, and does it matter?